mit maschinen über maschinenlesbarkeit reden
in den letzten tagen habe ich oft mit gemini über maschinenlesbaren code und meine implementierung davon hier auf wirres.net geredet. die implementierung mache ich mir cursor, was wiederum im hintergrund verschiedene agenten für das coding selbst nutzt. von daher ist es wahrscheinlich nicht schlecht, die arbeit von cursor nicht nur selbst zu reviewen, sondern auch noch weitere meinungen, diagnosen und einschätzungen einzuholen.
es zeigt sich, nicht alles was validiert ist auch unbedingt richtig. ein paar sachen funktionieren bereits richtig gut und google (der suchbot, der indexer, whatever) versteht hier und da meine inhalte, oder besser, meine intention. an anderen stellen klemmt es noch. so erkennt google ein paar meiner bilder als cc lizensiert, aber nicht alle.
ich finde das alles irre spannend, weil ich google bei der arbeit zugucken kann, erkenne wo noch verständnisprobleme stecken und was gegebenenfalls optimiert oder angepasst werden muss.
eben habe ich gemini gefragt, wie es die relevanz von maschinenlesbarer auszeichnunng von webinhalten insgesamt bewertet. der grösste faktor dürfte weiterhin google sein, das mit der rich-result-anzeige eine dicke, fette karotte in der hand hält, die es vor die nasen von website-betreibenden halten kann.
aber dieses argument, dass sich gemnini ausgedacht hat finde ich faszinierend. nämlich das maschinenlesbarer code auch eine antidot gegen ironie sein kann, ein faktenbett, mit dem ironie besser kontextualisiert werden könnte.
[Maschinenlesbare Auszeichnungen sorgen dafür], dass auch die dümmste KI kapiert, dass dein Verriss eigentlich eine 5-Sterne-Empfehlung ist. JSON-LD ist der einzige Ort im Internet, wo Ironie verboten ist – und genau das brauchen Maschinen.
das ist die detailierte herleitung:
Fakten vs. Nuance: Dein Blog ist ironisch ("fachblog für irrelevanz", "werbung ohne werbung"). Ein Mensch versteht die Ironie. Eine KI könnte verwirrt sein.
- Text: "Die Mühle ist hässlich, aber mahlt super."
- JSON-LD: reviewRating: 5.
- Das JSON liefert der KI die "Ground Truth" (die faktische Wahrheit). Es reduziert das Risiko, dass die KI deine Ironie missversteht und sagt: "Der Autor hasst die Mühle."
instagram nutzt wohl auch json-ld, wer hätte das gedacht? eigentlich ist instagram dafür bekannt sehr aggressiv gegen scraping vorzugehen. von der instagram-webseite kann man mit bordmitteln keine bilder sichern oder kopieren und selbst um an die eigenen inhalte zu kommen muss, man technisch sehr tief gehen und bekommt dann ständig auf die nase.
instagram nutzt json-ld, allerdings sperrt es offenbar alle user-agents ausser denen von google aus.
- wenn ich diesen instagram-beitrag von mir im browser aufrufe enthält der quelltext keine json-ld (keine maschinenlesbaren infos)
- wenn ich den gleichen beitrag in googles rich-results-test aufrufe, sprudeln plötzlich maschinenlesbare infos aus instagram
- wenn ich den gleichen beitrag im schema.org-validator aufrufe, verweigert instagram den zugriff
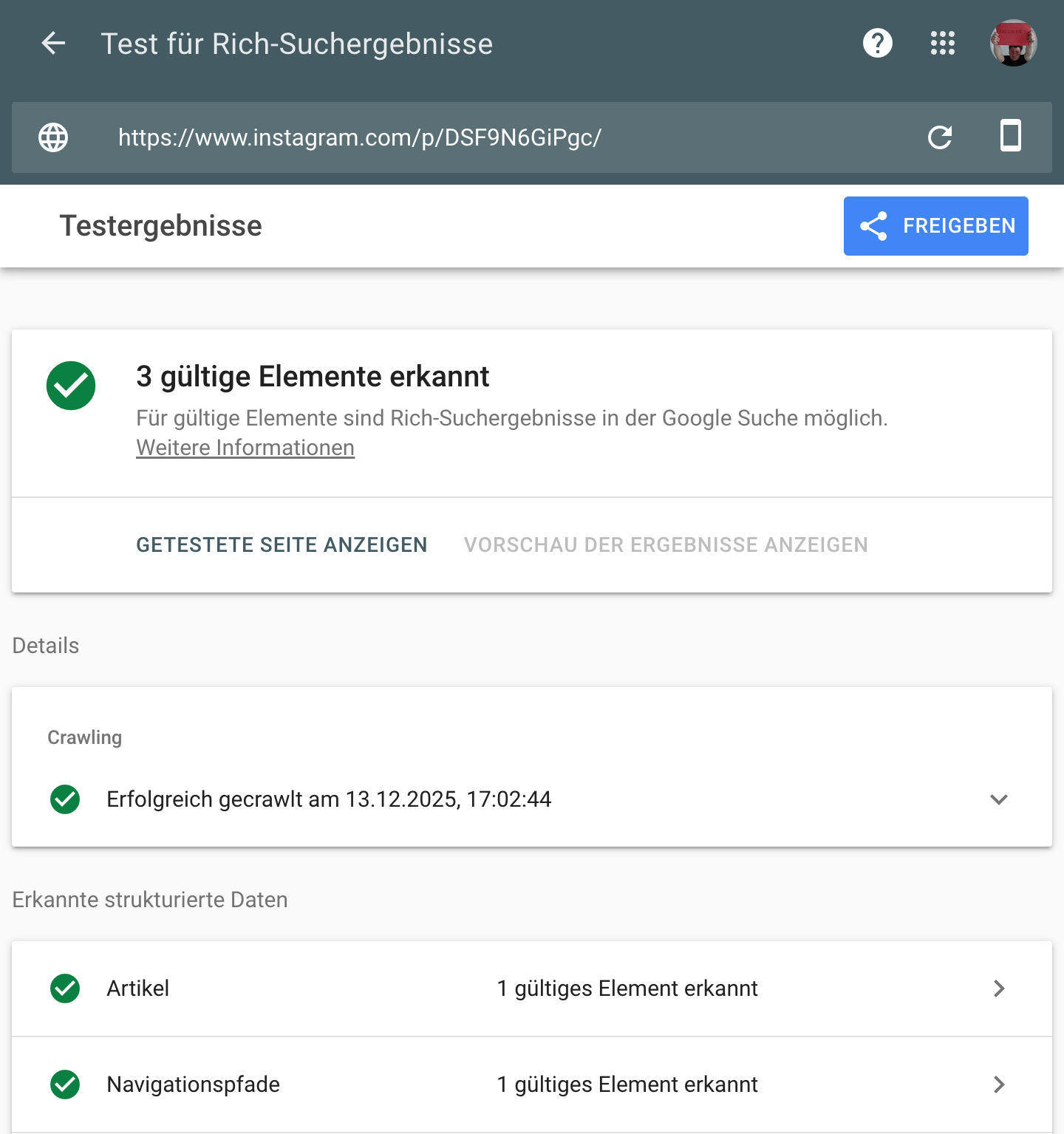
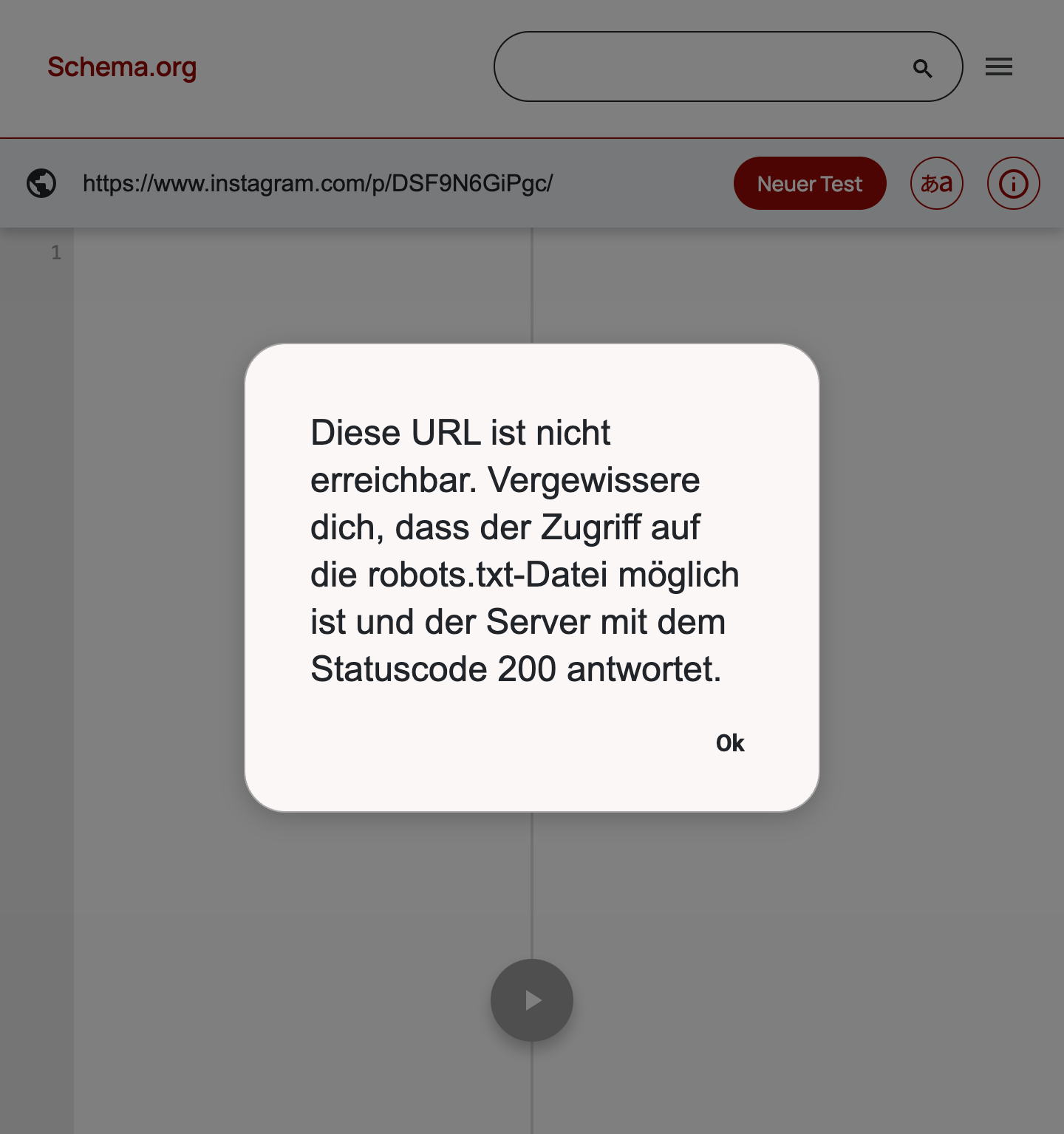
bemerkenswert: die im json-ld ausgegebenen bildurls scheinen permanent zu funktionieren, ein privileg, das instagram offenbar lediglich google gönnt: testlink. bildurls die man instagram aus der entwicklerkonsole entlockt, verlieren ihre gültigkeit nach ein paar stunden (testlink) (noch halten beide links).
das ist so ähnlich wie das was der spiegel mit seinen videos veranstaltet. otto-normal-besucher bekommt die videos nur mit werbung versehen zu gesicht, google darf die werbefreie quelldatei aus den maschinenlesbaren metadaten ziehen. die karotten die google websitebetreibenden oder hier instagram und dem spiegel verspricht, verleiteten beide zur diskriminierung von menschen und maschinen, wobei instagram zusätzlich auch noch nach herkunft diskriminiert (google only).
was instagram google zum frass vorwirft habe ich mir wegen diesem artikel auf cachys blog angesehen:
Die Plattform erstellt(e) offensichtlich automatisch Überschriften und Beschreibungen für Nutzer-Posts, damit diese besser bei Google ranken.
[…]
Viele Nutzer fühlen sich dadurch falsch dargestellt und haben keine Kontrolle darüber, wie ihre Inhalte im Netz präsentiert werden. Gerade bei sensiblen Themen oder kreativen Inhalten kann das schnell problematisch werden.
als ich das gelesen habe, dachte ich natürlich wie schön es wäre, wen man bilder und filme einfach bei sich auf einer eigenen webseite hosten könnte, auf einer webseite die man unter kontrolle hat und selbst bestimmen kann, was die maschinen zu sehen bekommen und was nicht.
ich poste mittlerweile nur noch sporadisch auf instagram. die insights, die instagram mittlerweile jedem zugänglich macht, zeigen auch, dass meine bilder dort ohnehin nur an wenige meiner follower ausgespielt werden. möchte ich dass mehr meiner follower die beiträge sehen, muss instagram schon sehr gut gelaunt sein oder will werbegeld von mir.
ich mag meinen workflow hier im blog mittlerweile lieber, als das mal-eben-schnell-posten auf instagram:
- ich kann lizenzinfos anhängen und die lizenz und zugänglichkeit meiner bilder selbst steuern
- ich kann schlagworte, links, text, video, geodaten frei schnauze benutzen
- ich kann einmal für alle bilder alt-texte setzen und beiträge und bilder dann inklusive der alt-texte zu mastodon und bluesky „syndizieren“
- ich kann meta-beschreibungen, titel nachträglich ändern und die präsentation, anordnung, grösse der bilder auch komplett selbst bestimmen
der preis dafür (alles selbst bestimmen zu können) ist etwas weniger reichweite und gefühlt eine etwas geringere „interaktion“.
für mich das stärkste argument bilder und filmchen selbst zu hosten, unter eigener kontrolle, ist die gestaltungsmacht über alles, zum beispiel mein archiv zu haben. die halbwertszeit eines post hier im blog dürfte sich nicht gross von der halbwertszeit eines beitrags auf instagram, mastodon oder bluesky unterscheiden. mit anderen worten: kaum jemand schaut sich beiträge an, die älter als 24 stunden oder eine woche sind. aber wenn ich will, kann ich (und jeder andere) schauen, was ich im dezember 2012 so getrieben habe. ich kann alte beiträge von mir einfach einbetten, ohne mir einen haufen tracker von einem dritten ins haus zu holen.

{kind=link}
{kind=link}
{kind=link}
wo war ich? ach ja. mir fiel heute auf, deshalb die überschrift „mit einer maschine über maschinenlesbarkeit reden“, wie viel vergnügen es mir bereitet mit gemini oder cursor über solche technischen details zu plaudern. ich bilde mir ein, die maschinen haben interesse an solchen detail-diskussionen und ich muss keinen menschen mit solchen gesprächen langweilen. wobei ich mich natürlich schon frage, wer diesen text, ausser ein paar maschinen, bis hier überhaupt gelesen hat?