maschinenlesbarer keese
Immer wenn ich Robots.txt, die von Google bevorzugte Rechtesprache, kritisiere, hagelt es Vorwürfe der Lüge und Dummheit. Manche meinen, ich sei dumm und verlogen zugleich.
und dann zählt er eine liste von „Informationen“ auf, „die man in [eine] gute maschinenlesbare Rechtesprache eintragen können sollte, und die von anderen Marktteilnehmern zu berücksichtigen wären“. fast alle informationen die keese auflistet kann man bereits jetzt in verlagsprodukte die von verlagen ins netz gestellt werden eintragen oder genauso wie er fordert umsetzen. einige dieser informtionen werden vom axel-springer-verlag bereits auf seinen webseiten genutzt, viele nicht. was derzeit keine suchmaschine und kein aggregator auswertet, sind preisinformationen. diese wären aber ohne weiteres maschinenlesbar in jede verlagsseite einbettbar. sobald ein verlag anfängt diese maschinenlesbar eingebetteten preise für aggregation oder versnippung oder zugänglichmachung einzuklagen, werden suchmaschinen diese preisinformation garantiert sehr schnell beachten. allerdings ziert sich der axel-springer-verlag bisher sehr, diese preise irgendjemandem zu nennen. so sagte mathias döpfner kürzlich:
Nach Angaben von Döpfner hat das US-Unternehmen auch nach Jahren der Auseinandersetzung „noch nie nach dem Preis gefragt, der uns vorschwebt“.
auch die menschenlesbare „rechtesprache“ des axel-springer-verlags, beispielsweise die „nutzungsregeln“ die das springer-blatt „die welt“ ins netz stellt, zählen die rechte die keese gerne in einer maschinenlesbaren rechtesprache sehen möchte nicht sonderlich differenziert auf:
Der Inhalt der interaktiven Webseiten von DIE WELT ist urheberrechtlich geschützt. Die Vervielfältigung, Änderung, Verbreitung oder Speicherung von Informationen oder Daten, insbesondere von Texten, Textteilen oder Bildmaterial, ist ohne vorherige Zustimmung von DIE WELT nicht gestattet.
diese nutzungsrechte kommen mir vor, wie ein undiffertenzierter, grober, rechtlicher klotz oder in keeses worten ein „lichtschalter“. auf der webseite der welt kann ich ausser den oben zitierten groben nutzungsbedingungen (die defacto alles verbieten) keine informationen zur gewerblichen nutzung, lizensierung, aggregation, archivierung oder weitergabe finden.
tatsache ist, dass der grossteil von dem was keese hier fordert bereits existiert und in der praxis funktioniert. ich gehe keeses liste weiter unten mal im detail durch.
ich wundere mich in welche kategorie die aggregation von verlagsinhalten durch soziale netzwerke fällt. denn auf fast allen webseiten des axel-springer-verlags werden die nutzer (übrigens ohne differenzierung in gewerbliche und private nutzer) aufgefordert die inhalte über soziale netzwerke (twitter, google-plus, facebook) zu aggregieren. bei der nutzung dieser buttons kann es durchaus passieren, dass ich inhalte „an Gewerbe“ weitergebe. oder als gewerbetreibender inhalte an „Privatpersonen“ weitergebe. sollen twitter, facebook, google-plus küftig dann auch die maschinenlesbaren rechtesprache honorieren? muss twitter den „tweet“-button künftig für gewerbetreibende deaktivieren, wenn die seite maschinenlesbar als nicht-gewerblich-aggregierbar ausgezeichnet ist?
Name des Textautoren (✓)
machbar mit authorship-markup. wird auch auf vielen seiten des axel-springer-verlags eingesetzt. was ist eigentlich mit autorinnen?
Name des Bildautoren (✓)
soweit ich sehe derzeit nicht maschinenlesbar machbar, allerdings wird das auch in den seltensten fällen menschenlesbar gemacht. meisten steht am foto etwas wie „Foto: dpa“, „Fotos: © ZDF“, „Foto: AFP“, oft gar nichts (beispiel 1, beispiel 2)
es spricht aber nichts dagegen, den bildautoren in die maschinenlesbare bildunterschrift einzutragen. das geht bespielsweise mit einer bilder-XML-sitemap. damit kann man auch die bild-lizenz maschinenlesbar angeben.
[nachtrag 12.12.2012 23:33]
mehrere kommentatoren und torsten kleinz weisen darauf hin, dass man autoren-informationen auch in den EXIF oder IPTC-daten von bildern abspeichern könne. damit kann man wohl auch die lizenz, bzw. lizeninformationen einbetten.
Name des Verlags (falls vorhanden) (✓)
welcher verlag hat denn in deutschland noch keinen namen? abgesehen davon ist es möglich den namen des verlags neben dem autorennamen anzugeben und wird beispielsweise so bei der welt gemacht. dafür kann kann man einerseits klassiche meta-tags nutzen, die es — glaube ich — seit ungefähr 20 jahren in dieser form gibt:
oder wie die welt es bereits nutzt, mit einem einfachen, von google ausgewerteten metatag im header der seite:
Name der Webseite (✓)
ist mit meta-tags, og-tags oder diversen microformaten möglich und das wird auch von den meisten aggregatoren und suchmaschinen ausgewertet:
Name der beauftragten Clearing- oder Abrechnungsstelle (✘)
Name der das Recht wahrnehmenden Verwertungsgesellschaft (✘)
da es diese clearing- oder abrechnungsstellen offenbar noch nicht gibt, ist das natürlich unsinn eine angeben zu wollen. ich habe auch auf keiner webseite des axel-springer-verlags hinweise auf eine solche clearingstelle gefunden, weder maschinenlesbar oder menschenlesbar. gäbe es eine clearingstelle, lässt die sich sicherlich gut in die maschinenlesbaren lizenzinformationen (siehe unten) einbetten.
andererseits ist das für mich logisch schwer nachzuvollziehen; keese fordert, dass suchmaschinen etwas berücksichtigen für das erst durch ein leistungsschutzgesetz eine rechtliche grundlage geschaffen würde?
Einzuhaltende Zeitverzögerung bei Nutzung durch Dritte (✓)
das ist beireits jetzt unproblematisch umzusetzen. seriöse aggregatoren respektieren die robots.txt anweisungen die man auch einem einzelnen artikel mitgeben kann. es wäre also kein problem das verlagsseitig zu lösen: jeder artikel der erst nach einer bestimmten zeit durch dritte genutzt werden soll, bekommt einfach für die zeit in der er nicht genutzt werden darf einen robots-meta-tag:
sobald der artikel durch dritte genutzt werden darf, steht auf der seite
Gewerbliche Kopie erlaubt / nicht erlaubt (?)
Preis für gewerbliche Kopie (✘)
Maximal Anzahl der gewerblichen Kopien (?)
ich verstehe nicht was das genau bedeuten soll. ich fertige ja eine kopie in meinem browser-cache an, wenn ich eine webseite aufrufe. mache ich das beruflich, handle ich gewerblich. diese rechtsanweisung würde nur sinn machen, wenn es ein leistungsschutzrecht gäbe dass die gewerbliche nutzung (im sinne von lesen oder abspeichern, ausdrucken, in ein intranet kopieren) kostenpflichtig machen würde. danach sieht es aber nicht aus, denn selbst die CDU/CSU/FDP-koalition wollte sich auf diesen irrsinn nicht einlassen.
Gewerbliche Aggregation erlaubt / nicht erlaubt (✓)
verstehe ich auch nicht. 90 prozent der mir bekannten aggregatoren und suchmaschinen handeln gewerblich. ich kenne keine aus privatvergnügen betriebene suchmaschine. aggregation wird fast ausschliesslich von firmen berieben. diese gewerbliche aggregation lässt sich aber bestens mit der robots.txt ausschliessen. aggregatoren und suchmaschinen die für die aggregation zahlen möchten kann ja ein erweiterter robots.txt angeboten werden:
Preis für gewerbliche Aggregation (✘)
das wundert mich jetzt auch. laut mathias döpfner möchte der springer-verlag gar nicht sagen was soetwas kostet, sondern möchte danach gefragt werden (siehe döpfner-zitat oben).
wozu dann also eine maschinenlesbare information fordern, wenn der axel-springer-verlag diese information gar nicht öffentlich (mit)teilen möchte?
Maximale Länge der Aggregation (✓)
auch das lässt sich in der regel für alle möglichen formen der aggregation festlegen. facebook, google+, aber in den meisten fällen auch die google-suche, nutzen den text des description-tags. eine anweisung wie diese:
führt zu einer snippet-anzeige wie dieser:
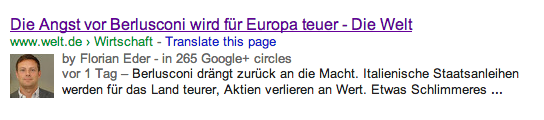
wäre der description-text kürzer, würde er auch kürzer angezeigt.
Gewerbliche Archivierung erlaubt / nicht erlaubt (✓)
auch die archivierung lässt sich per robots.txt oder dieser anweisung steuern:
da niemand private archivierung differnzieren, verbieten oder kontrollieren kann, reicht die robots.txt hier vollkommen aus: sie schliesst in der praxis ausschliesslich gewerbliche archivierung aus.
Preis für gewerbliche Archivierung (✘)
siehe gewerbliche aggregation.
Maximale Dauer der Archivierung (✓)
siehe gewerbliche aggregation; sollte es aggregatoren oder suchmaschinen geben, die sich dem lizenzmodell eines verlages für archivierung beugen wollen, kann mit diesen leicht eine anweisung vereinbart werden die das regelt, für alle anderen gilt noarchive:
Gewerbliche Teaser erlaubt / nicht erlaubt (✓)
Preis für gewerbliche Teaser (✘)
Maximale Länge gewerblicher Teaser (✓)
warum unterscheidet keese zwischen snippet und teaser? suchmaschinen und soziale netzwerke zeigen derzeit snippets an deren wortlaut und länge man mit dem description meta- oder og-tag festlegen kann. wozu an dieser stelle einer erweiterung auf komplette teaser? sollen suchmaschinen mit dem LSR eventuell dazu gebracht werden nicht nur snippets kostenpflichtig anzuzeigen, sondern auch teaser?
setzt man der einfachheit halber teaser mit snippets gleich, lässt sich die anzeige von teasern bei gewerblichen (also allen) suchmaschinen über die robots.txt steuern. wenn ein verlag die teaser einpreisen möchte, kann er das ja machen, alle anderen sollten dann auch verzichten dürfen:
Weitergabe an Privatpersonen erlaubt / nicht erlaubt (?)
Preis für Weitergabe an Privatpersonen (?)
Weitergabe an Gewerbe erlaubt / nicht erlaubt (?)
Preis für Weitergabe an Gewerbe (?)
dafuck? was könnte keese damit meinen? was soll weitergegeben werden dürfen? ein artikel? ein suchergebnis? ein snippet? ein teaser? eine url? was bedeutet „weitergabe“? wie gibt man artikel auf webseiten in keeses sinn „weiter“? auf facebook? per mail? per usb-stick? als schwarz-weiss kopie?
Anzeige des Autorennamens zwingend / nicht zwingend (✓)
ah. hiermit soll wohl gezeigt werden: das #lsr ist auch gut für die rechte der autoren. auf allen seiten des axel-springer-verlages die ich stichprobenartig geprüft habe und auf denen authorship-markup verwendet wurde, zeigt sich in den suchergebnissen auch der autorenname.
Veränderungen erlaubt / nicht erlaubt (?)
Mashups erlaubt / nicht erlaubt (?)
hat das etwas mit aggregatoren, suchmaschinen oder gewerblichen nutzern zu tun? an welcher stelle verändern oder mashuppen suchmaschinen oder aggregatoren verlagserzeugnisse? ist das ernsthaft ein problem? und wenn das so wäre, wäre es nicht ein anfang das in die nutzungsbedingungen der jeweiligen verlagsangebote zu schreiben? oder in die nutzungslizenz, die bereits jetzt in jede webseite maschinen- und menschenlesabr und einbettbar ist, per dublin core metadata oder rel="dc:license" (info) oder rel="license" (info).
[nachtrag 12.12.2012, 23:33]
viele der argumente die ich hier aufzähle hat bereits michael butscher in einem kommentar unter keeses artikel aufgelistet:
“Weitergabe an [...] erlaubt / nicht erlaubt”
Für die meisten Suchmaschinen/Aggregatoren nicht relevant, die geben allenfalls Snippets weiter und die vorherige Prüfung, ob der jeweilige Nutzer gewerblich ist, ist dann doch etwas viel verlangt.
Interessant wäre das allenfalls für Aggregatoren mit zahlenden (meist gewerblichen) Kunden. Für diesen Spezialfall ist das LSR aber überdimensioniert.
und in einem weiteren kommentar, in dem er sich selbst zitiert und ergänzt:
“Sie könnten auch das von mir skizzierte technische Zweistufenmodell verwenden: Wer ACAP unterstützt, darf zu den damit definierten Bedingungen, wer nicht, wird mit robots.txt/Meta-Tags ausgesperrt.”
Inzwischen weiß ich, daß der ACAP-Standard sogar schon einen Schalter enthält, der genau das tut (Ignorieren der robots.txt-Definitionen nach bisherigem Standard).
Dieser Schalter ergibt natürlich nur Sinn, wenn die Autoren von ACAP damit rechneten, daß eben nicht alle Suchmaschinen und Aggregatoren den ACAP-Standard unterstützen würden.
das acap-protokoll, auf das sich keese bereits einmal in aller länge bezogen hatte, lohnt sicher einen weiteren blick. ich frage mich aber, warum der axel-springer-verlag das protokoll nicht einfach nutzt. es ist abwärtskompatibel und die implementierung dauert laut acap-website keine 30 minuten.
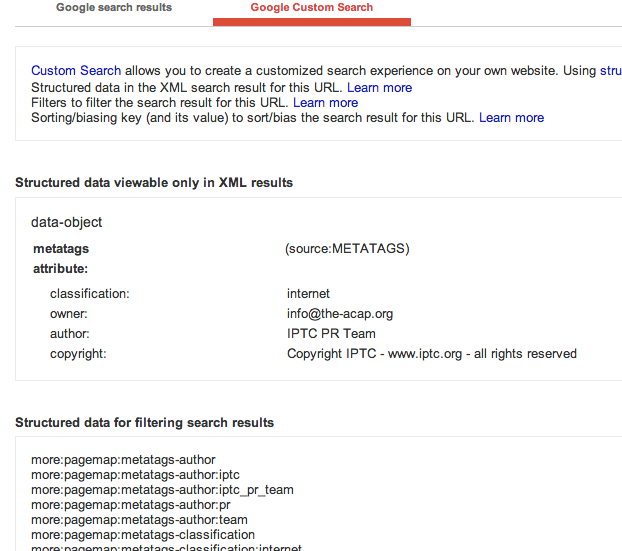
und zumindest google liest die strukturierten daten des acap-protokolls durchaus ein, wie man in googles rich snippet tool sieht (klick auf „Google Custom Search“):