nachrichten sind flüsse, keine seen

ich bilde mir gerade ein, einen bauplan der zukunft des publizierens vor augen zu haben. an erster stelle steht die erkenntinis, dass das publizieren — oder genauer das lesen — sich bereits jetzt zum grossen teil in strömen, flüssen oder streams abspielt. richard macmanus schreibt:
2. The Web Is Moving From Pages to Streams
[…] Web pages and blog posts are still being published, but this new wave of tools is looking for ways to deliver content in a more flexible way.
er verweist auf anil dash, der schrob „Stop Publishing Web Pages“:
Most users on the web spend most of their time in apps. The most popular of those apps, like Facebook, Twitter, Gmail, Tumblr and others, are primarily focused on a single, simple stream that offers a river of news which users can easily scroll through, skim over, and click on to read in more depth.
Most media companies on the web spend all of their effort putting content into content management systems which publish pages. These pages work essentially the same way that pages have worked since the beginning of the web, with a single article or post living at a particular address, and then tons of navigation and cruft (and, usually, advertisements) surrounding that article.
Users have decided they want streams, but most media companies are insisting on publishing more and more pages. And the systems which publish the web are designed to keep making pages, not to make customized streams.
It's time to stop publishing web pages.
da ist was dran, ich konsumiere mein medienmenü in der tat vornehmlich in strömen: im google reader rauschen hunderte artikel aus derzeit 1069 abonnements an mir vorbei, die ich anders auch gar nicht verarbeiten könnte als in einem langen endlosen strom, dessen inhalt ich mit j/k-tastennavigation lese, oder überspringe. artikel die ich nicht gleich lesen möchte packe ich in meinen instapaper-strom, artikel die ich verarbeiten oder verlinken möchte in meinen pinboard-strom. manchmal lese ich in meinem quote.fm-strom, auf dem handy laufen meine twitter-, facebook- und google-reader-ströme in flipboard, wo ich sie ebenfalls in fliessender form konsumiere: beinahe alle inhalte die ich wahrnehme, konsumiere ich in irgendwelchen anwendungen die als unendlicher strom organisiert sind.
und ich glaube das ist die form, in der die meisten menschen online artikel oder neuigkeiten konsumieren werden — auch weil es dem althergebrachten medienkosum gar nicht so unähnlich ist; ist eine zeitschrift nicht auch ein langer fluss von artikeln, den wir am stück oder mit pausen oder mit sprüngen verarbeiten?
allerdings stimme ich anil dashs schlussfolgerung, keine webseiten mehr zu publizieren, nicht zu. was man nicht mehr tun sollte, ist webseiten zu veröffentlichen, die nicht mit modernen nachrichtenstromanwendungen kompatibel sind. und das fängt damit an, dass websites die keinen volltext-RSS-feed anbieten und damit mehr oder weniger inkompatibel zu den modernen lesegewohnheiten sind, einfach keine aufmerksamkeit mehr bekommen — oder mit gewalt in die leserströme gequetscht werden, beispielsweise mit anwendungen wie instapaper, pocket, read it later oder anderen scrapern, die die inhalte einfach von den webseiten abziehen.
so könnte man statt „It's time to stop publishing web pages“ vielleicht besser sagen „stop fighting the streams“. warum die neuen nachrichtenkonsumformen bekämpfen, wenn man sie zu seinem eignen vorteil nutzen kann?
„ja aber!“ höre ich aus den reihen der verleger und RSS-feed-kürzer rufen. ja aber was ist mit unserer werbung? wir brauchen pageviews! wir wollen dass unsere inhalte nach unseren regeln, nicht nach den benutzerwünschen konsumiert werden!
das mit den eigenen regeln sollte man auf dauer lernen zu vergessen und das mit den pageviews auch. und zur werbung: was spricht denn dagegen werbung in den inhalten einzubetten? ein bild, ein bisschen text, einen link — jeder VHS-HTML-kurs-absolvent kann das in einen RSS-artikel einbetten. wahrscheinlich sogar meine oma.
ein RSS-volltext-feed bietet bereits alle technischen möglichkeiten die für die zukunft des publizierens nötig ist. ich kenne auch jemanden der das seit jahren ziemlich erfolgreich macht: peter turi2.
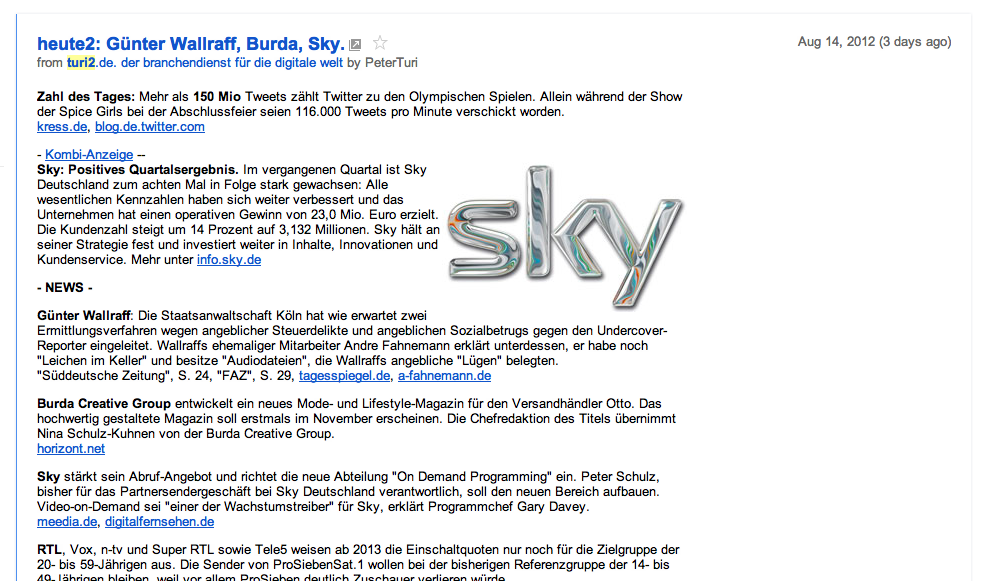
seine news-häppchen kommen bei mir im RSS-strom mit eingebetteter werbung an. so ein RSS-element beinhaltet alles wichtige: den autor, das veröffentlichungsdatum, einen link zur originalquelle, das gesamte HTML des artikels — lediglich das nutzlose drumherum wie die seitennavigation, der seitenleistentand und das widget-gedöns fehlt. theoretisch könnte der artikel auch noch mit einem ivw- oder vg-wort-pixel ausgestattet werden um die page-views artikel-ansichten zu erfassen und den scheiss zu vermarkten.
meine praxis sieht seit vielen jahren so aus: ich lese auf irgendeinem gerät in irgendwelchen streams, bevorzugt und meisten google-reader-basiert, und wenn ich etwas über den kontext des artikels erfahren möchte, besuche ich die originalseite: dort finde ich kommentare, im besten falle backlinks oder reaktionen ähnlich wie bei rivva.
mir ist tatsächlich egal ob mein artikel im google reader, auf flipboard oder sonstwo gelesen wird. ich hätte auch nichts dagegen, wenn meine artikel im volltext auf facebook oder twitter oder eben da eingebettet würden, wo sie sich optimal lesen lassen und zum leser kommen, statt vom leser zu verlangen, dass er zu einem kommt. solange alle basisinformationen wie mein name, ein link zum original, das veröffentlichungsdatum bestehen bleiben und der volltext und die anhänge korrekt dargestellt werden. gut wäre auch, wenn sich änderunegn am original auch am eingebetteten text auswirken würden. mit RSS funktioniert das ja seit jahren prima. aber vielleicht kann das auch noch besser funktionieren?
dave winer geht das natürlich wieder mal aus der technischen perspektive an und plädiert für die interoperabilität von content management systemen:
Let me enter the URL of something I write in my own space, and have it appear here as a first class citizen. Indistinguishable to readers from something written here.
And of course vice versa. Let me take this piece, published here, and turn it into a URL that returns the source code for the document. No formatting. Just text with a little structure and metadata.
wenn wir alles was wir schreiben mit ein paar API-aufrufen oder einem knopfdruck oder vollautomatisch mit autodiscovery mit allen wesentlichen metadaten einbettbar machen können, würde ein traum von mir wahr. meins bleibt meins, aber es ist beweglich. technisch wäre das am ehesten mit RSS auf artikel- oder objekt-basis vergleichbar. das format, ob RSS, XML, JSON oder OPML hinter diesem mechanismus steckt, ist egal; hauptsache das protokoll ist offen und idiotensicher. soweit ich sehe, gibts im prinzip auch schon ein format dafür: oEmbed.
technisch würde ich eine lösung bevorzugen, mit der ich weiterhin auf meiner website, die ich unter kontrolle habe, schreibe aber deren inhalte beliebig in die informationsflüsse dritter einzubetten sind. so wie bisher mit RSS — und darüber hinaus. der anreiz die quelle, meine seite, zu besuchen, ist der kontext der meldung. optimalerweise ziehe ich per API die links, die erwähnungen, tweets, retweets, embeds oder diskussionen übersichtlich an einer stelle zusammen, ein kleines artikel-rivva. ansatzweise probiere ich das bereits jetzt, indem ich unter einem artikel alle tweets und blogartikel mit links auf den artikel einbette, die anzahl der likes, plusse oder quotes anzeige, ebenso, wenn vorhanden, einen link zur rivva-seite des artikels. den artikel und die optimalerweise eingebettete (und zurückhaltende) werbung gibts überall, den kontext und aggregierten reaktionen nur an der quelle.
jeff jarvis hat noch einen punkt der auch nicht unwichtig für die idee der informationsflüsse:
Creators don’t need protection from copying. That’s futile. Copying can’t be stopped. Thus copying is no longer a way to exploit the value of creation.
So what do creators need protected? What are their interests?
I’m thinking they need credit for their creations so they can build reputation or relationships they can exploit through many means: speaking for money, for example, or gaining social credit.
wir möchten, dass unsere gedanken, unsere ideen unsere worte möglichst weit getragen werden, empfohlen, kommentiert, geliked oder kritisiert werden. aber wir möchten auch, dass unsere ideen zu uns zurückverfolgbar bleiben — unseren namen und einen link auf die quelle mit sich tragen auf ihrem weg durch die welt. das ist nicht nur eine frage der technik, sondern vor allem auch eine frage des anstands, der konvention. die zuschreibung, die autorenzeile, der backlink ist neben dem applaus das brot des autoren. und das honorar? jarvis meint das ginge, wenn man sich einen ruf erschrieben hat mit veranstaltungen, direkten verkäufen (kindle single, ebooks), spenden (kickstarter, flattr) und eben eingebetteten anzeigen, die auch durchaus mit einbettbaren inhalten funktionierten (siehe turi2 oder repost.us, die genau das machen: artikel mit den refenrenzen zum original und eingelagerter werbung per nachrichtenstrom verteilen).
jarvis fasst das nochmal so zusammen:
Under creditright [as opposed to copyright], piracy is also redefined. The crime is not copying and sharing someone’s work, the crime is violating the means that creators provide — a la Creative Commons or Repost.US — for its use. This also infers that creators who do not provide those means — who do not make their content spreadable and embeddable — are just plain fools.
neu ist das alles freilich nicht. schon 2007 schrieb doc searls:
News is a river, not a lake.
artikellinks und quellen:
- scripting.com: We could make history
- dashes.com: Stop Publishing Web Pages
- readwriteweb.com: 5 Reasons Why Web Publishing is Changing (Again)
- blogs.law.harvard.edu: Future to Newspapers: Jump in the river
nachträge:
- zeit.de: Vom Rechnernetz zum EinHirn /via und von @ChristophKappes
- pandodaily.com: Ideas for How to Monetize the Future of Magazines
- hackr.de: Leftovers 2011 (Stream Edition)