geschenke

zusage
ich habe heute mehrere geschenke bekommen, über die ich mich sehr gefreut habe.
eine email
Am 16.03.2026 um 15:27 schrieb programme@re-publica.com:
Liebe*r Felix Schwenzel,
Vielen Dank für deine Einreichung für die re:publica 2026.
Wir freuen uns sehr, dir mitzuteilen, dass deine Session "Die Welt ist scheisse — und das ist auch gut so" für das Programm der #rp26 angenommen wurde!
hier hab ich vor zwei monaten meinen vortragsvorschlag veröffentlich. neben der freude überwiegt die furcht vor der arbeit. ich fürchte das bedeutet in den nächsten zwei monaten weniger fernsehen und mehr lesen und schreiben.
neue firmware für unseren staubsauger
gefühlte 10 jahre nach der ankündigung hat dreame unserem x50 das matter-update geschickt. das heisst unter anderem, dass der staubsauger jetzt auch nativ in der apple home.app zu sehen und zu steuern ist. das ging zwar auch schon vorher mit der grossartigen dreame-vacuum custom component, aber jetzt nen ticken einfacher und eben nativ.
eigentlich ist der plan — wie bei aller gut gemachten heimautomatisierung — dass man von dem gerät gar nichts mitbekommt. wenn ich morgens auf den morgenspaziergang gehe und die beifahrerin noch im bett bleibt, fährt der roboter los und putzt zuerst die küche. wenn dann noch zeit ist, probiert er es im bad und wenn da die tür zu ist, den flur. sobald ich nach hause komme oder die beifahrerin aufsteht, fährt er zurück in seine station und macht sich sauber. das klappt soweit auch ganz gut, aber manchmal steht die beifahrerin tagelang früher auf und die küche verdreckt dann. wenn die beifahrerin reinigungen dann mal manuell anstossen wollte, klappte das oft nur holprig, weil meine arbeitsanweisungen (scripte) nicht immer aktuell waren oder der dreame und seine KI einen schlechten tag hatten.
mit dem neuesten firmwareupdate (4.3.9_2199) sieht das nach ersten tests ganz gut aus. er scheint sich ein bisschen selbstsicherer in der wohnung zu bewegen und scheint sich nicht so schnell von störungen aus dem konzept bringen zu lassen. vor allem kann man aber jetzt auch eine reinigung direkt aus der home.app anstossen.
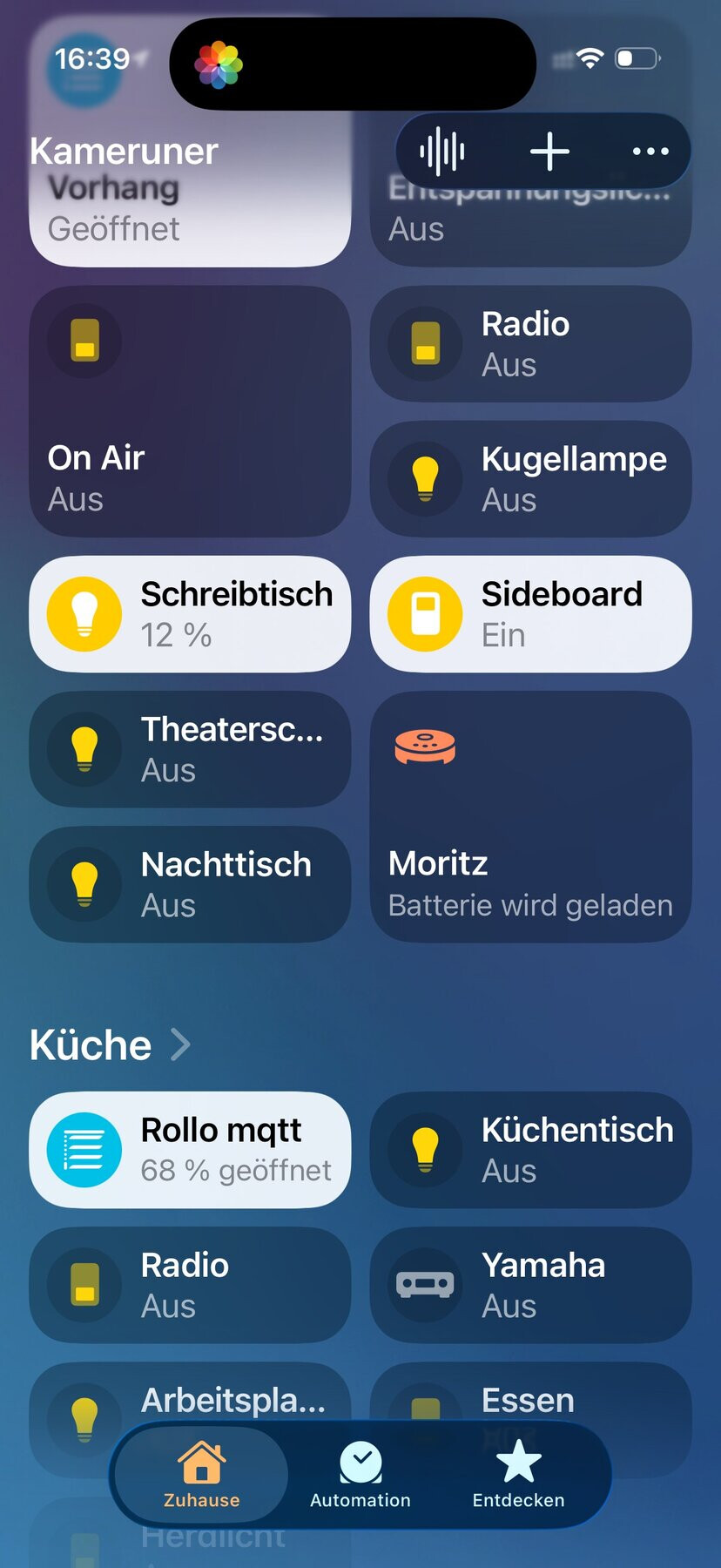
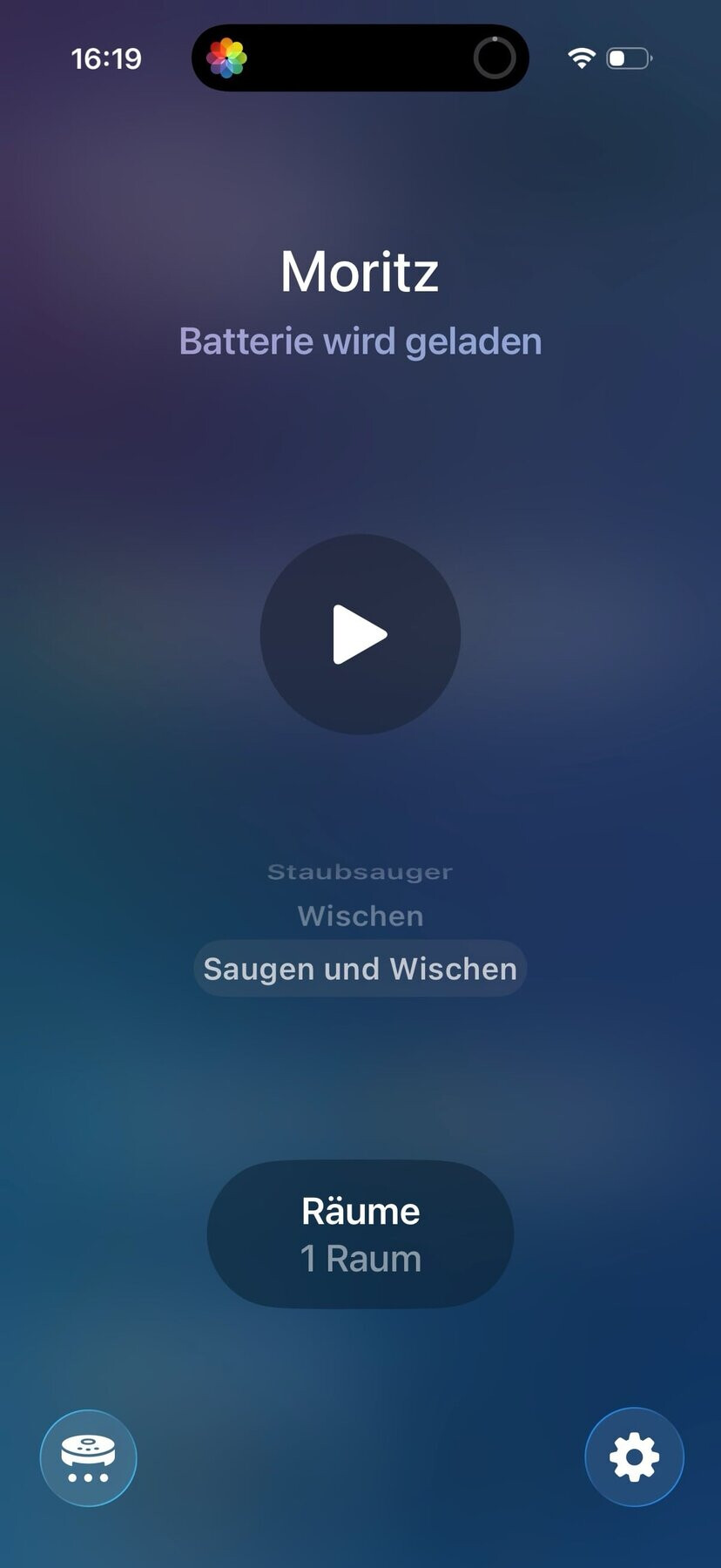
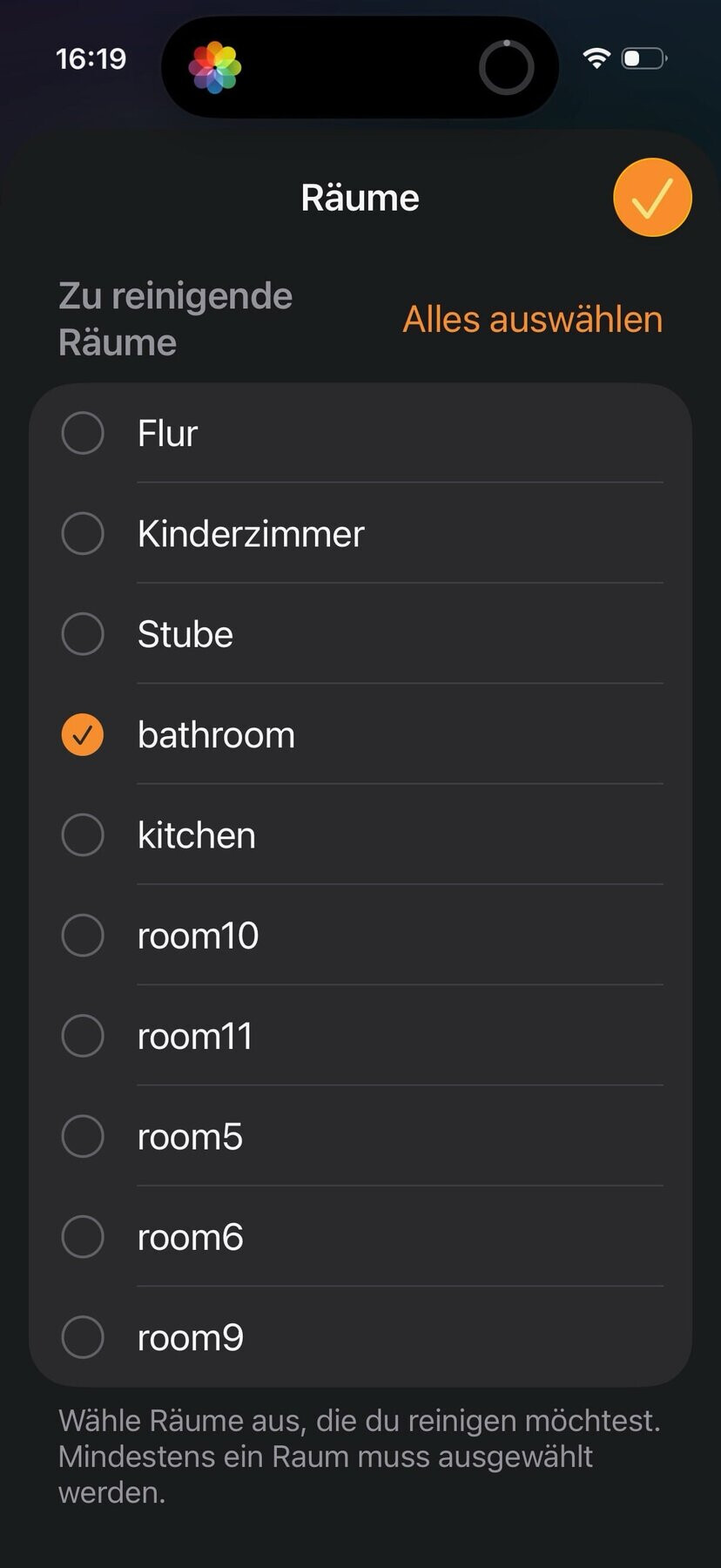
und home assistant beherrscht mittlerweile bei matter-fähigen saugern auch die raumzuordnung und sogar die reinigung einzelner räume lässt sich mit aktionen mit matter starten.
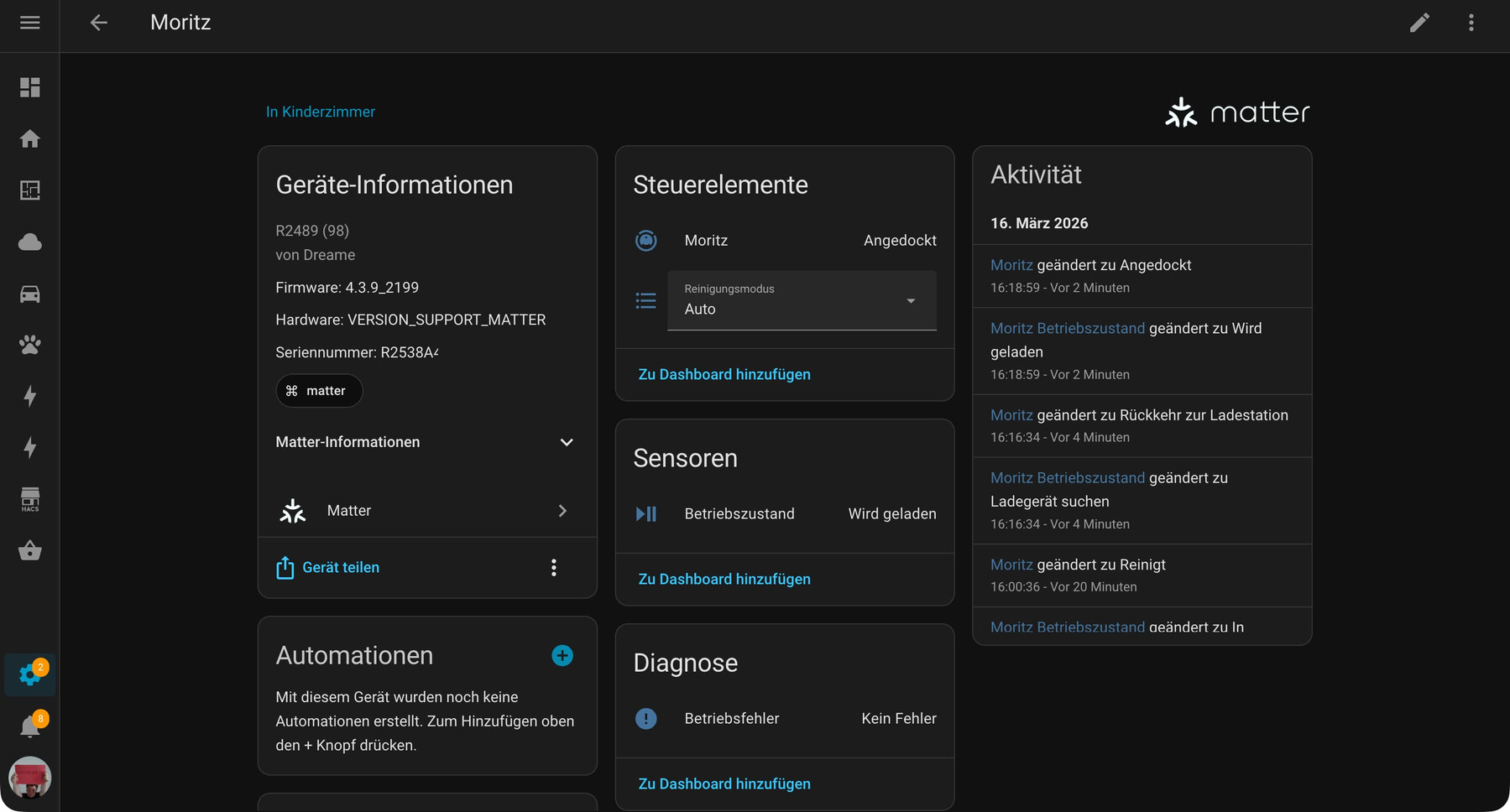
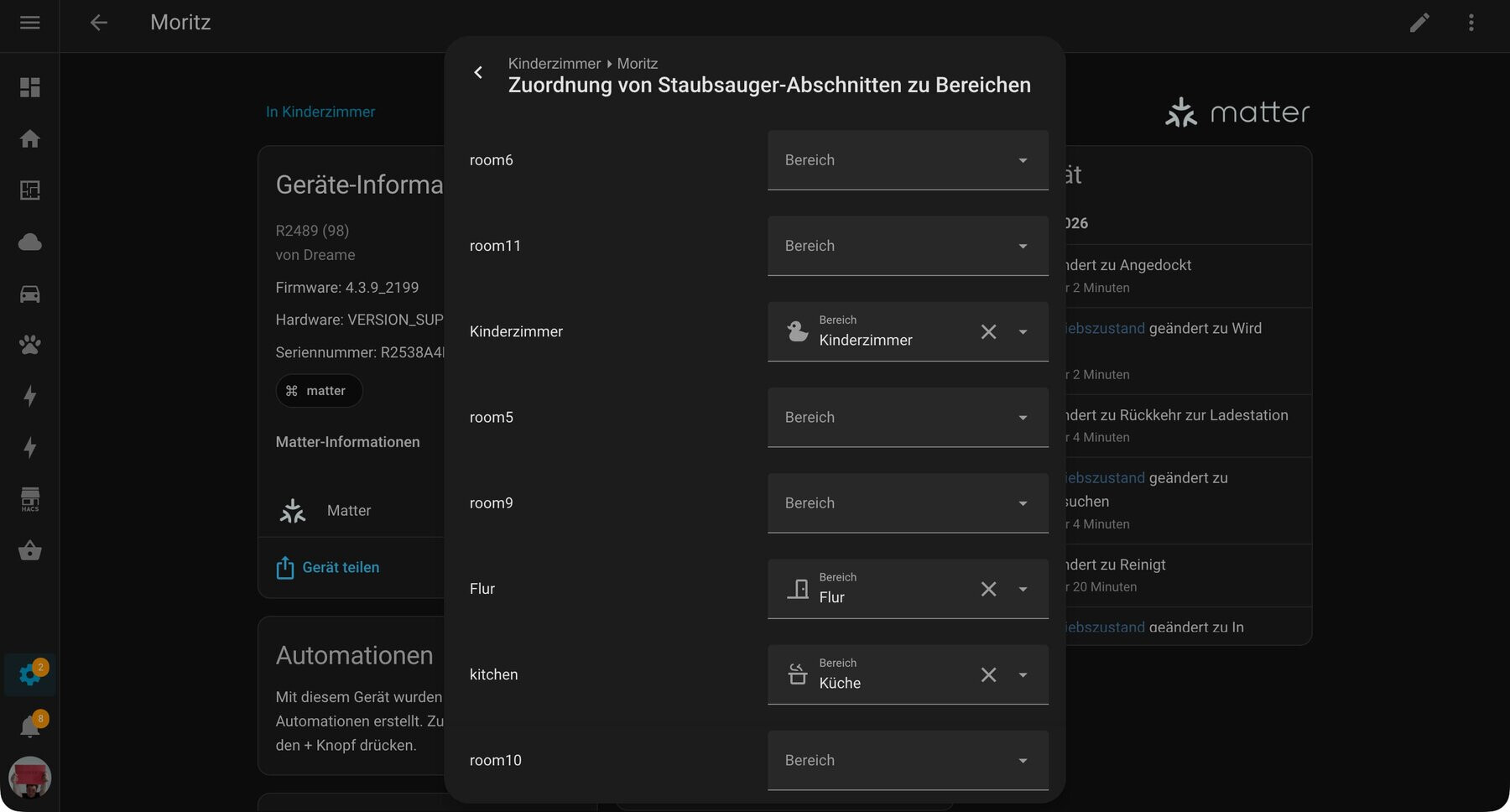

ein eher sisyphosesques geschenk, schenkte mir gestern nacht die matter-integration von home assistant. die matter integration funktioniert im prinzip sehr zuverlässig: docker container hochfahren, integration hinzufügen fertig. aber die teufel stecken wie immer im detail — oder genauer im netzwerk. wenn schon in der doku steht, dass es kompliziert ist, wird’s kompliziert:
Matter is based on IPv6 link-local multicast protocols and thus running the Matter Server (or developing it) is not as straightforward as any other application, mostly due to the bad shape of IPv6 support in various Linux distributions, let alone the IPv6 Neighbor Discovery Protocol, which is required for Thread.
nachdem meine (wenigen) matter geräte jetzt monatelang stabil liefen, verschwanden sie gestern nacht alle. die fehlermeldungen waren kryptisch aber meine coding assistenz schlug irgendwann vor folgendes auf dem docker-host zu machen:
sudo sysctl -w net.ipv6.conf.eno1.accept_ra=1
sudo sysctl -w net.ipv6.conf.eno1.accept_ra_rt_info_max_plen=64
damit ging es dann wieder.
und wenn’s funktioniert, dann ist dieses matter schon toll!
ein buch
die beifahrerin hat mir ein selbstgeschriebenes buch geschenkt. oder genauer, einen ausdruck einer längeren unterhaltung mit chatgpt um (vergeblich) ein geschenk für mich zu finden. das ist sehr lustig, auch weil chatgpt im laufe der unterhaltung alle möglichen sachen vorschlägt, die ich schon lange habe, ein cheap yellow display für wetteranzeige, e-paper displays für status-anzeigen, esp-32 bastelkits, mmw sensoren, hardware buttons für home assistant — oder „Matter-fähige Geräte (neuer Smart-Home-Standard)“.
obwohl, ein stream-deck mini hab ich noch nicht.










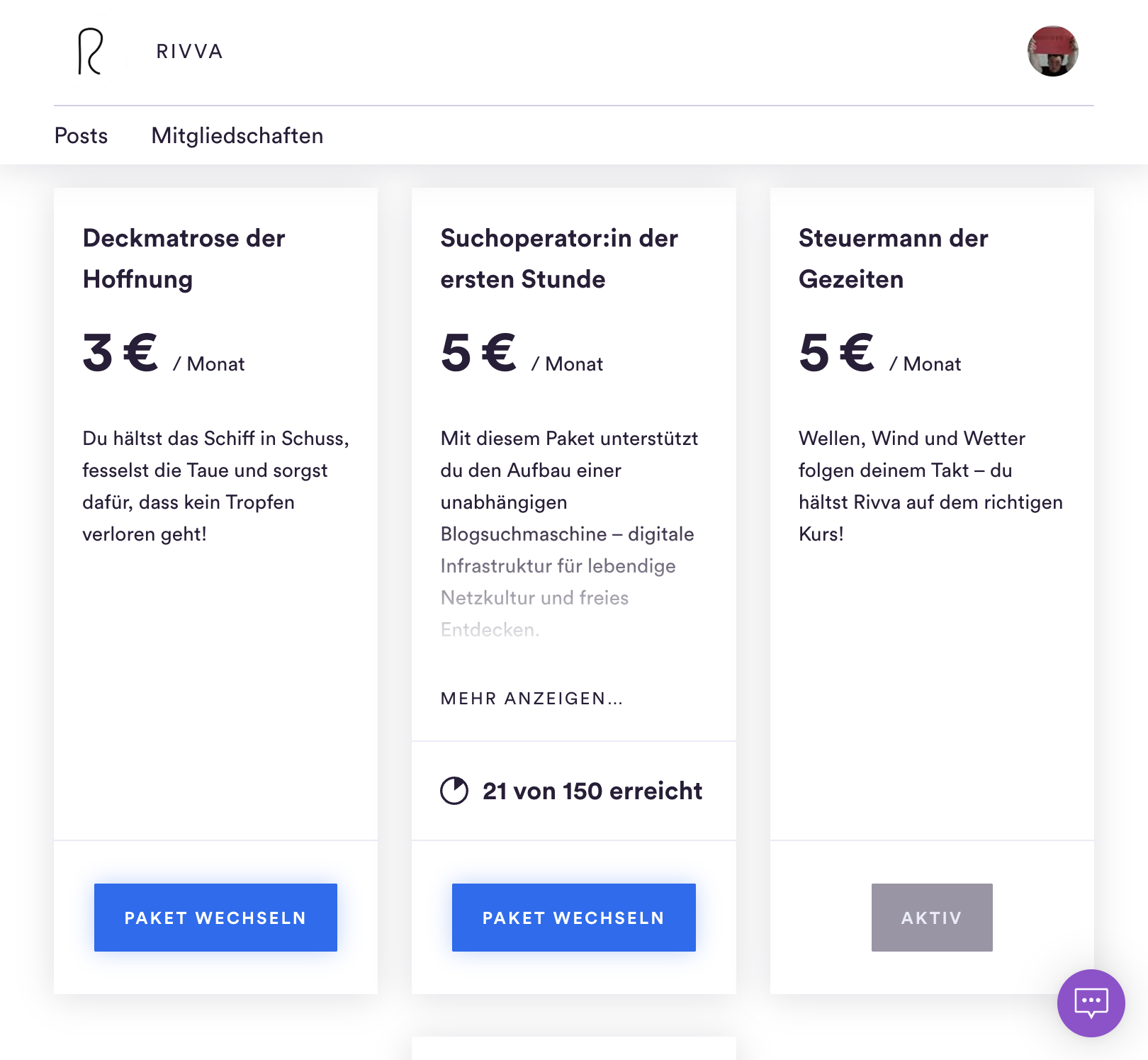











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
vor ein paar tagen habe ich eine kurze doku zu pottwalen verlinkt, dieser clip von „Nightshift – Kurzgesagt After Dark“ ergänzt das thema sehenswert aus der historischen perspektive.