kürzlich bin ix im netz darüber gestolpert, dass inger nilsson, die in den 60er jahren pipi langstrumpf spielte, 2009 in der schwedischen version von „Ich bin ein Star – Holt mich hier raus!“ mitgespielt hat („Kändisdjungeln“).
dann eben stefanie powers in der glaserei mit einer katze gesehen und kurz darauf gesehen, dass stefanie powers 2011 in der britischen version des australischen dschungels eine folge lang mitgespielt hat.
ich bin sicher mit einem nachmittag recherche fände ich mindestens 20 fernsehhelden der 80er, die zwischenzeitlich in den dschungel gegangen sind.
seitdem quote.fm RSS-feeds einzelner nutzer anbietet (hier die ode von martin weigert auf die quote.fm-RSS-feeds) habe ich ein paar quote.fm-nutzer in meinem RSS-dings (früher google reader, jetzt auf meiner eigenen fever installation) aboniert. und lieben gerlernt. das liegt zum einen natürlich an den jeweiligen nutzern. abonniert hatte ich bisher:
aber ich habe mich schon immer gefragt, warum bietet mir quote.fm nicht alle leute denen ich auf quote.fm folge als RSS-feed an? warum sollte ich alle 140 leute denen ich folge einzeln abonnieren? kürzlich fiel mir dann beim duschen ein, dass das ja nicht so schwer sein könnte sowas zu scripten.
die quote.fm-API abfragen nach denen denen ich folge (quote.fm/api/user/listFollowings?username=ix), aus dieser liste feed-URLs konstruieren und diese feed-liste SimplePie zum frass vorwerfen und neu rausschreiben. hier ist das ergebnis:
That means: Philipp, Marcel, Flo and I are saying our good-byes and sometime in the (quite near) future elbdudler will take over and hopefully build this thing here into something that you guys will appreciate.
hoffentlich wird das nicht so schlimm wie es sich anhört, aber noch funktioniert dieses quote.fm-dings ja noch.
* * *
das script hat als abhängigkeit lediglich SimplePie (download) und einen cache-ordner auf der gleichen ebene in der das script liegt:
das script ist nicht elegant gescriptet, funktioniert aber. fehler schliesse ich wie immer ausdrücklich nicht aus.
eigentlich sollen es 3 kleine zwiebeln sein, ich habe aber 3 mittelgrosse zwiebeln in halbe ringe geschnitten und zusammen mit (leider nur) 2 kleinen in ringe geschnittenen spitzpaprika in 90 millilitern olivenöl 10 minuten an- und weichgebraten.
danach habe ich 2 esslöffel tomatenmark, 2 EL koriandersamen, ein teelöffel sechuan pfeffer (ottolenghi schlägt rosa pfeffer vor), etwas zucker, salz und pfeffer und 100 gramm korinthen nochmal 2 minuten mitgebraten.
400 gramm mittelgroben bulgur habe ich wie beim risotto auch nochmal ein bisschen glasiggebraten und dann mit einem halben liter wasser abgelöscht und aufgekocht. das ganze dann 20 minuten ohne hitze quellen lassen, petersilie (statt schnittlauch), fertig. mit einem klecks jogurt schmeckts besser als ohne.
vor ein paar tagen veröffentlichte gabe weatherhead einen artikel mit dem titel „TweetFeeder Script: From Twitter to RSS“. gabe weatherhead hat sich ein script gebastelt das ein paar twitter accounts sporadisch nach links die keine bilder sind überprüft und diese links dann in eines seiner pinboard-accounts schreibt. der artikel hätte also genauer „From Twitter to Pinboard“ heissen müssen.
gestern bookmarkte sascha lobo den (neuen?) dienst twitter-rss.com, der genau das tut was er im domainnamen ankündigt: er macht beliebige twitter-konten per RSS abonnierbar.
in den letzten monaten habe ich mich auch immer wieder mit dem thmea twitter und RSS beschäftigt, was daran liegt, dass twitter sich zu meinem bedauern mehr und mehr einigelt und abschottet. im september wurden die möglichkeiten per ifttt daten aus twitter rauszuholen von twitter empfindlich eingeschränkt und seit diesem frühjahr arbeitet twitter daran die relativ offene API der version 1.0 mit der version 1.1 zu ersetzen, die für jede kleinigkeit authentifizierung benötigt und die eh noch versteckt vorhandenen twitter-RSS-feeds beseitigt.
RSS ist und bleibt mein favorisierter weg daten zu verarbeiten, sei es meine rückseite zu bestücken, meine monatlichen twitter-favoriten-listenautomatisch zu erzeugen oder per RSS-reader den überblick zu behalten. deshalb habe ich mir meinen eigenen php-basierten twitter-zu-RSS-übersetzer, bzw. proxy gebaut.
ein eigener, selbstgescripteter und selbstgehosteter übersetzer hat ein paar vorteile gegenüber lösungen wie twitter-rss.com:
ich mache mich nicht von einem weiteren drittanbieter abhängig
ich kann bestimmen wie die ausgabe aussieht oder formatiert ist
ich kann alles selbst steuern und erweitern
der beste teil ist natürlich: wenn viele dieses oder andere scripte nutzen um twitter-ströme auszulesen, kann twitter nicht einfach die schotten dicht machen, wie bei ifttt. ifttt ein paar berechtigungen zu entziehen ist einfach, den selbstgehosteten scripten oder webapps von hunderten oder tausenden nutzern rechte zu entziehen ist schon sehr viel schwerer.
* * *
mit meinem script lese ich den twitter-strom meines eigenen accounts aus. technisch passiert nichts aufregendes:
ich authentifiziere mich mit meiner eigens definierten twitter-app, bzw. deren schlüsseln
twitter liefert mir json-codiert die letzten 20 meiner tweets, exklusive retweets
aus der json-antwort baue ich mir meinen RSS-feed zusammen und gebe ihn aus
wenn ich die anfrage etwas anpasse kann ich auf diese art und weise beispielsweise auch meine twitter-favoriten auslesen und als RSS ausgeben:
mit einer twitter-such-anfrage sollte das ähnlich klappen, das habe ich aber noch nicht ausprobiert.
als grössten vorteil sehe ich, dass ich die RSS-ausgabe selbst steuern und formatieren kann. das script wandelt bespielsweise die verkackten t.co-links die die twitter-api zurückliefert in klartext-adressen um, hashtags in suchlinks und twitter-namen in profillinks. der titel eines RSS-items liefert den rohen volltext eines tweets, die description des RSS-items liefert hingegen das offizielle embed-format eines tweets zurück, also nach diesem schema:
das ausgabeformat lässt sich bei bedarf natürlich leicht anpassen. in einem tweet eingebettete bilder bette ich per HTML in die tweet-description ein. das ist nicht besonders schön, aber effektiv (demo):
<?php
/*
// generiert einen rss-feed eines nutzers ohne seine (nativen) retweets
//
*/
header('Content-Type: text/html; charset=utf-8');
require 'tmhOAuth/tmhOAuth.php';
require 'tmhOAuth/tmhUtilities.php';
include('feed_generator/FeedWriter.php'); // include the feed generator feedwriter file
// app: hier wirres.net
// eigene app keys gibts hier: https://dev.twitter.com/apps/new
$tmhOAuth = new tmhOAuth(array(
'consumer_key' => 'xxx',
'consumer_secret' => 'xxx',
'user_token' => 'xxx',
'user_secret' => 'xxx',
));
if ($tmhOAuth->response['code'] == 200) {
$data = json_decode($tmhOAuth->response['response'],1);
$feed = new FeedWriter(RSS2);
// $feed->setTitle('@'.$user.'s Twitter Favs'); // set your title
$feed->setTitle('@'.$user.'s Twitter Timeline'); // set your title
$feed->setLink('http://'.$_SERVER['SERVER_NAME'].$_SERVER['SCRIPT_NAME']); // set the url to the feed page you're generating
// $feed->setChannelElement('updated', date(DATE_ATOM , time()));
// $feed->setChannelElement('author', $user_name); // set the author name
$feed->setChannelElement('description', $user_name.'s tweets'); // set the description
// iterate through the response to add items to the feed
if ( is_array( $data ) ) {
foreach($data as $entry){
$post_date_gmt = strtotime( $entry['created_at'] );
$post_date_gmt = gmdate( 'Y-m-d H:i:s', $post_date_gmt );
$post_date = gmdate( 'd.m.Y H:i', strtotime( $entry['created_at'] ));
$tweetlink = 'http://twitter.com/'.$user.'/status/'.$entry['id_str'];
// hashtags zu kategorien
// $item->addElement('category', $tags);
foreach ( $tags as $tag ) {
$item->addElement('category', $tag);
}
$feed->addItem($item);
}
// that's it... don't echo anything else, just call this method
$feed->genarateFeed();
} else {
// return NULL;
}
}
* * *
das alles ist natürlich lange nicht perfekt. der universal feed generator generiert derzeit beispielsweise keine mehrfachen RSS-kategorien, so dass bei mehreren hashtags eines tweets immer nur der letzte als RSS-kategorie im RSS-feed landet. ich hoffe das dieser feed-generator das künftig besser erledigt. caching wäre irgendwann auch keine schlechte idee, um die twitter API nicht über gebühr zu strapazieren. eine zentrale konfiguration und eine flexibilisierung, so dass ich mir alle möglichen feeds mit dem script erzeugen kann, nicht nur twitter-favoriten und die eigenen tweets.
vor 6 tagen habe ich von der telekom einen newsletter mit „medieninformation“ bekommen. diesen newsletter bekomme ich seit ein paar monaten aus gründen die mir unbekannt sind. dadrin stand unter anderem:
Die De-Mail setzt sich weiter durch. Bereits mehr als hundert Großkunden möchten ihre Vorteile nutzen, zeitraubende Arbeitsschritte sparen und im Endeffekt den bundesdeutschen Bürgerinnen und Bürgern das Leben bequemer machen. Den Weg dorthin beschreiten sowohl Städte und Kommunen wie Düsseldorf und Bonn als auch beispielsweise die Allianz Deutschland AG, die LVM Versicherung, TARGOBANK sowie die Volks- und Raiffeisenbanken im nord- und westdeutschen Raum.
Der FC Bayern München hatte sich bereits für die De-Mail entschieden, jetzt setzt auch der Deutsche Fußball Bund (DFB) darauf.
dass sich die de-mail durchsetzt hatte ich bisher nicht mitbekommen. vielen dank als für die information, man lernt ja nie aus. ich habe mir dann mal die info-seite der telekom zur de-mail angesehen. dort erfährt man beispielsweise:
Für De-Mail gelten jedoch ganz klare gesetzliche Vorgaben, die die Nachweisbarkeit regeln. Dazu gehört vor allem, dass sich alle Teilnehmer klar identifizieren müssen.
in einem video erklärt mir ein extrem schlechter schauspieler, dass das internet nicht wirklich sicher sei: „da gibts so viele, die sich mit falschen identitäten ins internet schleichen. […] und was machen die? die greifen die privaten daten ab, melden sich dann unter falschen namen an und sagen »ich bin deine bank, überweis mir 150 euro.«“ dabei wackelt er die ganze zeit mit dem kopf und lässt sich hin und wieder von kindern in seinem redefluss unterbrechen.
ich habe vor sechs tagen die versender der telekom „medieninformation“ gefragt, ob ihnen die grandiose ironie ihrer de-mail-werbekampagne bewusst sei. mit gefakten menschen namenlosen schauspielern für ein produkt zu werben, mit dem identitätdienbstahl oder vorgaukelung fremder identitäten ausgeschlossen werden sollen. gegen lügen anwerben mit leuten, die so tun als seien sie etwas, was sie gar nicht sind. für authentizität werben und dafür schauspieler anstellen. grandios.
wenn werbung so offensichtlich lügt und sich selbst widerspricht ist das irgendwie eine erfrischend ironische art der meta-kommunikation durch die blume. möglicherweise also eine art versteckter botschaft der marketing-abteilung an die menschen im lande: „sorry, unsere chefs wollten dass wir dieses nutzlose und überteuerte witzprodukt bewerben und wir konnten leider nicht nein sagen“. kann natürlich auch ein coup der werbeagentur sein, die noch eine rechnung mit der telekom offen hatte und sich so, dank der merkbefreitheit des telekom-managements, bei der telekom hintenrum rächen wollte.
eigentlich finde ich diese art der werbung ganz grossartig, auf eine meta-hinterfotzige art und weise ehrlich und defensiv. das ist wie hackfleischwerbung die von einem dressierten pferd gesprochen wird („100% rind vertrauen sie mir!“). oder werbung für milchprodukte mit offen laktose intoleranten menschen („i’m loving it, the farting“). werbung für legale downloads mit transportablen gefängniszellen. wurstwerbung mit niki lauda.
* * *
die frage ob die schauspieler in der werbung wirklich de-mailer sind, hat mir die telekom noch nicht beantwortet. auch meine frage, ob die tatsache dass der FC bayern münchen de-mail vielleicht deshalb benutzt, weil er werbepartner der telekom ist und nicht weil er einen bedarf oder nutzen davon hat. ich finde das enttäuschend bis unprofessionell. erst flutet man mich ungefragt mit informationen und wenn ich mal auf den werbemüll reagiere ist plötzlich niemand zuständig.
[nachtrag 18.03.2013]
eben mit einem sprecher der telekom telefoniert und fast alle meine fragen beantwortet bekommen, bis auf die, zu denen er keine ausskunft geben durfte oder wollte. fragen deren antworten den datenschutz verletzen, konnte er natürlich auch nicht beantworten. ebenso blieben fragen offen, zu denen die telekom aus wettbewerbsgründen nichts sagt. aber das gespräch war trotzdem sehr informativ und professionell. ich versuche in den nächsten tagen nochmal etwas konkreteres dazu nachzutragen.
* * *
auf eienm anderen bild auf der kampagnen-site ist jemand abgebildet der in der gebrüder grimm bibliothek der humbold universität berlin sitzt und ein schild hält auf dem steht:
Ich bin De-Mailer.
Damit ich meine Hausarbeit noch kurz vor knapp verschicken kann. Aber sicher.
die Liste der partner (privatkunden/wer ist schon dabei?) umfasst neben ein paar versicherungen, banken, einen fertighaushersteller, einen it-dienstleister und die lohndirekt gmbh. auf der seite steht, das seien „alle De-Mail Partner“. ich frage mich, an wen will der unbekannte de-mailer aus der uni seine hausarbeit schicken? an die ergo-versicherung? an die targo-bank? vor allem: warum?
Im SPIEGEL gab es kürzlich eine interessante Grafik zu dem ersten Twittersturm, der die Sexismusdebatte in Gang setzte und vielen nun als Beweis für die Bedeutung dieser neuen sozialen Bewegung gilt. Von den 80.000 Tweets, die in den ersten fünf Tagen abgesetzt wurden, waren 30.000 Retweets, also Weiterleitungen bereits gesendeter Mitteilungen. Zu den am meisten weiterverschickten Nachrichten gehörte der Spruch: "Meine Frau wollte auch etwas zu #aufschrei twittern. Das W-Lan reicht aber nicht bis in die Küche."
in der kolumne beleuchtet er einen interessanten aspekt der #aufschrei-debatte, die fleischhauer „die Sexismusdebatte“ nennt. er nennt das internet eine „Parallelwelt“, in der bekanntheit eine relative grösse sei:
Hier zählen 7000 Follower auf Twitter allemal mehr als 4,5 Millionen Zuschauer an einem Sonntagabend in der ARD. So funktioniert der Hinweis auf das Netz auch in jeder Redaktionskonferenz als Bedeutungsnachweis ersten Ranges. Mit dem Satz, dass dies aber in den sozialen Medien gerade heftig diskutiert werde, lässt sich noch dem abseitigsten Thema Dringlichkeit verleihen.
das ist natürlich etwas ganz neues. in der alten paralellwelt, die der asozialen klassischen medien, bestanden bedeutungsnachweise noch darin, dass andere zeitungen, bzw. ein paar oberchecker die für diese zeitungen schrieben, über ein thema berichteten. dreissig, vierzig leute, vielleicht auch 100, die die oberen plätzen der führenden tageszeitungen befüllen durften, genügten als bedeutungsnachweis in redaktionskonferenzen und parlamenten.
dass mit presseausweisen legitimierte oberchecker jetzt nicht mehr die einzigen sind, die diese debatten auslösen, führen und mit argumenten füllen können, scheint fleischhauer sehr zu bedauern. man hört ihn beim lesen seiner kolumne beinahe murmeln, „da könnte ja jeder kommen“.
die geringschätzung von normalsterblichen menschen, diesen figuren, die früher lediglich abonements bezahlten und werbung in relevanten medien betrachteten, zieht sich konsequent durch fleischhauers argumentation. warum dürfen diese unqualifizierten menschen überall mitreden? wie soll diese person, die gerade mal 7000 follower hat (wie fleischhauer auch), irgendwie für einen führenden journalisten wie fleischhauer relevant sein, der schliesslich schon das eine oder andere mal mehr in talkshows mit millionnen zusehern aufgetreten ist?
ganz besonders dumm finde ich jan fleischhauers steile these, dass die beteiligung „an den in Rede stehenden Debatten“ (im internet) so gering sei, dass „die Zahl oft nicht einmal ausreicht, um den bei herkömmlichen Protesten beliebten Platz vor dem Brandenburger Tor zu füllen“. das ist bei den debatten in talkshows oder zeitungen oder dem bundestag natürlich ganz anders. wenn so eine talkrunde oder redaktion auf den pariser platz tritt, wirkt das ruck zuck wie ein ostermarsch zu zeiten des NATO doppelbeschlusses.
aber eigentlich wollte ich etwas ganz anderes sagen. ich kann mir sehr gut denken welche anstrengungen es bedeutet, wöchentlich eine kolumne zu schreiben und sich stundenlang meinungen aus der nase zu ziehen und sachen die man vom hörensagen im laufe der woche mitbekommen hat entsprechend zu verwursten. bei meinungsstarken stücken, bleibt für recherche natürlich wenig zeit. wenn renomierte blätter wie die augsburger algemeine, die waltroper-zeitung, das pc-magazin, die mainpost, spiegel-online, die taz oder die dpa einen tweet als einen der am häufigsten¹ retweeten beiträge zur #aufschrei-debatte zitieren (ohne den tweet zu verlinken²), dann kann fleischhauer — der sich „Journalist und Autor“ nennt — das natürlich auch. einfach abschreiben, einen bindestrich zwischen w und lan einfügen, keinen link setzen und auf gar keinen fall erwähnen, dass der tweet von gallenbitter gerade mal 201 retweets erzielt hat (stand 12.03.2013), weil sich das nicht gut neben der zahl von „30.000 Retweets“ machen würde:
Mein Frau wollte auch etwas zu #aufschrei twittern. Das WLAN reicht aber nicht bis in die Küche.
das war ein bisschen voreilig. denn entgegen den eigenen ankündigungen hat twitter nun doch noch nicht der API 1.0 am 5. märz das licht ausgeschaltet, sondern führt vor der endgültigen abschaltung irgendwann (twitter legt sich nicht auf ein datum fest) erst noch „blackout tests“ durch, twitter dazu:
What dates should I be aware of?
We will perform the first of what we call "blackout tests" for API v1 on March 5th, 2013. We will not be permanently shutting off API v1 on this date. […]
What are blackout tests?
The blackout tests, which will take place on different days of the week and at varying times of day, are meant to help you better understand the impact the retirement will have on your applications and users. API methods will temporarily respond to requests as if the retirement has already happened -- with an HTTP 410 Gone.
On March 5th, 2013, from around 9:00am to 10:00am PST, we'll perform the first of these tests, limited only to unauthenticated requests. All unauthenticated requests during that time window will be responded to with a HTTP 410 Gone. Be sure to follow @twitterapi to receive notices before, during, and after the blackout test.
sollten die pläne für die abschaltung der API so umgesetzt werden wie geplant, bedeutete das (unter vielen anderem) für wordpress-plugins wie blackbird pie das ende. blackbird pie erlaubt es blogger in wordpress entweder mit einem shortcode oder einer twitter-URL einen tweet einzubetten:
diese anfrage liefert informationen zum twitter-avatar des benutzers, hintergrundbild, verwendeten farben und dem twitter-client zurück
daraus bastelt blackbird pie dann einen tweet in html
wordpress kann das seit ein paar versionen auch nativ, also ohne den blackbird-pie-plugin. aus einer einzelnen zeile mit einer twitter-URL baut wordpress soetwas:
mit der twitter API 1.1 ändert sich an den API-abfragen ein entscheidendes detail. die anfrage muss authentifiziert sein. einfach, könnte man denken, jeder hat ja ein twitter account, dann authentifiziere ich mich halt. nur leider fragt man ja nicht selbst die API ab, sondern wordpress oder die web-app die man zum ins internet schreiben benutzt. damit die sich authentifizieren kann, muss man erst mit seinem twitter account eine twitter app erstellen:
und wenn man den namen der app, die beschreibung und website mit der man die app nutzen will eingegeben hat, die nutzungsbedingungen abgenicjt hat und ein captcha gelöst hat,
kann man sich die „OAuth settings“ erstellen lassen. die bestehen aus einem „Consumer key“ und einem „Consumer secret“
ausserdem muss man dann ein „oAuth token“ erstellen, dass aus einem „Access token“ und einem „Access token secret“ besteht.
mit diesen daten kann sich dann die webapp (das blog, der plugin) gegenüber twitter authentifizieren. einige wordpress-twitter-plugins oder webapps können das bereits und mit einer php oAuth-library kann man das mit ein paar PHP kenntnissen auch selbst nachrüsten. ich habe das in meine blackbird pie implementierung die ich für meine monatlichen twitter-lieblinge benutze kürzlich gemacht. meine monatlichen twitterlieblinge werden also noch eine weile so aussehen können wie sie aussehen (ich nutze aber auch kein wordpress hier). für den blackbird-pie-plugin selbst hat das noch niemand gemacht, der wurde seit über einem jahr nicht mehr aktualisiert.
es gibt auch noch eine weitere hürde die twitter seinen nutzern (bzw. entwicklern) in den weg gelegt hat: die twitter „Developer Display Requirements“.
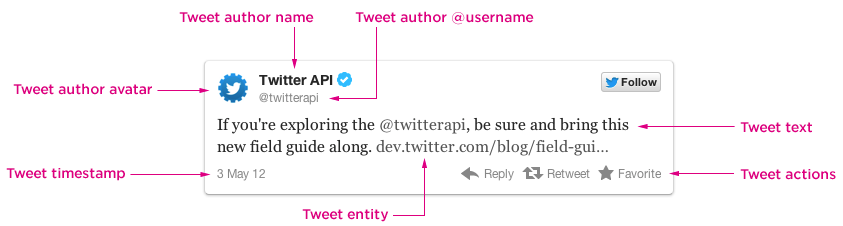
in den „Display Requirements“ ist bestimmt wie ein tweet auszusehen hat. zum beispiel soll immer das profilbild angezeigt werden, der benutzername muss zuerst angezeigt werden, dann der @twittername. blackbird pie macht das andersrum, so wie twitter das auch vor einigen jahren noch gemacht hat. ausserdem findet twitter, dass der benutzername über dem eigentlichen tweet angezeigt werden muss. das macht blackbird pie auch umgekehrt. blackbird pie tweets wie der ganz oben, sind also aus der sicht von twitter illegal. theoretisch kann das dazu führen, dass twitter die app und die authentifizierung sperrt und man dann wieder auf dem trockenen sitzt.
frank westphal hat aus furcht vor konsequenzen die darstellung von tweets auf rivva entsprechend angepasst. das sieht jetzt ziemlich verhunzt aus. zum beispiel: rivva.de/188861715
andererseits kann man das auch verstehen. twitter will kontrolle über die darstellung von tweets haben und sieht mit dem kontrollierten zugang zum API eine möglichkeit dazu. völlig absurd ist aber die verrammelung des oEmbed-zugangspunktes. hier fragen wordpress und andere systeme ja nach der von twitter sanktionierten, geforderten und geförderten tweet-darstellung. wordpress merkt: oh ich habe hier einen tweet und fragt twitter: „wie soll ich den darstellen?“. das geht per oEmbed idiotensicher und einfach — ohne jede weitere konfiguration die der nutzer vornehmen muss.
immerhin scheint twitter hier ein einsehen zu haben. in einem ticket zur drohenden verrammelung des twitter-oEmbed-zugangs berichtet ein wordpress-entwickler, dass twitter einen rückziehen beim thema authentifiziertes oEmbed zu machen scheint:
Initial response from Twitter is that "the endpoint will continue to operate unauthenticated, as-is the spirit of oEmbed." Still trying to confirm whether that means 1.0's oEmbed endpoint will remain in operation past the 1.0 shutdown, if 1.1's oEmbed endpoint will be changed to be entirely unauthenticated, or both. Either way, we're in the clear in terms of not needing to implement something new.
dieses innehalten beim thema oEmbed ist einerseits beruhigend, andererseits erschreckend, wie kurzsichtig und rücksichtslos twitter beim durchpeitschen seiner API 1.1 vorgeht. benutzerfreundlich und innovationsfördernd ist das alles nicht.
immerhin gibts ja noch die methode gröner lieblingstweets zu verbloggen. mit screenshots.