

telefonzentrale
dirkvongehlen.de: Journalistenschüler kuratieren „6 vor 9“ #
und? hat ein bloggerschüler lust mal meine links für ne woche zu übernehmen?
tagesanzeiger.ch/deadline: Der Live-Ticker - das letzte grosse Abenteuer im Journalismus #
das vorwort von konstantin seibt für ein buch über liveticker steckt so voller goldener zitate, dass ix fast ne gänsehaut nen fullquotedrang beim lesen bekommen habe. das ist mein lieblingszitat:
Das Konzept von komprimierter Zeit ist auch das der Grund, warum Leute gern lesen: Sie machen ein blendendes Geschäft. In einer Minute haben sie eine Stunde fremde Denkarbeit oder mehr gewonnen.
spreeblick.com: Previously on FluxFM Spreeblick #
das muss ich mir bei gelegenheit alles mal anhören.
thisisnthappiness.com: Problem solved #
ein sehr, sehr schöner weihnachtsbaum!
das mache ich auch fast täglich mit der beifahrerin.
tagesschau.de: Notre Dame: Emanuel, Quasimodo und das Erbe der Revolution #
geschichten über grosse glocken lese ich immer sehr gerne. /maximilian buddenbohm
superlevel.de: Re: Pixel Fireplace #
mein erstes kaminfeuer in der neuen wohnung:

hello.eboy.com: LPZ-RollingStone-Concert-21k.png #
ein wimmelbild, dass die rolling stones ein bisschen infantil wirken lässt. wobei die, glaube ich, auch in echt so wirken.
sethgodin.typepad.com: Ridiculous is the new remarkable #
ix bin mir nicht ganz sicher wie man das in godins sinne übersetzen könnte: irrwitzig ist das neue bemerkenswert oder lächerlich ist das neue bemerkenswert? ich tendiere ja zu ersterem.

13
de.wikipedia.org: Das große Rennen von Belleville #
vor ziemlich genau ungefähr acht jahren empfahl don dahlmann den film „das grosse rennen von belleville“. ich habe mir den film damals gleich in der DVDhek ausgeliehen und habe seitdem versucht die beifahrerin und das kind davon zu überzeugen den film zu sehen — ohne erfolg.
gestern abend habe ich einfach, während die beifahrerin im wohnzimmer rumfuhrwerkte, den film angemacht — und sie hat ihn sich tatsächlich angesehen. ich habe auch ein bisschen mitgeguckt und mich hat der film wieder, wie damals, milde euphorisiert, die beifahrerin fand ihn „schön“ und „beeindruckend“. ich kann ich immer noch wärmsten empfehlen.
karinmissypaule.de: exersises, Fotografie #
sehr, sehr schöne arbeiten.
spiegel.de: Der Bau der Hamburger Elbphilharmonie sollte endgültig gestoppt werden #
gut herausgearbeitet von christoph twickel:
Landmark Buildings wie die Elbphilharmonie sind Monumente der Stärke, die sich Metropolen leisten, um vor einem globalen Anlagekapital zu protzen und die Botschaft auszusenden: Schaut her, hier lohnt sich das Investieren! Die Rücksichtslosigkeit, mit der eine Stadt ihr Gemeinwesen für solche Protzbauten in Haftung nehmen kann, wird zur vertrauensbildenden Maßnahme für den Standort.
ich war allerdings immer ein grosser fan des entwurfs von herzog demeuron. bis ich diesen absatz von christoph twickel las:
Der letzte gute Grund, warum Hamburg die Elbphilharmonie nicht weiterbauen sollte, ist ganz einfach: Es ist ein scheußliches Projekt. Seine Beeindruckungsästhetik nervt, und sein Konzept passt nicht in die Zeit. Ein Konzertsaal als exklusiver Audio-Uterus - gebaut in eine neoliberale Trutzburg aus Luxushotel, sündhaft teuren Eigentumsapartements und zugiger Aussichtsplattform für den Plebs? Was für eine unangenehme, undemokratische Idee.
„beeindruckungsästhetik“ — da ist leider mehr dran, als ich bisher wahrhaben wollte. (wobei man beim spiegel ja auch das gegenteil — den angeblichen ikea einheitslook — scheisse findet.)
meedia.de: Helmut Berger: Dschungelcamper „nicht normal“ #
media zitiert den spiegel der mit helmut berger gesprochen hat:
Auch über die RTL-Verantwortlichen schimpft Berger. Diese hätten ihn nach Köln eingeladen, wo der Vorspann zur Show gedreht werden soll. Dabei soll Berger einen Smoking tragen. Auf die Nachfrage des Senders nach seinen Maßen reagiert er pikiert: „Ich trage Versace! Da sind doch keine Maße drin! Arschlöcher!“
in der vorabmeldung des spiegels steht das jedenfalls nicht, meedia hat sich also extra eine aktuelle spiegel-ausgabe besorgt um daraus abzuschreiben zu zitieren.
carta.info: Küchenpsychologie, heute: Asperger #
cinthia briseño schreibt:
Asperger-Autisten haben Probleme, sich in andere hineinzuversetzen.
offenbar hat cinthia briseño auch schwierigkeiten sich in andere „hineinzuversetzen“. zumindest scheint das so, wenn man sich die reaktionen auf ihren artikel ansieht.
katia kelm:
die stimmung in hamburg ist wie in ner disko morgens um 5, wenn klar wird: man hat immer noch keinen zum ficken gefunden. man weiss dass es zeit wird zu gehen. und ein paar können sich immer noch nicht los eisen, weils draussen regnet und der nachtbus kommt nur alle stunde.
sprachlog.de: Nicht zu retten: das Wort des Jahres #
anatol stefanowitsch meint das wort des jahres sei nicht zu retten, detlef guertler hingegen meint dass ich in der zusammenschau der wörter des jahres über die jahre „so etwas wie eine Kürzest-Geschichte der Bundesrepublik“ zeigt.
ich persönlich finde das wort „rettungsroutine“ toll bescheuert.
boingboing.net: Roger Ebert on how the press reports mass killings #
In short, I said, events like Columbine are influenced far less by violent movies than by CNN, the NBC Nightly News and all the other news media, who glorify the killers in the guise of "explaining" them.
dashes.com: The Web We Lost #
diesen artikel von anil dash hat wahrscheinlich schon jeder gelesen, den das thema früher-war-im-web-alles-besser interessiert. ups, jetzt ist mir der erste satz etwas polemisch rausgerutscht, dabei ist der artikel wirklich gut und arbeitet wunderbar raus, dass die entwicklungen des webs sich im kreis bewegen — oder diffuser ausgedrückt, dass der fortschritt im netz mit vielen rückschritten einhergeht. aber vor allem ist anil dash optimistisch:
We'll fix these things; I don't worry about that. The technology industry, like all industries, follows cycles, and the pendulum is swinging back to the broad, empowering philosophies that underpinned the early social web.
horizont.net: Paid Content für Dummies: Die Paywall von Welt Online im HORIZONT-Check #
david hein:
Welt Online bietet gewissermaßen Paid Content für Dummies - allerdings ist die Umgehung der Bezahlschranke fast noch einfacher als die Anmeldung selbst.
ich glaube david hein wollte gar keine doppeldeutigen andeutungen über das intellektuelle niveau von welt-lesern machen, sondern einfach nur die bezahlschranke der welt loben. das ist ihm aber nicht ganz gelungen. /christoph maier


schneemannfotografin

kerzenständer

Schnitzel
techdirt.com: Funny How Copyright Holders Only Ramped Up Google DMCA Takedowns After SOPA Failed #
mike masnick:
[The big copyright players] pretended there were no existing remedies when the reality was they just didn't want to make use of them. It almost makes you wonder if they specifically chose not to make use of those remedies in an attempt to pretend that the situation was worse than it really is...
erinnert mich an das verhalten von christoph keese. zu behaupten die situation sei schlimmer als sie ist und demnach irgendwelche gesetze zu fordern die die situation angeblich bessern würden, die vorhandenen möglichkeiten werden nicht genutzt, um eine drohkulisse beim gesetzgeber aufzubauen.
ibusiness.de: Google und Verleger: Taliban. Idioten. Gierschlünde. #
joachim graf über google, verleger, taliban, idioten und gierschlünde. etwas polemisch aber witzig. witzig auch, weil die illustrationen zum artikel kostenpflichtig sind.
aha. so werden computer also gemacht.
irights.info: Wen und was betrifft das Leistungschutzrecht? Nichts genaues weiß man nicht #
die inkompetenz der politischen kaste ermuntert mich ehrlichgesagt mehr und mehr mich selbst politisch zu betätigen. bisher dachte ich immer dafür bin ich zu doof. mittlerweile glaube ich das — in aller bescheidenheit — nicht mehr.
spiegel.de: Zero Dark Thirty: Thriller über Jagd auf Bin Laden ist großartig #
wenn die zweite staffel von „homeland“ bald zuende ist, scheint mir zero dark thirty ein würdiger kurzersatz zu sein.
facebook.com/mstoverock: Liebe Hundehalter, ... #
das sagte tanja haeusler kürzlich auf facebook — ich glaube ohne besonderen grund, aber zu meinem grossen vergnügen:
Ich rauche, ich saufe, ich fahre im Winter nicht Rad, sondern Auto.
Soeben habe ich die 7. Lichterkette aufgehängt (natürlich NICHT diese hässlichen Energiespardinger).
Vor, zum und nach dem Fest gibt's leckeres Schwein, knusprige Gans und Schampus von Aldi.
Dazu glotze ich aus dem Netz gezogene amerikanische TV-Serien, oder hänge vor der Konsole und zocke mir das Hirn weg. Zusammen mit den von Kopf bis Knöchel in H&M gehüllten Kindern (an den Füßen bevorzugen sie Nike) und einem Mann, der sogar beim Zähneputzen auf Coca-Cola besteht und zu Sylvester irgendwas dreistelliges für Böller und Raketen raushauen wird.
Ich selbst wollte mein Geld eigentlich in Yoga investieren, aber wenn ich drüber nachdenke, passt ein Hund viel besser zu uns.
Und macht bedeutend mehr Spaß!
littlebigdetails.com: Blom and Blom - All the lamps on the website light up when you hover them. #
sehr hübsch. auch das blog von blom und blom.
thingsorganizedneatly.tumblr.com: Steven Emmanuel #
grandios ordentlich sortiert!
thisisnthappiness.com: I believe in advertising #
laubbläser: die unnötigste erfindung der welt. aber trotzdem gute laubbläser-werbung.
vorspeisenplatte.de: Twitterliebe im Dezember #
sehr tolle tweets, leider alle nicht verlinkt.

wenn mich @dasnuf mit sturmmaske ins internet stellt, mach ich das auch mal.
metronaut.de: So kam die CDU zur Twitter Event Page (Update: Antwort der SPD) #
die CDU, die SPD und john f. nebel erklären wie twitter-event-seiten zusatnde kommen. und möglicherweise flunkert die CDU.
judithholofernes.com: Dumm die, die dumm (Revisited/ Teil 2/ Reloaded/ Jetzt erst recht) #
hier das original bei der titanic.
wired.com/rawfile: To Hell With Steve Jobs, Torture and Photoshop, Says Upside-Down Photographer #
ein haariger mann der sich auf dem kopf stehend fotografiert und auch irgendeine botschaft hat.
vanityfair.com: Louis C.K.: The Proust Questionnaire #
Question: What is the trait you most deplore in yourself?
Louis C.K.: I have an absolutely beautiful penis. It's stunning in every way. God I hate my perfect penis. [...]

conversableeconomist.blogspot.co.il: Paper Towels v. Air Dryers #
ah. mit papierhantüchern kann man bakterien von den feuchten händen wischen. praktisch. /marginalrevolution.com
taz.de: Zweitjobs von Parlamentariern: Pirat ohne Transparenz #
alexander morlang ist für transparenz, nur nicht bei sich selbst. zumindest nicht solange er nicht alle seine papiere geordnet hat. oder so. /presseschauer
möglicherweise ist der moment 20.12.2012 20:12 uhr noch einen ticken toller als der hier.
Immer wenn ich Robots.txt, die von Google bevorzugte Rechtesprache, kritisiere, hagelt es Vorwürfe der Lüge und Dummheit. Manche meinen, ich sei dumm und verlogen zugleich.
und dann zählt er eine liste von „Informationen“ auf, „die man in [eine] gute maschinenlesbare Rechtesprache eintragen können sollte, und die von anderen Marktteilnehmern zu berücksichtigen wären“. fast alle informationen die keese auflistet kann man bereits jetzt in verlagsprodukte die von verlagen ins netz gestellt werden eintragen oder genauso wie er fordert umsetzen. einige dieser informtionen werden vom axel-springer-verlag bereits auf seinen webseiten genutzt, viele nicht. was derzeit keine suchmaschine und kein aggregator auswertet, sind preisinformationen. diese wären aber ohne weiteres maschinenlesbar in jede verlagsseite einbettbar. sobald ein verlag anfängt diese maschinenlesbar eingebetteten preise für aggregation oder versnippung oder zugänglichmachung einzuklagen, werden suchmaschinen diese preisinformation garantiert sehr schnell beachten. allerdings ziert sich der axel-springer-verlag bisher sehr, diese preise irgendjemandem zu nennen. so sagte mathias döpfner kürzlich:
Nach Angaben von Döpfner hat das US-Unternehmen auch nach Jahren der Auseinandersetzung „noch nie nach dem Preis gefragt, der uns vorschwebt“.
auch die menschenlesbare „rechtesprache“ des axel-springer-verlags, beispielsweise die „nutzungsregeln“ die das springer-blatt „die welt“ ins netz stellt, zählen die rechte die keese gerne in einer maschinenlesbaren rechtesprache sehen möchte nicht sonderlich differenziert auf:
Der Inhalt der interaktiven Webseiten von DIE WELT ist urheberrechtlich geschützt. Die Vervielfältigung, Änderung, Verbreitung oder Speicherung von Informationen oder Daten, insbesondere von Texten, Textteilen oder Bildmaterial, ist ohne vorherige Zustimmung von DIE WELT nicht gestattet.
diese nutzungsrechte kommen mir vor, wie ein undiffertenzierter, grober, rechtlicher klotz oder in keeses worten ein „lichtschalter“. auf der webseite der welt kann ich ausser den oben zitierten groben nutzungsbedingungen (die defacto alles verbieten) keine informationen zur gewerblichen nutzung, lizensierung, aggregation, archivierung oder weitergabe finden.
tatsache ist, dass der grossteil von dem was keese hier fordert bereits existiert und in der praxis funktioniert. ich gehe keeses liste weiter unten mal im detail durch.
ich wundere mich in welche kategorie die aggregation von verlagsinhalten durch soziale netzwerke fällt. denn auf fast allen webseiten des axel-springer-verlags werden die nutzer (übrigens ohne differenzierung in gewerbliche und private nutzer) aufgefordert die inhalte über soziale netzwerke (twitter, google-plus, facebook) zu aggregieren. bei der nutzung dieser buttons kann es durchaus passieren, dass ich inhalte „an Gewerbe“ weitergebe. oder als gewerbetreibender inhalte an „Privatpersonen“ weitergebe. sollen twitter, facebook, google-plus küftig dann auch die maschinenlesbaren rechtesprache honorieren? muss twitter den „tweet“-button künftig für gewerbetreibende deaktivieren, wenn die seite maschinenlesbar als nicht-gewerblich-aggregierbar ausgezeichnet ist?
Name des Textautoren (✓)
machbar mit authorship-markup. wird auch auf vielen seiten des axel-springer-verlags eingesetzt. was ist eigentlich mit autorinnen?
Name des Bildautoren (✓)
soweit ich sehe derzeit nicht maschinenlesbar machbar, allerdings wird das auch in den seltensten fällen menschenlesbar gemacht. meisten steht am foto etwas wie „Foto: dpa“, „Fotos: © ZDF“, „Foto: AFP“, oft gar nichts (beispiel 1, beispiel 2)
es spricht aber nichts dagegen, den bildautoren in die maschinenlesbare bildunterschrift einzutragen. das geht bespielsweise mit einer bilder-XML-sitemap. damit kann man auch die bild-lizenz maschinenlesbar angeben.
[nachtrag 12.12.2012 23:33]
mehrere kommentatoren und torsten kleinz weisen darauf hin, dass man autoren-informationen auch in den EXIF oder IPTC-daten von bildern abspeichern könne. damit kann man wohl auch die lizenz, bzw. lizeninformationen einbetten.
Name des Verlags (falls vorhanden) (✓)
welcher verlag hat denn in deutschland noch keinen namen? abgesehen davon ist es möglich den namen des verlags neben dem autorennamen anzugeben und wird beispielsweise so bei der welt gemacht. dafür kann kann man einerseits klassiche meta-tags nutzen, die es — glaube ich — seit ungefähr 20 jahren in dieser form gibt:
oder wie die welt es bereits nutzt, mit einem einfachen, von google ausgewerteten metatag im header der seite:
Name der Webseite (✓)
ist mit meta-tags, og-tags oder diversen microformaten möglich und das wird auch von den meisten aggregatoren und suchmaschinen ausgewertet:
Name der beauftragten Clearing- oder Abrechnungsstelle (✘)
Name der das Recht wahrnehmenden Verwertungsgesellschaft (✘)
da es diese clearing- oder abrechnungsstellen offenbar noch nicht gibt, ist das natürlich unsinn eine angeben zu wollen. ich habe auch auf keiner webseite des axel-springer-verlags hinweise auf eine solche clearingstelle gefunden, weder maschinenlesbar oder menschenlesbar. gäbe es eine clearingstelle, lässt die sich sicherlich gut in die maschinenlesbaren lizenzinformationen (siehe unten) einbetten.
andererseits ist das für mich logisch schwer nachzuvollziehen; keese fordert, dass suchmaschinen etwas berücksichtigen für das erst durch ein leistungsschutzgesetz eine rechtliche grundlage geschaffen würde?
Einzuhaltende Zeitverzögerung bei Nutzung durch Dritte (✓)
das ist beireits jetzt unproblematisch umzusetzen. seriöse aggregatoren respektieren die robots.txt anweisungen die man auch einem einzelnen artikel mitgeben kann. es wäre also kein problem das verlagsseitig zu lösen: jeder artikel der erst nach einer bestimmten zeit durch dritte genutzt werden soll, bekommt einfach für die zeit in der er nicht genutzt werden darf einen robots-meta-tag:
sobald der artikel durch dritte genutzt werden darf, steht auf der seite
Gewerbliche Kopie erlaubt / nicht erlaubt (?)
Preis für gewerbliche Kopie (✘)
Maximal Anzahl der gewerblichen Kopien (?)
ich verstehe nicht was das genau bedeuten soll. ich fertige ja eine kopie in meinem browser-cache an, wenn ich eine webseite aufrufe. mache ich das beruflich, handle ich gewerblich. diese rechtsanweisung würde nur sinn machen, wenn es ein leistungsschutzrecht gäbe dass die gewerbliche nutzung (im sinne von lesen oder abspeichern, ausdrucken, in ein intranet kopieren) kostenpflichtig machen würde. danach sieht es aber nicht aus, denn selbst die CDU/CSU/FDP-koalition wollte sich auf diesen irrsinn nicht einlassen.
Gewerbliche Aggregation erlaubt / nicht erlaubt (✓)
verstehe ich auch nicht. 90 prozent der mir bekannten aggregatoren und suchmaschinen handeln gewerblich. ich kenne keine aus privatvergnügen betriebene suchmaschine. aggregation wird fast ausschliesslich von firmen berieben. diese gewerbliche aggregation lässt sich aber bestens mit der robots.txt ausschliessen. aggregatoren und suchmaschinen die für die aggregation zahlen möchten kann ja ein erweiterter robots.txt angeboten werden:
Preis für gewerbliche Aggregation (✘)
das wundert mich jetzt auch. laut mathias döpfner möchte der springer-verlag gar nicht sagen was soetwas kostet, sondern möchte danach gefragt werden (siehe döpfner-zitat oben).
wozu dann also eine maschinenlesbare information fordern, wenn der axel-springer-verlag diese information gar nicht öffentlich (mit)teilen möchte?
Maximale Länge der Aggregation (✓)
auch das lässt sich in der regel für alle möglichen formen der aggregation festlegen. facebook, google+, aber in den meisten fällen auch die google-suche, nutzen den text des description-tags. eine anweisung wie diese:
führt zu einer snippet-anzeige wie dieser:
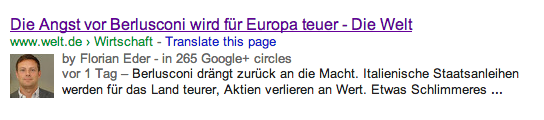
wäre der description-text kürzer, würde er auch kürzer angezeigt.
Gewerbliche Archivierung erlaubt / nicht erlaubt (✓)
auch die archivierung lässt sich per robots.txt oder dieser anweisung steuern:
da niemand private archivierung differnzieren, verbieten oder kontrollieren kann, reicht die robots.txt hier vollkommen aus: sie schliesst in der praxis ausschliesslich gewerbliche archivierung aus.
Preis für gewerbliche Archivierung (✘)
siehe gewerbliche aggregation.
Maximale Dauer der Archivierung (✓)
siehe gewerbliche aggregation; sollte es aggregatoren oder suchmaschinen geben, die sich dem lizenzmodell eines verlages für archivierung beugen wollen, kann mit diesen leicht eine anweisung vereinbart werden die das regelt, für alle anderen gilt noarchive:
Gewerbliche Teaser erlaubt / nicht erlaubt (✓)
Preis für gewerbliche Teaser (✘)
Maximale Länge gewerblicher Teaser (✓)
warum unterscheidet keese zwischen snippet und teaser? suchmaschinen und soziale netzwerke zeigen derzeit snippets an deren wortlaut und länge man mit dem description meta- oder og-tag festlegen kann. wozu an dieser stelle einer erweiterung auf komplette teaser? sollen suchmaschinen mit dem LSR eventuell dazu gebracht werden nicht nur snippets kostenpflichtig anzuzeigen, sondern auch teaser?
setzt man der einfachheit halber teaser mit snippets gleich, lässt sich die anzeige von teasern bei gewerblichen (also allen) suchmaschinen über die robots.txt steuern. wenn ein verlag die teaser einpreisen möchte, kann er das ja machen, alle anderen sollten dann auch verzichten dürfen:
Weitergabe an Privatpersonen erlaubt / nicht erlaubt (?)
Preis für Weitergabe an Privatpersonen (?)
Weitergabe an Gewerbe erlaubt / nicht erlaubt (?)
Preis für Weitergabe an Gewerbe (?)
dafuck? was könnte keese damit meinen? was soll weitergegeben werden dürfen? ein artikel? ein suchergebnis? ein snippet? ein teaser? eine url? was bedeutet „weitergabe“? wie gibt man artikel auf webseiten in keeses sinn „weiter“? auf facebook? per mail? per usb-stick? als schwarz-weiss kopie?
Anzeige des Autorennamens zwingend / nicht zwingend (✓)
ah. hiermit soll wohl gezeigt werden: das #lsr ist auch gut für die rechte der autoren. auf allen seiten des axel-springer-verlages die ich stichprobenartig geprüft habe und auf denen authorship-markup verwendet wurde, zeigt sich in den suchergebnissen auch der autorenname.
Veränderungen erlaubt / nicht erlaubt (?)
Mashups erlaubt / nicht erlaubt (?)
hat das etwas mit aggregatoren, suchmaschinen oder gewerblichen nutzern zu tun? an welcher stelle verändern oder mashuppen suchmaschinen oder aggregatoren verlagserzeugnisse? ist das ernsthaft ein problem? und wenn das so wäre, wäre es nicht ein anfang das in die nutzungsbedingungen der jeweiligen verlagsangebote zu schreiben? oder in die nutzungslizenz, die bereits jetzt in jede webseite maschinen- und menschenlesabr und einbettbar ist, per dublin core metadata oder rel="dc:license" (info) oder rel="license" (info).
[nachtrag 12.12.2012, 23:33]
viele der argumente die ich hier aufzähle hat bereits michael butscher in einem kommentar unter keeses artikel aufgelistet:
“Weitergabe an [...] erlaubt / nicht erlaubt”
Für die meisten Suchmaschinen/Aggregatoren nicht relevant, die geben allenfalls Snippets weiter und die vorherige Prüfung, ob der jeweilige Nutzer gewerblich ist, ist dann doch etwas viel verlangt.
Interessant wäre das allenfalls für Aggregatoren mit zahlenden (meist gewerblichen) Kunden. Für diesen Spezialfall ist das LSR aber überdimensioniert.
und in einem weiteren kommentar, in dem er sich selbst zitiert und ergänzt:
“Sie könnten auch das von mir skizzierte technische Zweistufenmodell verwenden: Wer ACAP unterstützt, darf zu den damit definierten Bedingungen, wer nicht, wird mit robots.txt/Meta-Tags ausgesperrt.”
Inzwischen weiß ich, daß der ACAP-Standard sogar schon einen Schalter enthält, der genau das tut (Ignorieren der robots.txt-Definitionen nach bisherigem Standard).
Dieser Schalter ergibt natürlich nur Sinn, wenn die Autoren von ACAP damit rechneten, daß eben nicht alle Suchmaschinen und Aggregatoren den ACAP-Standard unterstützen würden.
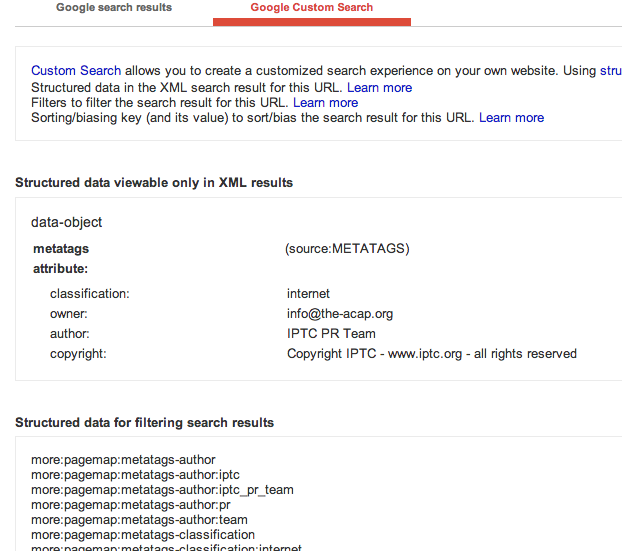
das acap-protokoll, auf das sich keese bereits einmal in aller länge bezogen hatte, lohnt sicher einen weiteren blick. ich frage mich aber, warum der axel-springer-verlag das protokoll nicht einfach nutzt. es ist abwärtskompatibel und die implementierung dauert laut acap-website keine 30 minuten.
und zumindest google liest die strukturierten daten des acap-protokolls durchaus ein, wie man in googles rich snippet tool sieht (klick auf „Google Custom Search“):
sie so: horst evers ist schon genial.
ich so: das buch kannst du ja heute abend lesen.
sie so: hab ich schon durch. das ist so witzig! er hat zum beispiel was über frühjahrsmüdigkeit geschrieben. im frühjahr … — also man ist ja immer müde, aber das schöne am frühling ist, dass man das dann frühjahrsmüdigkeit nennen kann.
ich so: […]
sie so: aber bei horst evers ist das witzig!

shit happens.


sehr, witzig, krähen die an schwänzen ziehen. ausserdem, wie der titel bereits verrät, scholz-links und ein eingebettetes foto, dass sich laut jens scholz nicht einbetten lässt.
cheezburger.com: So THAT'S How Babies are Made #
aha. so geht das.



