ich mal wieder aus dem maschinenraum. ich habe heute früh die DNS-einträge für wirres.net auf eine hetzner IP umgestellt, nachdem ich innerhalb von wenigen stunden die ganze site auf eine neue hetzner VM migriert habe. die migration war wirklich einfach:
bei hetzner eine VM einrichten, etwas an der ssh-konfig drehen und docker installieren
rsync von 10 GB daten
docker container hochfahren
fertig
natürlich gabs danach noch ein paar kleinigkeiten geradezuziehen, aber das schöne ist, wirres.net ist damit einerseits prima und komlett mit einem rsync zu backuppen oder zu migrieren und die gesamte serverlogik (apache, php, opcache, etc.) steht (jetzt) in einer docker-konfiguration, die sich theoretisch überall deployen lässt.
soweit scheint mir, dass alles funktioniert. die performance schien am anfang ein paar mal kurz am anschlag, auch wenn die anzahl der CPU kerne und RAM auf dem papier die gleichen sind, scheint es mir, als sei die hetzner-VM etwas schwachbrüstiger. ich beobachte das weiter und falls euch etwas auffällt was nicht funktioniert oder klemmt, lasst es mich wissen. aber ich sehe auch hier mal wieder warum kirby so ♥️ ist.
ich liebe youtube. also nicht youtube an sich, aber videos auf youtube zu sehen. im monat zähle ich ungefähr 50 stunden, die ich vor der tube sitze. ich habe auch grossen respekt vor dem algorithmus der mir die videos zusammenstellt. die mischung der videos ist interessant genug um mich bei der stange oder tube zu halten, aber ich bekomme trotzdem keine schwurbler-videos vorgesetzt oder videos in die timeline gespült, nur weil sie gerade „trenden“ oder so. youtube ist meine guilty pleasure, mein gar nicht mal so heimliches laster1.
wer den videos die ich mag folgen will, alle videos, unter die ich einen positiven daumen setze, landen im favoriten stream (RSS).
als ich gestern ein video von der 2MR Konferenz sah, habe ich zunächst gar nicht gemerkt, dass es kein youtube-video war, saondern auf peertube lag. um es so auf wirres.net einzubetten wie ich es mag (ohne explizite freigabe kein fremdcode oder iframe oder javascript von drittservern), musste also ein neuer embed block her. cursor und claude konnten das schnell umsetzen und das funktioniert auch, wenn ich ein peertube-video fave (beispiel).
soweit das neue aus dem maschinenraum.
was mir dann aber noch auffiel: ich muss mich bei jeder peertube-instanz separat anmelden, wenn ich dort übeer den browser einen echten fav hinterlassen will. das ist ja eigentlich bei allen fediverse instanzen so, egal ob mastodon oder gotosocial oder pixelfed. im browser stehe ich immer dumm unangemeldet da. ich weiss, ich kann die url der peertube seite in meinem mastodon client im suchfeld eingeben und dann interagieren (faven, kommentieren), aber warum dieser umweg? im indieweb gibts indieauth was wirklich einfach zu nutzen ist und mit dem man sich über die eigene webseite anmelden kann. das ist so dezentral wie es nur sein kann und ich frage mich, warum können fediverse instanzen nicht auch identity-provider sein? wenn ich mich an beliebigen fediverse instanzen, die ich im browser besuche, einfach so anmelden könnte um dort zu interagieren, wäre das aus meiner sicht ein echter fortschritt in sachen bedienfreundlichkeit und konsistenz. oder übersehe ich etwas? gibts das schon? oder ist das komplizierter als ich gerade denke?
ich gucke youtube werbefrei in safari, ohne youtube dafür geld in den rachen zu werfen. der trick ist eine safari erweiterung namens vinegar. vinegar tauscht einfach den youtube-player mit dem nativen browser-player aus und umgeht damit die werbung. das funktioniert so gut, dass youtube in meiner anseh-historie sogar werbeclips anzeigt, die ich angeblich gesehen hätte, aber nie gesehen habe. das heisst im umkehrschluss, den youtube-kreatoren entgehen dadurch keine werbeeinnahmen und ich muss den scheiss nicht sehen. ↩
hier schreibt felix schwenzel seit 24 jahren gerne ins internet (eigentlich seit 30 jahren).
von 23 auf 24, bzw. 29 auf 30 umgesprungen, weil der erste artikel den ich hier veröffentlicht habe vom 20.04.2002 ist. mir sind diese jahrestage eigentlich nicht wichtig, aber statistiken mag ich gerne. deshalb betätige ich mich mal eben als statistik-chronist.
wahrscheinlich wäre es mittlerweile besser, unten hinzuschreiben, dass ich jetzt schon „sehr lange“ ins internet schreibe. bei solchen zeiträumen ist der genaue tag dann auch irgendwann egal, so wie mir die kalendarischen koordinaten meiner geburtstage nach fast 60 jahren mittlerweile auch egal sind.
kirby nutze ich jetzt auch bereits seit über einem jahr („hallo kirby“). ich bereue den umstieg nicht, im gegenteil, kirby ist mir jeden tag erneut eine grosse freude.
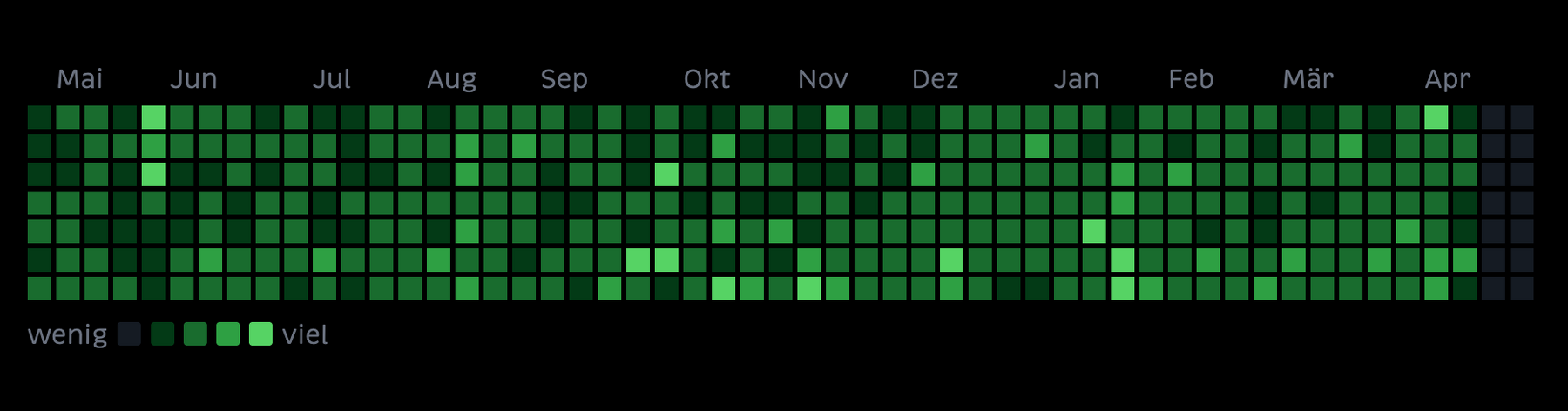
was ich jetzt auch seit fast einem jahr mache: jeden tag etwas veröffentlichen. der streak ist mittlerweile 359 tage lang. die anzahl-der-posts-übersichtgrafik auf der rückseite ist mittlerweile ohne schwarze punkte.
bemerkenswert an der grafik ist eigentlich nichts, ausser dass man kaum muster erkennen kann wie und wann ich wie viel veröffentliche. man erkennt allerdings ein cluster zwischen mai und juni: republica. so erkennt man: noch vier wochen bis zu #rp26. das minimalistische design dieses jahr gefällt mir sehr gut, hier meine „speaker-seite“ für dieses jahr. ende der durchsage.
als ich vor 23 jahren anfing mit einem content managment system ins internet zu schreiben, war ich in vielerlei hinsicht ein bisschen naiv. auch was die nutzung von bildern angeht. wenn schlechte witze (arnold schwarzegger hat schrankfarbene haare) die nutzung eines bildes erforderten, suchte ich mir ein bild und benutzte es. 2002 wurden urheberrechtsverstösse eher selten geahndet und google war gerade mal 4 jahre alt.
spätestens zu zeiten von marions kochbuch (die älteren werden sich erinnern) fing ich an mein archiv für suchmaschinen zu verrammeln. bei artikeln die älter waren als 5 jahre verbot ich die suchmaschinen indexierung. das hat soweit gut geklapt. in den > 20 jahren in denen ich ins internet schrieb habe ich zwar die eine oder andere abmahnung bekommen, aber nie wegen urheberrechtverstössen. bis heute. ein foto von arnold schwarzenegger das seit 20 jahren im web rumlag, ausgeschlossen von suchmaschinen-indexierung und ungesehen von jeder menschenseele, wurde doch von irgendeinem rechteinhaber gefunden. die seite, auf der das bild laut anwaltsschreiben zu sehen gewesen sei, war von der suchmaschinenindexierung ausgeschlossen und damit im prinzip unsichtbar. ich weiss zwar, dass ethisch fragwürdige crawler sich nicht an robots.txt anweisungen halten, aber dass möglicherweise für die durchsetzung von urheberrechten auch solche anweisungen ignoriert werden, scheint neu zu sein.
die 250 € habe ich überwiesen, das bild gelöscht und den artikel entfernt und gleichzeitig habe ich alle bilder von artikeln die älter als 2010 sind mit thumbhash bildern ersetzt. thumhashs sind „very compact representations of an image“, die gerade mal ein paar byte gross sind. die nutze ich schon länger fürs lazyloading, man bekommt die also zu sehen wenn man wirres.net mit einer sehr langsamen internetverbindung besucht. ansonsten sieht man die nur selten. hier eine beispielseite aus meinem archiv.
die riesenmaschine macht das schon lange so mit bildern, deren rechtelage ungeklärt ist: einfach weglassen.
aber nur wegen eines anwaltschreibens soll mein archiv nicht weniger bunt sein. deshalb finde ich meine lösung, bilder erstmal pauschal auf wenige bunte byte zu reduzieren sehr schön. und artikel mit bildern, über deren rechte ich mir im klaren bin (zum beispiel weil ich die bilder selbst aufgenommen habe), kann ich von der thumbhashisierung ausnehmen, aber das ist ein manueller vorgang.
so hat die abmahnung auch was gutes: ein schönes neues feature, von dem ich aus dem maschinenraum berichten kann.
es gibt auch sonst einiges neues aus dem maschinenraum. zum beispiel neue feeds für den river, die favoriten, bookmarks oder was ich gesehen habe (alle feeds sind autodiscoverable oder hier aufgelistet). unter /alles sieht man jetzt auch wieder wirklich alles, ebenso im alles-feed. auch im archiv sieht man beiträge, favs, bookmarks und gesehenes jetzt einzeln aufgeschlüsselt — oder eben als alles.
das logbuch meines medienkonsums, das ich dieses jahr führen möchte habe ich um die youtube sehzeiten erweitert. derzeit steht mein medienkonsum bei ca. 70 stunden pro monat die ich vor der glotze verbringe. ich bin mal gespannt wie sich das oder ob sich das über das jahr verändert.
und apropos gewohnheiten, die man offenbar mit zunehmensdem alter liebgewinnt, mal schauen ob mir entwicklung der gewohnheit gelingt, diesen baum ein jahr lang jeden tag zu fotografieren.
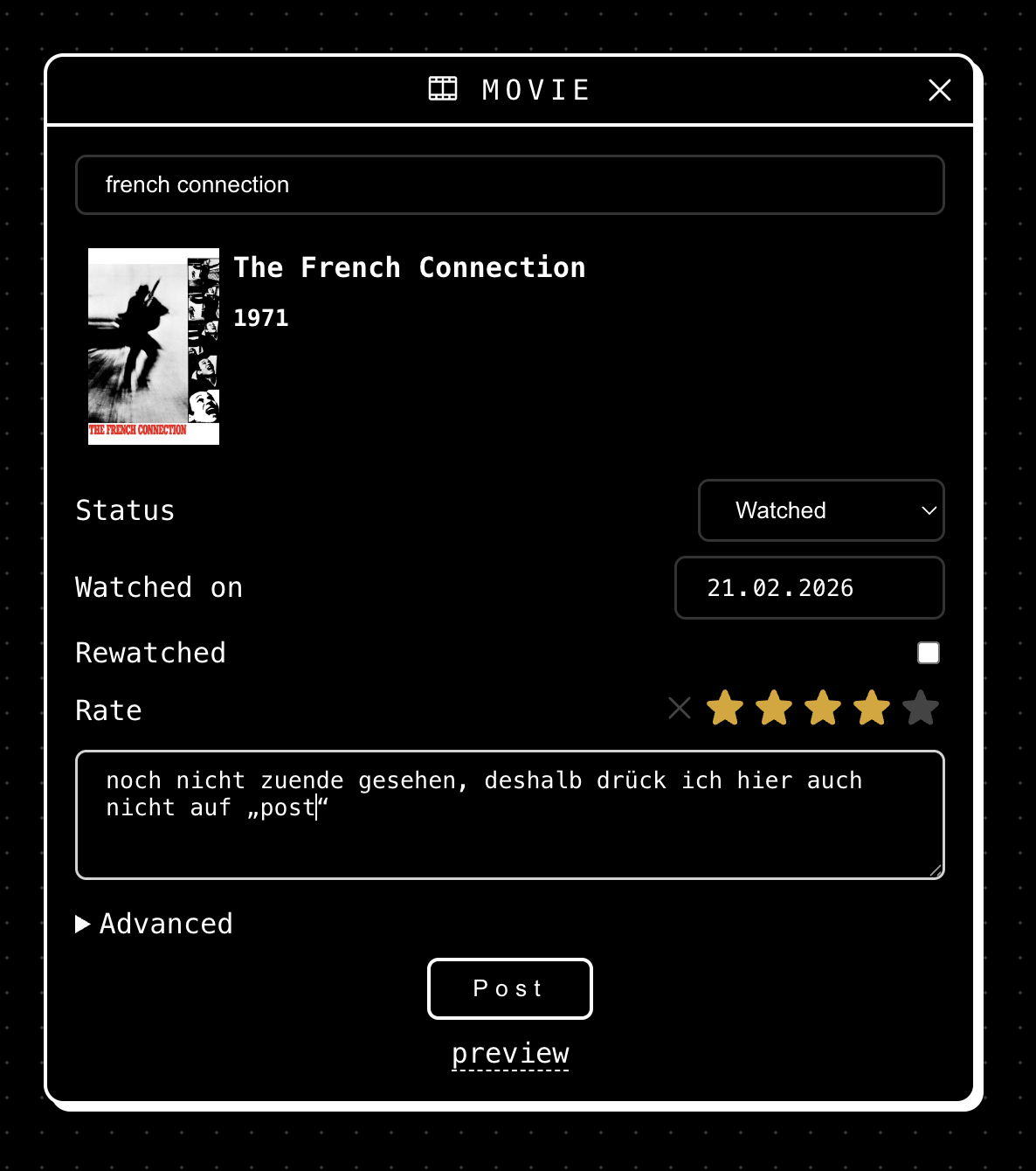
natürlich ist es eine schnapsidee, filme oder serien hier tracken zu wollen. wenn ich wollte, könnte ich das alles bei trakt machen. trakt arbeitet mit einem leicht obskuren dritt-dienst zusammen (younify.tv) um die historie des gesehenen von netflix auszulesen. tatsächlich kann man damit die historie aller grossen streaming-angebote abgreifen — wenn man younify.tv genug vertrauen entgegenbringt und (vollen) zugriff auf diese dienste gewährt. mein vertrauen hat vor ein paar jahren nur dafür gereicht, younify.tv zugriff auf mein netflix-konnto zu gewähren, weshalb ich jetzt einen teil meiner netflix-historie auch in trakt habe.
der vorteil ist, dass ich die von younify.tv abgegriffenen daten, jetzt auch wieder über die trakt-api selbst abgreifen kann, zum beispiel mit diesem script. mit ein zwei weiteren phyton scripten kann ich deshalb jetzt auch automatisch auf netflix gesehenes hier loggen.
schnapsidee hin oder her, sowohl trakt als auch ich wissen, dass die schnapsidee alles gesehene zu loggen, nur funktioniert, wenn es vorwiegend automatisch geht. wenn da nicht die vertrauensfrage wäre. ein datenleck bei trakt von 2014, das trakt erst 2019 offenlegte, zeigt, dass es nicht angebracht ist, trakt 100% vertrauen zu schenken. wenn ich mich recht erinnere hab ich die verbindung zwischen trakt und plex schon vor 2019 gekappt, weil mir das einen ticken zu unheimlich war, meine plex-historie ungefiltert in trakt zu leiten. bei netflix hielten sich meine bedenken in grenzen.
mit meinem selbstgebauten plex/tautulli-zu-kirby-exporter behalte ich die kontrolle und der import in die öffentliche liste klappt auch ohne drittanbieter ganz gut, fast vollautomatisch. ich muss nur noch eine wertung nachtragen.
und auch wenn ich bei der netflix → younify.tv → trakt.tv → wirres.net konstruktion weniger bis keine kontrolle habe, wollte ich diese automatisierungs-pipeline jetzt testen. dafür musste ich mir natürlich irgendeinen scheiss auf netflix ansehen.
also hab ich mir die erste folge being gordon ramsay angesehen. ich vermute das wird weder so erfolgreich wie netflixchefs table noch so ein hit wie drive to survive — auch wenn das strickmuster ähnlich ist. beim überfliegen der kritiken ist eine überschrift hängengeblieben, der ich direkt zustimmen möchte: gordon ramsay should not be so boring.
jedenfalls funktioniert der sync zwischen netflix, younify.tv, trakt.tv und wirres.net/kirby, wenn auch mit leichter verzögerung.
zum thema ex- und importe: ich habe auch ein script gefunden, mit dem sich die daten aus tautulli, also plex, mit letterboxd syncen lassen. damit habe ich jetzt lücken meiner film-timeline auf letterboxd geschlossen, auch wenn die timeline der filme die ich jemals sah auf letterboxd immer noch lücken in den letzten 10 jahren hat. schliesslich schau ich filme ja nicht nur auf plex, sondern auch auf amazon prime, im kino (gelegentlich) oder netflix. aber weils geht, weil ich daten jetzt aus plex und netflix rausbekomme, erscheint es mir logisch meine film-historie erstmal auf letterboxd zu vervollständigen. dann kann ich sie auch wieder hierher holen. aber bevor ich das mache sammel ich hier, bis auf ein paar ausnahmen — zu testzwecken — erstmal vornehmlich in 2026 gesehenes und gelesenes.
mit so einer „datenbank“ für gesehenenes und gelesenes setze ich mich übrigens auch geschickt selbst unter zugzwang. jetzt muss ich auch mal wieder ein buch lesen, damit ich es loggen kann. und damit schliesst sich der zirkel: ausgehen um drüber schreiben zu können, scheisse auf netflix schauen, ums zu prüfen ob es automatisch geloggt wird. morgens spazieren gehen um das wetter zu fotografieren und fotos und .gpx-tracks zu posten, kochen um rezepte maschinenlesbar zu veröffentlichen, schlafen, um zu sehen, wie gut der schlaftracker funktioniert. (b)loggen weil’s geht.
eben habe ich die graham norton show gesehen, um zu gucken ob sie danach automatisch hier im blog auftaucht. tat sie.
die idee hatte ich gestern: warum nicht alle sendungen die ich gucke hier mit einem kurzen eintrag festhalten? am besten automatisch. also mach ich das jetzt.
ich mag die idee von micro-einträgen. das erzeugt zwar eine menge rauschen, aber das lässt sich auch gut ausblenden. bei bedarf lassen sich diese einträge aber auch auswerten oder für was auch immer mir einfällt verwenden. vor allem aber mag ich die idee, dass alles hier passieren zu lassen, hier also sozusagen life-logging zu betreiben. das ist ja auch was weblog ursprünglich bedeutete: sachen öffentlich, im web loggen. jetzt wo ich likes und lesezeichen hier logge, kann ich doch auch loggen was ich (fern-) sehe.
die idee mochte ich schon lange, nur stand mir die technik nicht zur verfügung. deshalb habe ich jahrelang watched.li von philipp benutzt. ich fand es in erster linie spannend zu sehen, wie viel zeit ich vor der glotze verschwende, aber watched.li half auch dabei zu vorrauszusehen, womit ich in zukunft meine zeit verschwenden konnte, welche serien und folgen bevor standen.
seit 10 jahren nutze ich neben plex auch noch tautulli, eine freundliche plex-begleit-app. im prinzip macht tautulli nichts anderes als plex zu beobachten und alles zu loggen: wer schaut wann was, was macht der server, was gibt’s neues? wenn ich zurück zu 2017 gehe, sehe ich, dass ich am 14. august 2017 game of thrones s07e05 gesehen habe. um 22:43 war ich fertig mit der folge (ist game of thrones echt schon so lange her?).
mit tautulli hab ich als eigentlich alles was ich brauche: statistiken, details zu dem was ich (mit plex) gesehen habe.
andererseits nutze ich ja nicht nur plex. ich schau gelegentlich filme im kino, auf amazon prime, netflix oder RTL+. ich bin auch nicht der einzige, der den wunsch hat das alles zu tracken. heiko hat vor ner weile beschrieben, wie er seinen medienkonsum trackt: Medien-Tracking mit Github und YAML. thomas hat sich einen recorder gebaut, mit dem er alles was er sieht und liest festhält und bewertet. und jetzt hab ich mir in den letzten 24 stunden ein medienmenü zusammengehackt. ich hab mir vorgenommen das mal ein jahr lang auszuprobieren, also wirklich alles was ich sehe oder in buchform lese festzuhalten. was ich im netz lese halte ich ich ja bereits mit lesezeichen fest.
die technik dahinter finde ich betörend einfach: für jede serienfolge, film oder buch, lege ich einen beitrag mit den wichtigsten daten an: (von) wann, was, wie lange und wie wars? die beiträge kann ich ganz normal in kirby als content anlegen, aber auch per per webhook oder per micropub.
den webhook sendet tautulli sobald ich einen film oder serienfolge zuende gesehen habe und sieht so aus:
mit dem micropub-client sparkles kann ich gesehene filme anlegen.
die übersicht habe ich heute mit allem was ich 2026 gesehen habe gefüllt. die wenigen filme, die ich gesehen habe, mit sparkles, die serien manuell mit einem curl.
mit dem curl ging das ziemlich effizient, künftig sollte der grossteil der einträge dann automatisch aus plex/tautulli kommen, den rest pflege ich dann eben manuell nach, bis ich dafür auch eine automatisierung finde.
im prinzip ist die übersicht ein (h-) feed, den man theoretisch auch abonnieren könnte, aber da muss ich mir noch was überlegen, wie man das in einen sinnvoll rauschenden rss- oder atom-fluss umwandelt.
als nächstes werde ich versuchen ein paar tagesaktuelle statistiken zu erzeugen. ich finde man kann in der übersicht auch schon so einiges ablesen:
gelegentlich binge ich serien weg
starfleet academy hab ich nach folge 6 nicht mehr ertragen und aufgehört weiter zu sehen
ich finde A Knight of the Seven Kingdoms richtig gut
obwohl The North Water ziemlich gut ist, bin ich in folge 2 hängen geblieben
nachem ich mir gestern eine möglichkeit geschaffen spaziergänge als .gpx-dateien hochzuladen und darzustellen, habe ich mal geschaut, ob ich sowas schon früher versucht habe. dabei habe ich diesen alten artikel von 2015 gefunden, der zwar eine gpx-datei erwähnt, aber nicht beinhaltet. stattdessen fiel mir auf das der artikel ein paar fehler enthielt. die videos funktionieren nicht, asides werden mittig, statt am rand angezeigt und die fotos hatten noch keine expliziten lizenz-informationen. meine imports vom alten blog in kirby funktionierten eigentlich ganz gut, aber bei einzelen details klemmte es dann doch immer wieder, auch weil ich zum zeitpunkt des ex- und imports in kirby noch nicht alle features abgebildet hatte.
beim reparieren des artikels, fiel mir dann noch auf, dass die importierten fotos tatsächlich noch ihre exif-daten in sich trugen, also lud ich die auch nach. mit den exif-infos war es kirby dann möglich automatisch eine karte der foto-orte zu generieren, die sich dann erfreulicherweise fast so aussah wie die karte, die ich vor 10 jahren aus einer .gpx-datei generiert hatte, damals boch bei einem externen dienst, der längst das zeitliche gesegnet hat.
das freute mich sehr, denn so war der alte artikel nach der reparatur besser als vorher.
das dinge im netz kaputtgehen ist unumgänglich. auch die archive.org-version des alten artikels ist nicht mehr (oder war es nie) in ordnung. deshalb, lesson learned, ist es wirklich sinnvoll alle daten, originale bei sich zu behalten, man weiss ja nie wozu sie gut sein werden. und es ist immer sinnvoll dinge ohne harte externe abhängigkeiten zu bauen. das heisst nicht, dass man nicht auch mal externe dienste nutzen soll oder inhalte dorthin aggregieren oder syndizieren sollte, sondern eben, dass man es im ernstfall eben auch selbst machen kann, ohne abhängig von einem dritten zu sein.
deshalb freue ich mich auch so einen weg gefunden zu haben eine gpx-datei hier lokal darzustellen. mit komoot könnte ich sowas per iframe einbetten, aber dann habe ich einerseits eine abhängigkeit und andererseits tracking-codes eines dritten auf meinen seiten.
andererseits spricht nichts dagegegen touren, wie die wanderung um den „de meinweg“ weiterhin mit komoot aufzuzeichnen und dort zu teilen, so lange ich sie auch als gpx exportieren kann. genau diesen export hab ich jetzt im alten artikel über die wanderung nachgepflegt. wenn dann in 30 jahren komoot nicht mehr ist, hab ich immer noch alle wesentlichen daten bei mir.
seit ich angefangen habe bookmarks (und likes) bei mir zu sammeln (bookmarks, likes, replies, alles zusammen, wirklich alles), statt in pinboard, sende ich mit diesen lese- oder like-notizen auch webmentions an die betreffenden seiten. die meisten ignorieren das aus technischen gründen (weil sie keine webmentions unterstützen), aber manche nehmen die benachrichtigung entgegen. eay.cc zum beispiel, da wurden meine bookmark-webmentions dann aber komisch dargestellt, also hat er das repariert und spass dabei gehabt.
oder gestern habe ich crowdersoup.com einen kommentar geschickt. der wurde angenommen aber jetzt muss das layout offenbar repariert werden. bei beiden war ich offenbar der erste, der sowas geschickt hat und ehrlichgesagt bin ich hier auch nicht auf alle webmention-arten vorbereitet, die mir potenziell geschickt werden können.
aber das ist eben teil des spass: build & repair as you go, probleme dann lösen, wenn sie daherkommen. oder anders gesagt: eine webseite ist eine baustelle die wirklich kein ende hat — und das ist auch gut so.
ich weiss gar nicht mehr wie ich crowdersoup.com entdeckt habe, aber ich vermute über indiewebnews. den beiträgen dort folge ich seit kurzem wieder intensiver und komme dadurch vermehrt auf webseiten die sich mit den technologien des indiewebs auseinandersetzen — oder genauer: damit ringen. der gleichzeitige vor- und nachteil der indieweb-idee ist, dass es kaum fertige lösungen gibt und man sich eigentlich alles selbst zusammenbaut. das ist ein segen und ein fluch und ich verfluche die komplexität dieses indiwweb-gedöns auch regelmässig, um dann doch immer wieder einen neuen versuch zu starten.
diese definition von marty mcguire umschreibt die idee des indieweb ganz gut, vor allem was es ist und eben nicht ist:
indieweb.org is not a presciption or a cookbook or an exercise plan. It doesn’t tell you how to “be IndieWeb”. It’s a collective memory of experiments, some successful and some not, from a group of experimenters that has changed greatly over time.
was mir aber, abgesehen von den philosophischen fragen, heute auffiel: die idee des indiewebnews-aggregators kann man eigentlich weiterspinnen. indiewebnews ist ein aggregator in dem man sich selbst einträgt, einfach indem man indiewebnews verlinkt und dann ein webmention an indiewebnews sendet (anleitung auf deutsch bei news.indieweb.org/de). dieses vorgehen macht die seite nicht 100% spam-resistent, aber mit ein bisschen moderation könnte man daraus eigentlich sehr schöne aggregatoren zu allen möglichen themen bauen. wie gesagt, seit ich den englischen kanal der indiewebnews näher verfolge, habe ich viele neue, interessante webseiten/blogs gefunden die interessante sachen schreiben oder bauen oder zeigen. vielleicht könnte man so blog-themen-hubs bauen. mir fehlt leider die strukturierte phantasie um so ein konzept zu verfeinern, aber die discoverability und sichtbarkeit von blogs und webseiten zu verbessern ist ja ein erstrebenswertes ziel.
ich bin kein grosser fan von newslettern. mein newsletter ist RSS. ich habe sogar mal einen dienst benutzt, mit dem ich den tagesspiegel-checkpoint in einen RSS feed wandeln konnte. funktionierte dann allerdings irgendwann nicht mehr, wie fast alles um das man sich nicht selbst kümmert. um meine abonnierten RSS-feeds kümmere ich mich sehr intensiv. derzeit zählt mein miniflux 424 abonnierte feeds und 5298 ungelesene beiträge. ungelesene feed-items stressen mich nicht im geringsten. alle paar monate setz ich die einfach alle auf gelesen. RSS lese ich immer umgekehrt chronologisch. wichtiges schwimmt immer irgendwie nach oben oder erreicht mich auf anderen wegen.
andererseits glaube ich, dass nicht alle wie ich ticken. viele mögen podcasts, manche mögen newsletter. deshalb habe ich vor ein paar tagen angefangen mich nach diensten umzuschauen die RSS in e-mails umwandeln können. da gibt’s irgendwie nicht viele. ich dachte vielleicht kann steady sowas, aber leider pustekuchen. was selbstgehostetes wäre einerseits schön, andererseits ist email-versand etwas um das man sich doch sehr kümmern können muss und ein bisschen expertise mitbringen sollte. entgegen aller digitaler-unabhäng9gkeits-trends habe ich mich entschieden einen einfachen, automatisch generierten RSS-feed-newsletter mit hilfe des amerikanischen anbieters mailchimp zu bauen.
der werkzeugkasten von mailchimp erscheint mir auch in der kostenlosen version ziemlich gut. damit war es mir innerhalb von wenigen stunden möglich, eine ganz ok aussehnde version meines RSS feeds ins email-format umwandeln zu lassen. etwas besseres habe ich nicht gefunden, wem vergleichbare dienste bekannt sind: ich freue mich davon zu hören. jetzt geht erstmal mit mailchimp los.
täglich um 6 uhr morgens werden die, im vergleich zum vortag, neuen beiträge aus dem RSS feed dann per mail versendet. das tracking habe ich, soweit wie es in den einstellungen möglich war, deaktiviert, aber in den test-emails wurden weiterhin die links mit klick-trackern via us8.mailchimp.com verunstaltet.
eigentlich hatte ich als zielgruppe jemanden wie meine mutter für so einen newsletter im sinn. die liest seit einer weile wieder hier mit und eigentlich ist das auch die wurzel dieser seite. einerseits dient wirres.net mir dazu, dass ich mich an mein leben erinnere, andererseits habe ich damit angefangen ins internet zu schreiben, damit menschen die mir nahestehen die möglichkeit haben nachsehen zu können, was ich gerade so treibe oder denke.
irgendwann um die jahrtausendwende habe ich angefangen mit yahoo-groups regelmässig mails an freunde und bekannte zu versenden. dadrin stand schon damals eine wirre mischung aus blöden witzen, links und dingen die mir durch den kopf gingen. ein paar dieser mails habe ich archiviert. bitte nicht lesen!
irgendwann habe ich dann von push auf pull umgestellt. newsletter sind ja ein bischen pushy, wenn sie sich in die inbox drängen. RSS ist pull, man zieht sich das selbst in den leseapparat und kann das dann auch gut wegignorieren. aber wem’s gefällt, kann sich jetzt wieder einer push mechanik bedienen um wirres zu lesen: eepurl.com/jyHDZA
haha, sehe gerade: eigentlich sind nur 16 plätze frei. 500 emails darf ich mit dem kostenlosen mailchimp-tarif versenden. das sind ca. 16 × 31 mails. vielleicht mach ich nenn wöchentlichen newsletter draus? dreitägig? oder ich mach ne steady-seite auf um die 30 euro zu refinanzieren, die das nächst grösere paket bei mailchimp jostet? oder es interessiert sich ausser meiner mutter eh niemand für den newsletter?
ich weiss gar nicht genau warum, weil eigentlich ist es mir egal sachen richtig zu machen und wichtiger dinge so zu machen, wie sie mir gefallen. andererseits gibt es oft überschneidungen zwischen richtig und gefällt mir.
so gefällt es mir, wenn meine webseite in allen browsern und readern, die ich selbst gerne benutzte, gut aussieht. responsive design, also dass sich die webseite an die bildschirmgrösse anpasst, ist ja mittlerweile fast ein no-brainer. gelegentlich schaue ich mir meine website auch mit lynx an, einem textbasierten kommandozeilen-browser. damit sieht man dinge, die normale browser nicht zeigen, die aber trotzdem von manchen menschen oder maschinen, die die website besuchen, so gesehen werden kann. genauso gerne rufe ich meine webseite gelegentlich mit deaktiviertem css auf. beide, lynx und kein-css zeigen potenzielle probleme, die ich wegoptimieren oder aufschieben kann.
lynx browser zeigt wirres.net
chrome zeigt wirres.net ohne CSS
ansichten diese seite mit lynx und ohne css
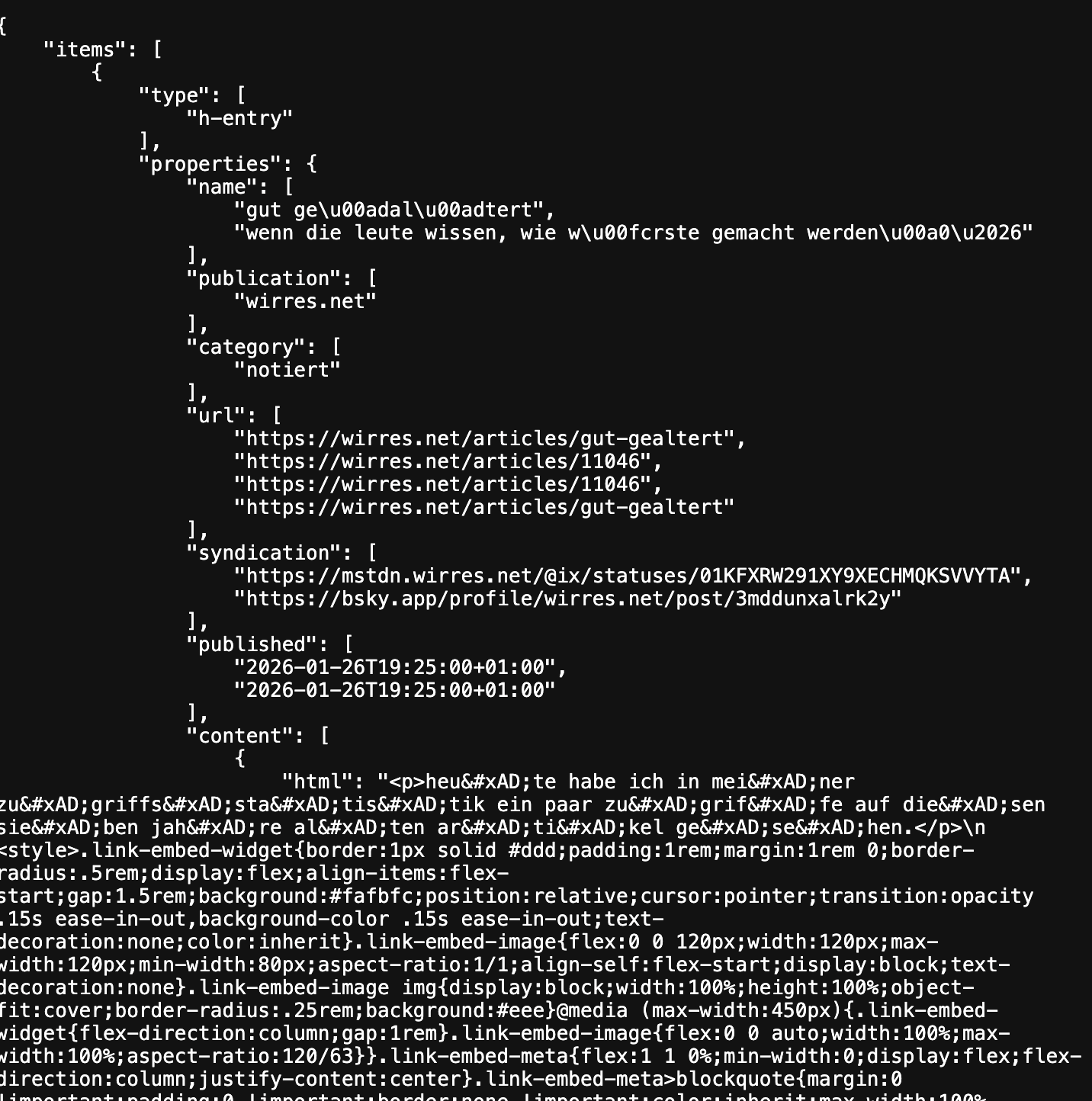
weil ich selbst gerne und viele webseiten per RSS lese, prüfe ich auch regelmässig wie meine seite in RSS aussieht — und wenn mir was auffällt oder mich stört, optimiere ich es weg. neben diversen RSS-feeds, biete ich diese webseite auch sozusagen als html-feed an. das geht, weil ich das HTML mit microformaten (mf2) auszeichne. damit lässt sich diese seite als json parsen (beispiel) und sogar als html-feed abonnieren (vorschau)
mf2 feed preview von wirres.net
geparstes mf2 von wirres.net
ansichten dieser seite als html-feed und geparste microformate
all diese ansichten, in lynx, ohne css, als geparste oder gerenderte mf2-microformate oder als RSS-feed, sind ansichten dieser website, wie sie auch maschinen sehen, suchmaschinen- oder KI-crawler, der rivva-bot oder andere aggregatoren. auch screenreader sehen die website eher in diesen minimalversionen, weshalb ich auch ein interesse daran habe, dass wirres.net in diesen ansichten ganz okay aussieht, bzw. mir gefällt.
das schöne an den eingebauten mf2-microformaten ist auch, dass man mit geeigneten readern auch meinen favoriten- oder bookmarks-strom abonnieren könnte, obwohl ich dafür noch kein RSS gebaut habe.
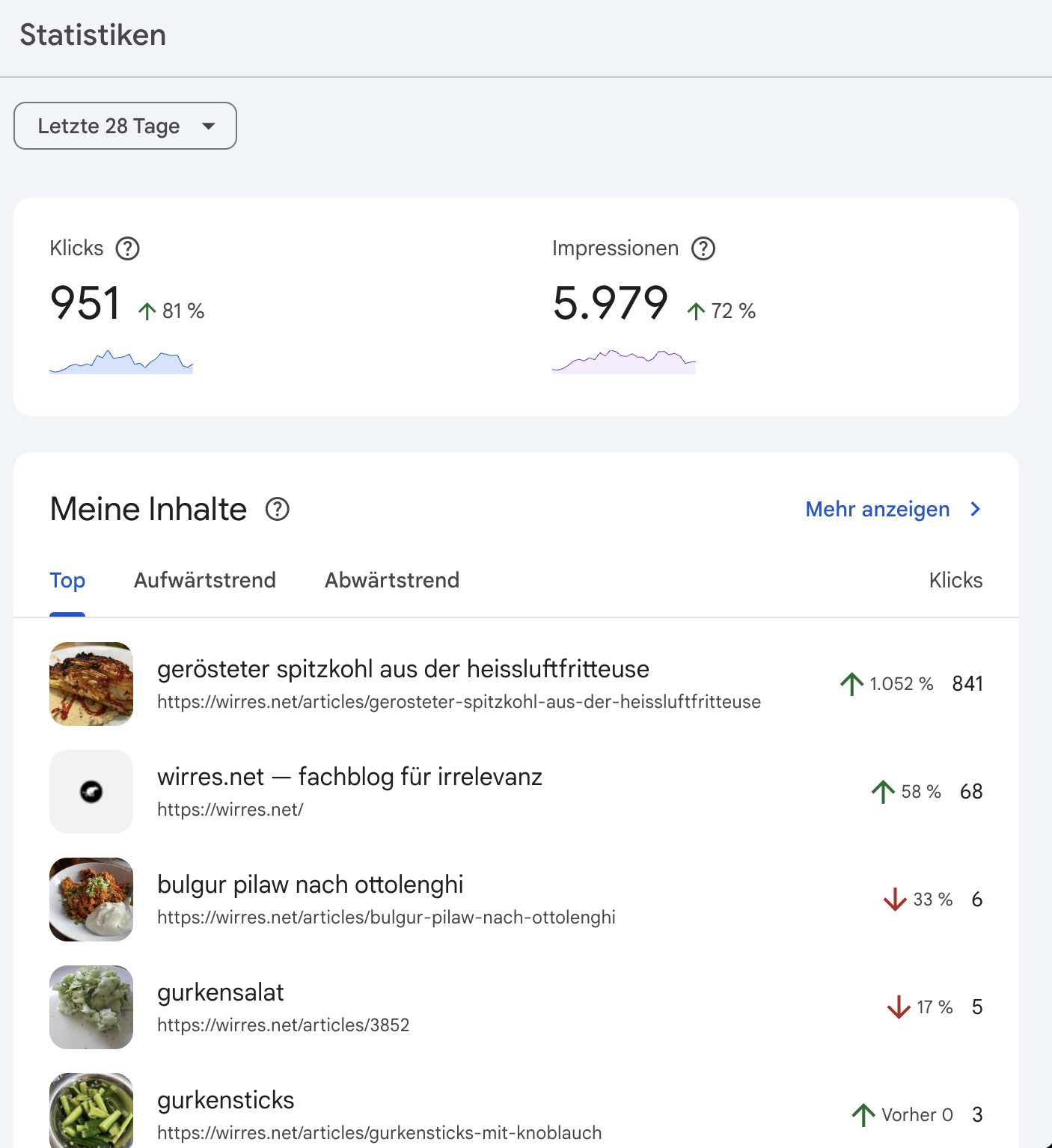
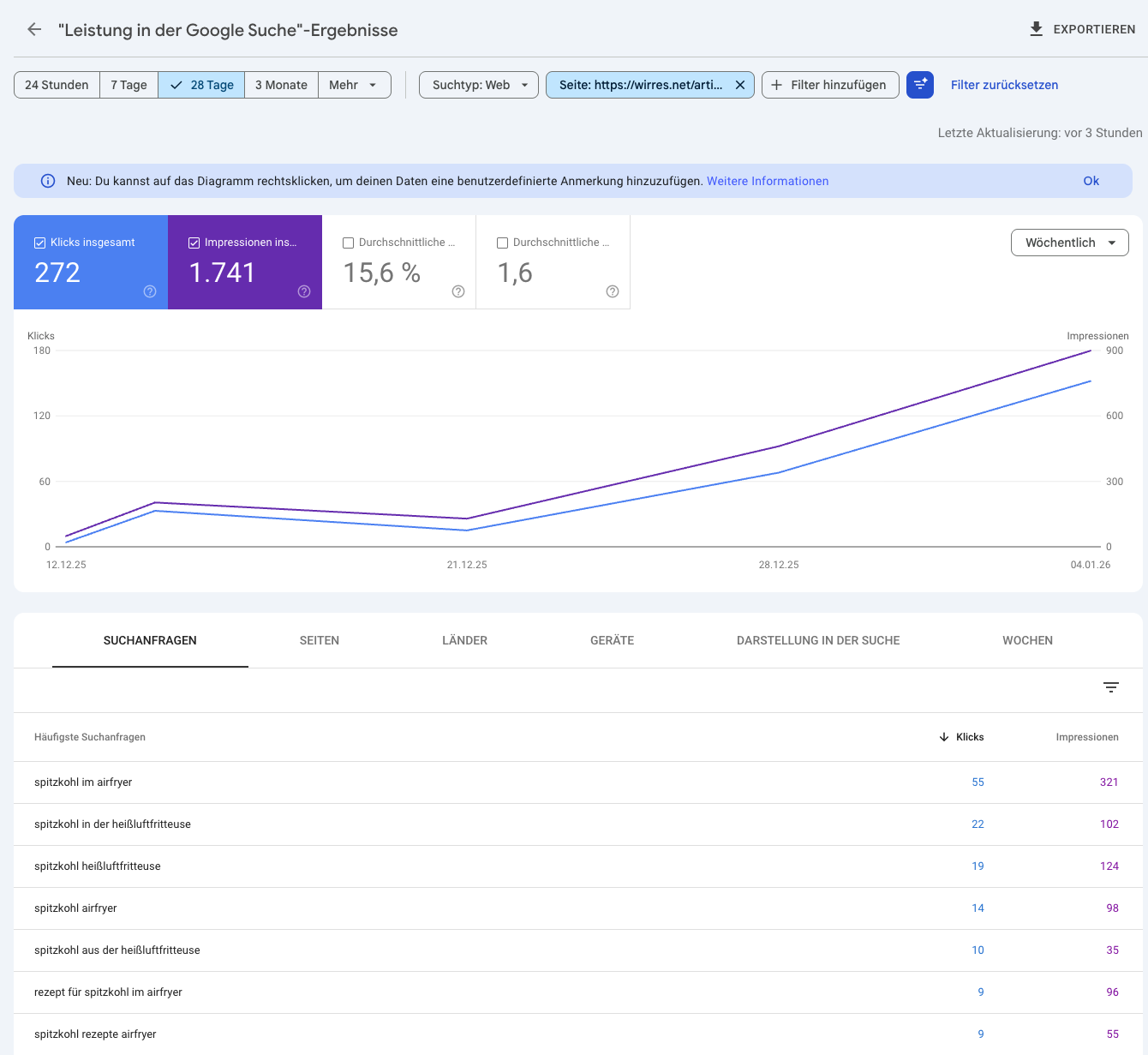
ich bemühe mich natürlich auch um gute maschinenlesbarkeit damit sich meine webseite gut mit google versteht. nach meiner blogpause und ein paar monaten offline-zeit wegen technischer probleme, verlor ich alle sympathien die mir google vormals gewährt hatte. noch nicht mal eine suche nach meinem namen zeigte meine heimstätte im netz (wirres.net) mehr auf den ersten 10 suchergebnisseiten an. nachdem ich es hier wieder schön für google und andere maschinen gemacht habe, schickt mir google auch gelegentlich wieder besucher vorbei. derzeit zwar nur für eine seite (erfreulich und erschütternd), aber dafür im januar so um die 1000.
google search konsole „statistik“
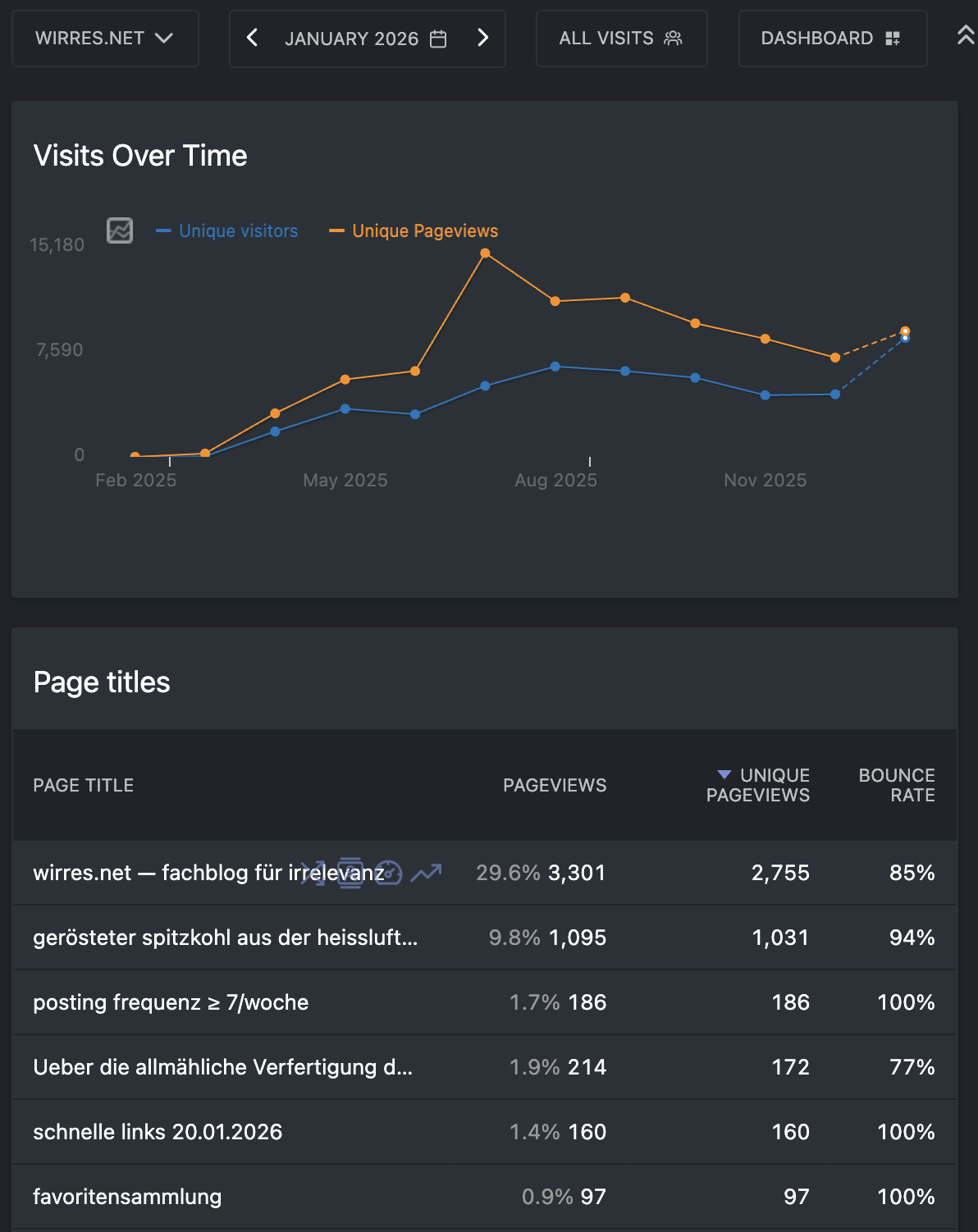
matomo statistik der letzten 12 monate (pageviews und visitors)
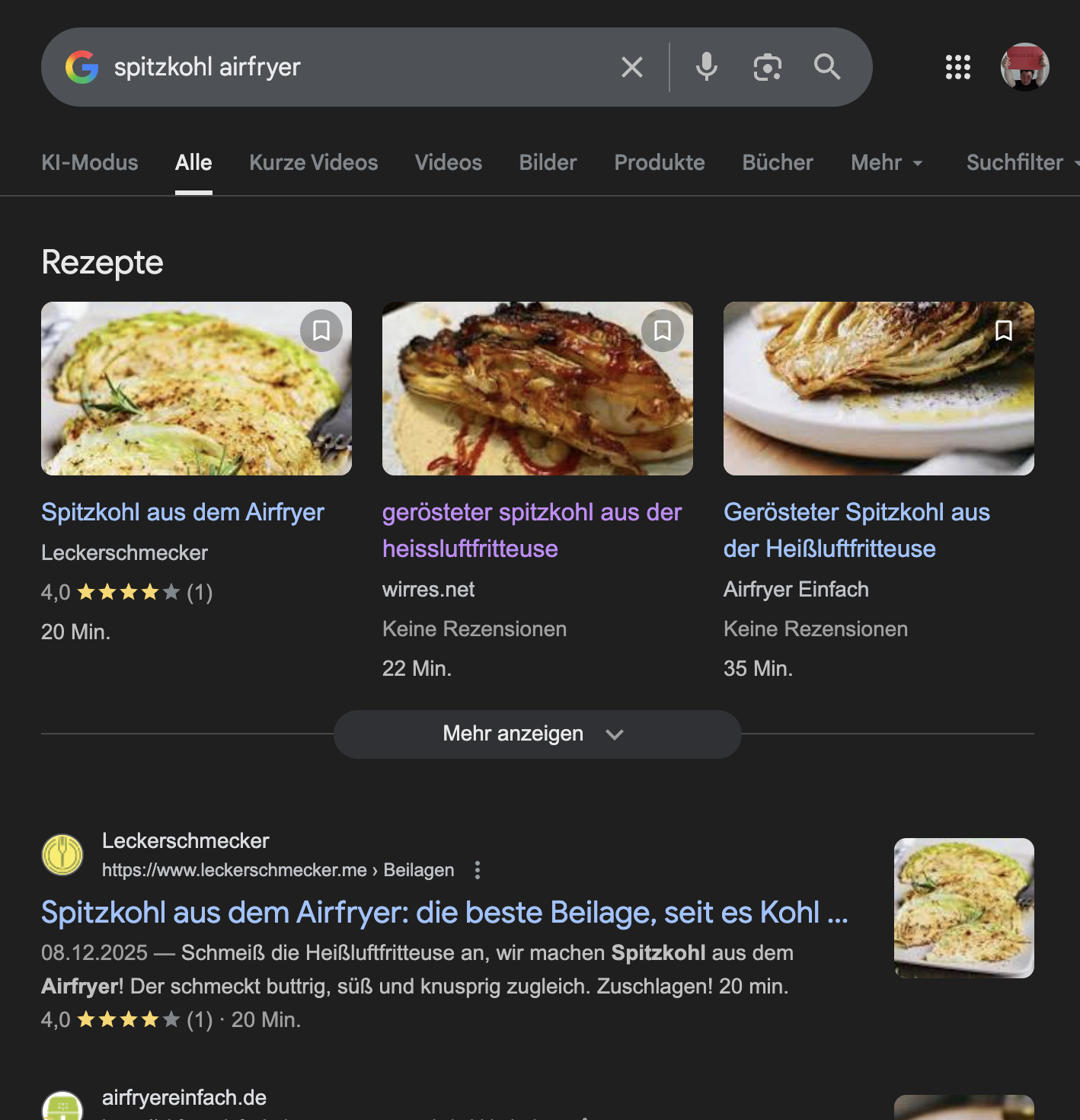
google glaubt diese website hat ein gutes spitzkohl-rezept
irgendwann vor ein paar monaten gefiel mir die idee, dass ich bilder hier so unter einer cc lizenz veröffentlichen könnte, so dass suchmaschinen sie auch mit dieser lizenz erkennen. bei flickr klappt das super, wenn man dort für seine fotos eine cc-lizenz gewählt hat. weil ich das auch wollte, aber natürlich auch weil ich die idee der reibungslosen maschinenlesbarkeit gut finde, habe ich angefangen für alle artikel json-ld mit auszuliefern. damit liefere ich zwar auch nicht viel mehr metadaten als mit den microformaten aus, aber unter anderem kann man eben auch bilder explizit mit lizenzen versehen.
das klappt einerseit auch ganz gut, andererseits vergisst google einmal indexierten und erkannten lizenzen aber auch immer wieder. irgendwie schaffe ich es nicht, mit mehr als 50 bilder von dieser website mit cc lizenz in den suchergebnisseiten unterzubringen.
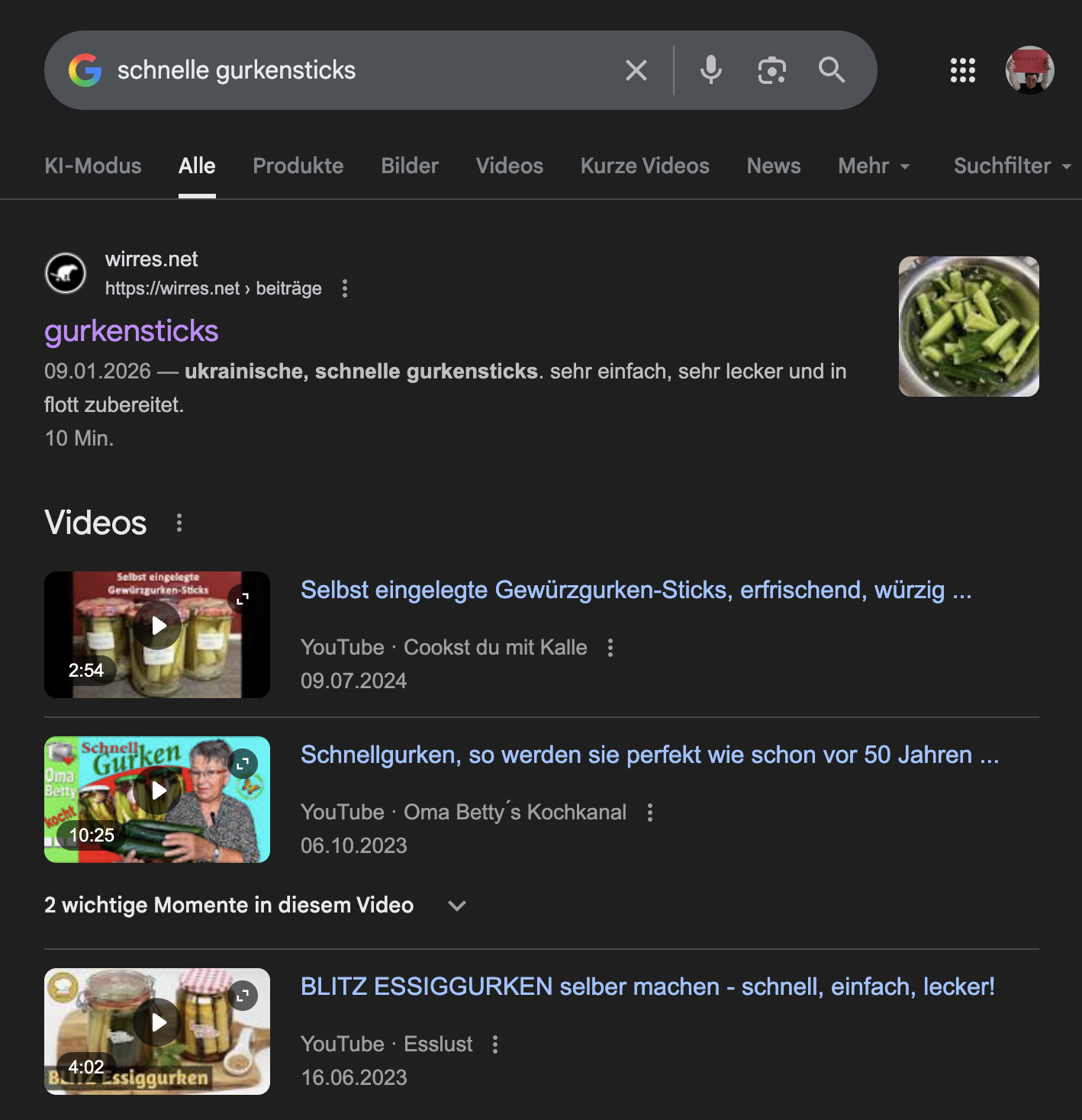
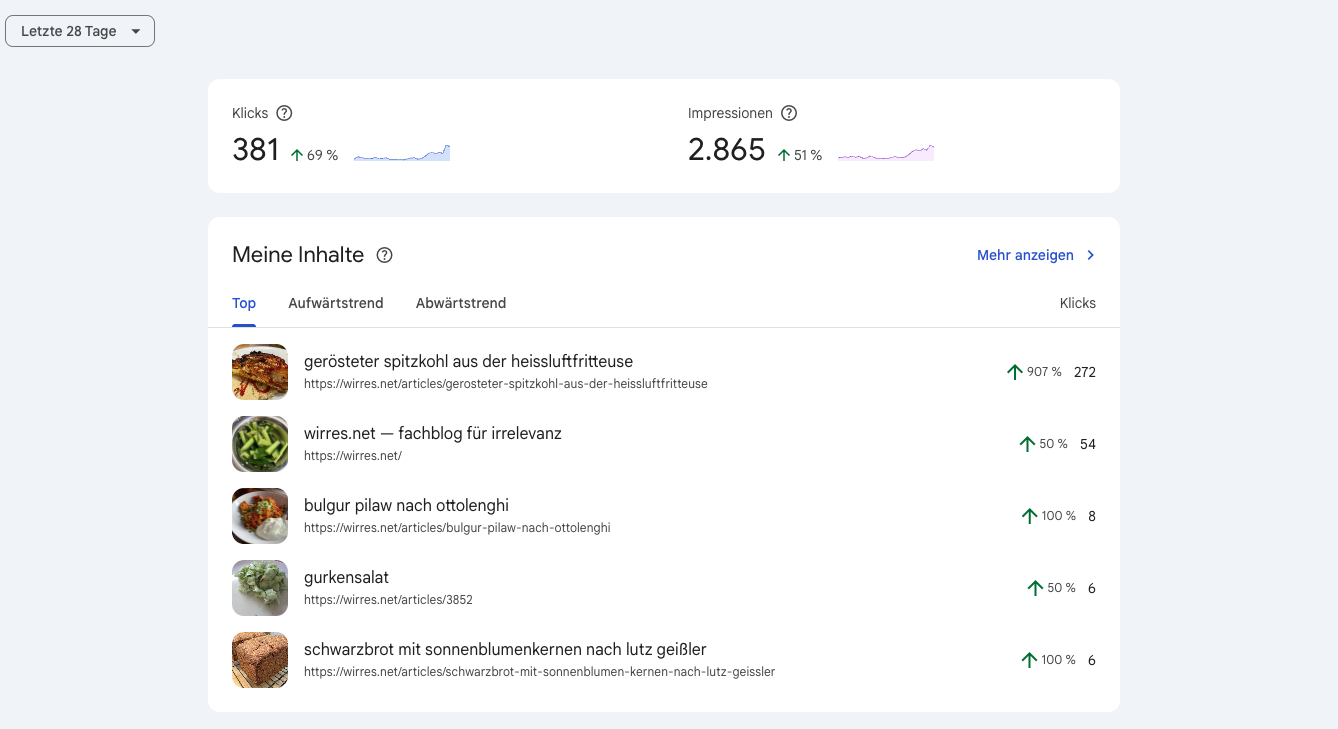
was mit json-ld allerdings super klappt ist die maschinenlesbatre auszeichnung von rezepten. so ausgezeichnete rezepte nimmt google mit kusshand und rezepte die im karussel oben in den suchergebnissen angezeigt werden sind auch der grund, warum google mir im moment so viele besucher schickt. zum ersten mal mit maschinenlesbaren rezeptdaten experimentiert hab ich vor 14 jahren. mittlerweile klappt das wirklich gut.
„spitzkohl airfryer“ suchergebnisseite
„schnelle gurkensticks“ suchergebnisseite
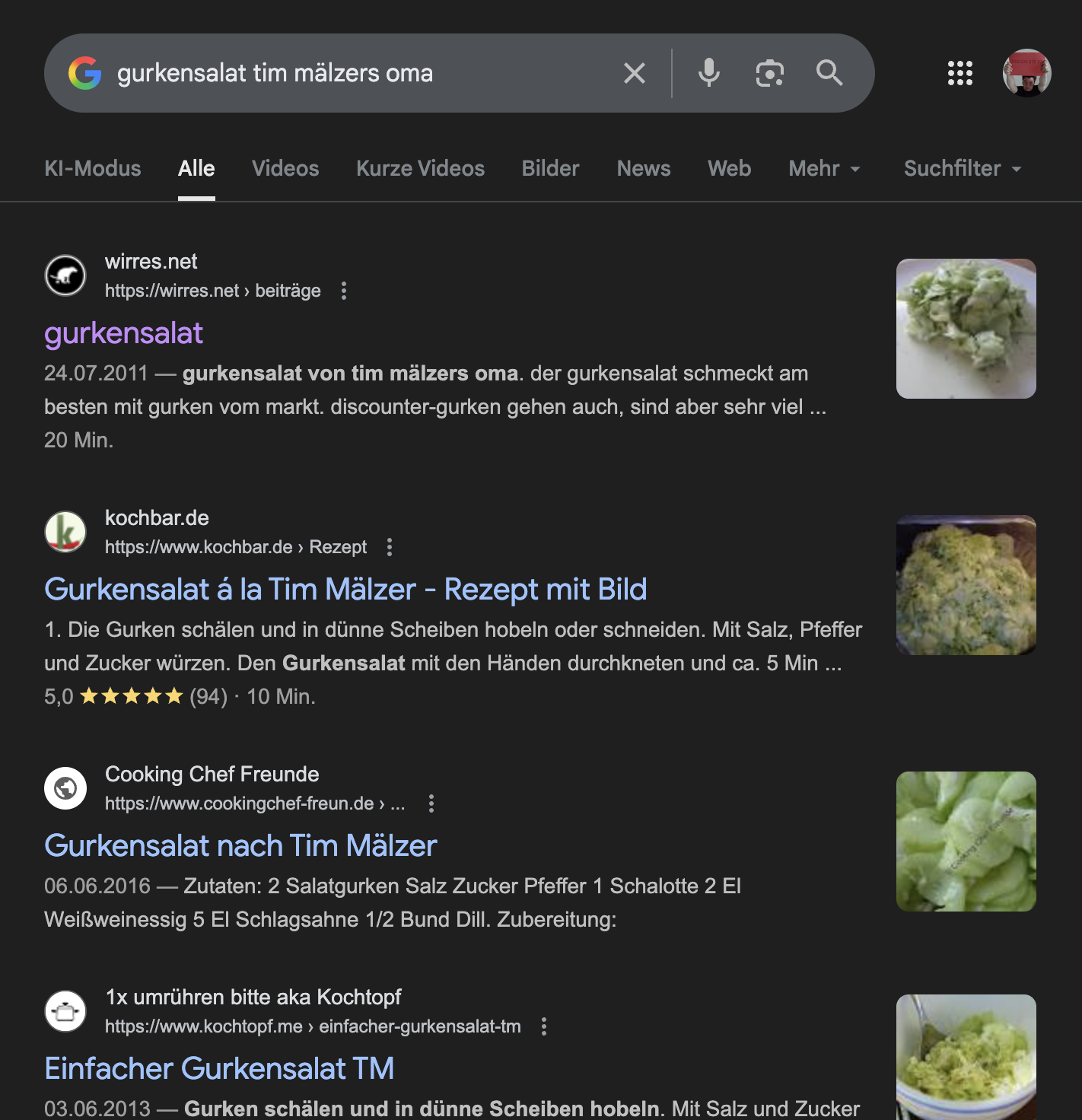
„gurkensalat tim mälzers oma“ suchergebnisseite
suchworte bei denen rezepte von dieser webseite ziemlich weit oben stehen
was ich aber eigentlich sagen will: diese ganzen optimierungen, die ich auch gerne als experimente ansehe um suchmaschinen- und technik-gedöns besser zu verstehen, haben vor allem den effekt, dass ich kleine, subtile, aber auch grobe fehler aud wirres.net finde, die ich sonst nie gefunden hätte oder die mir egal gewesen wären.
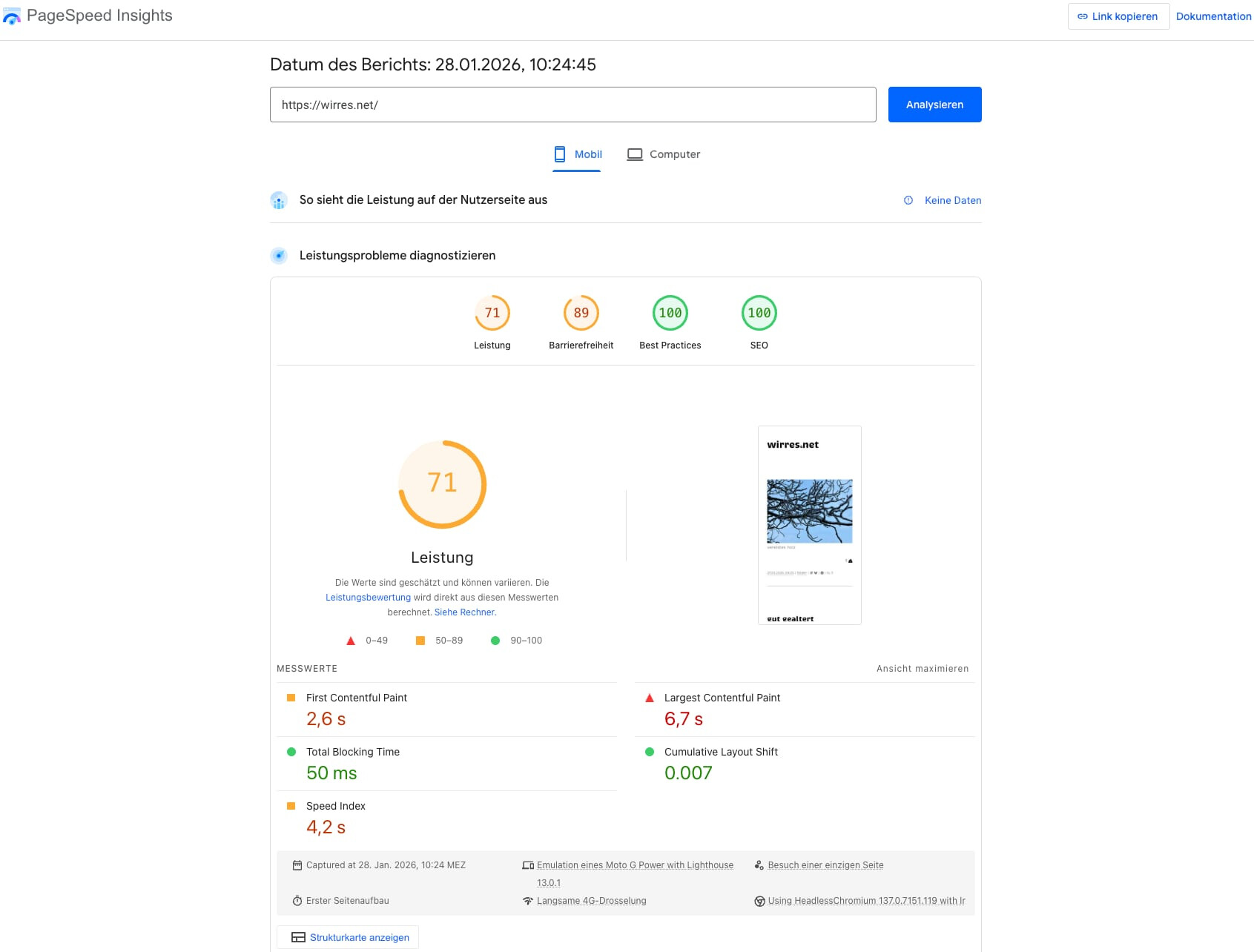
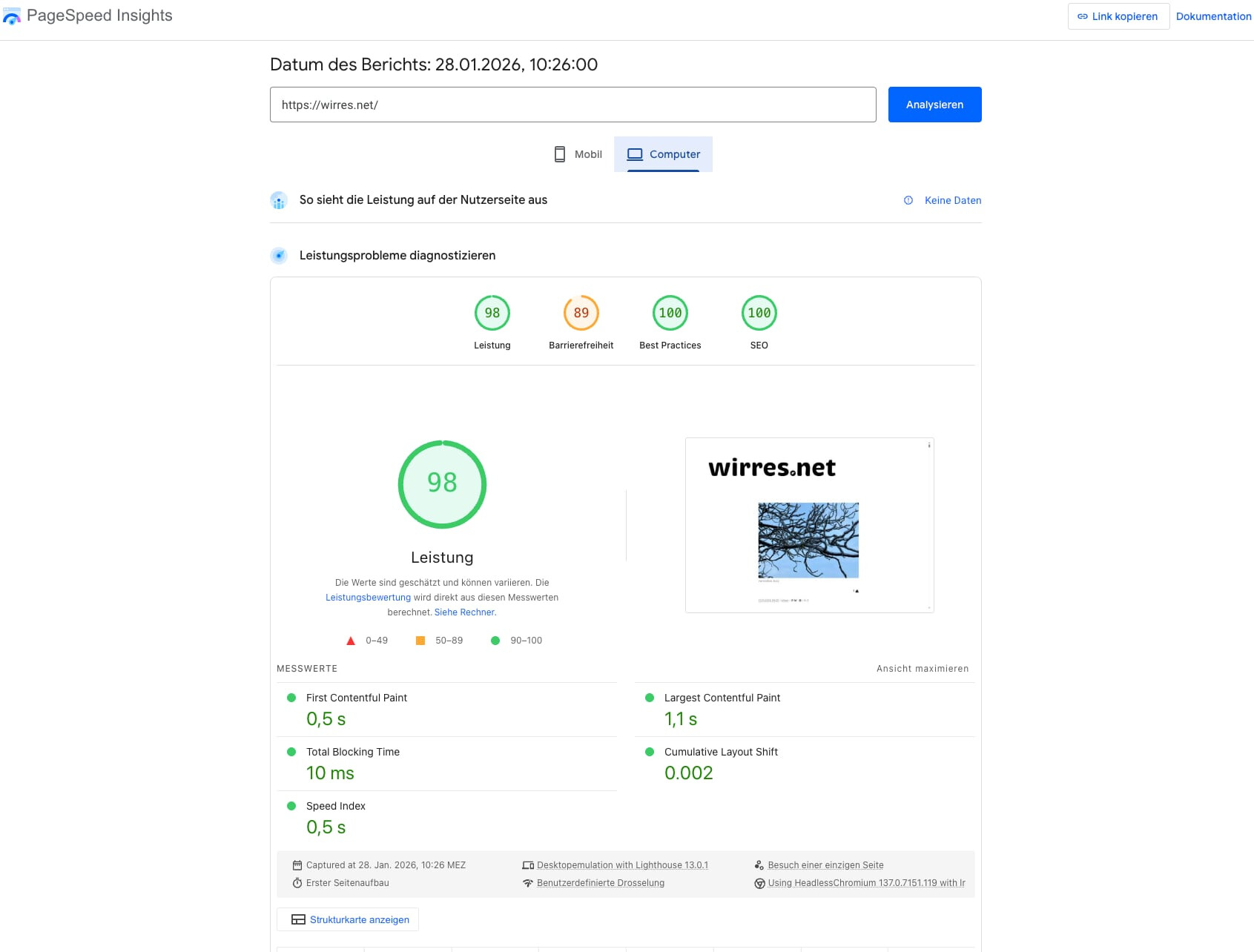
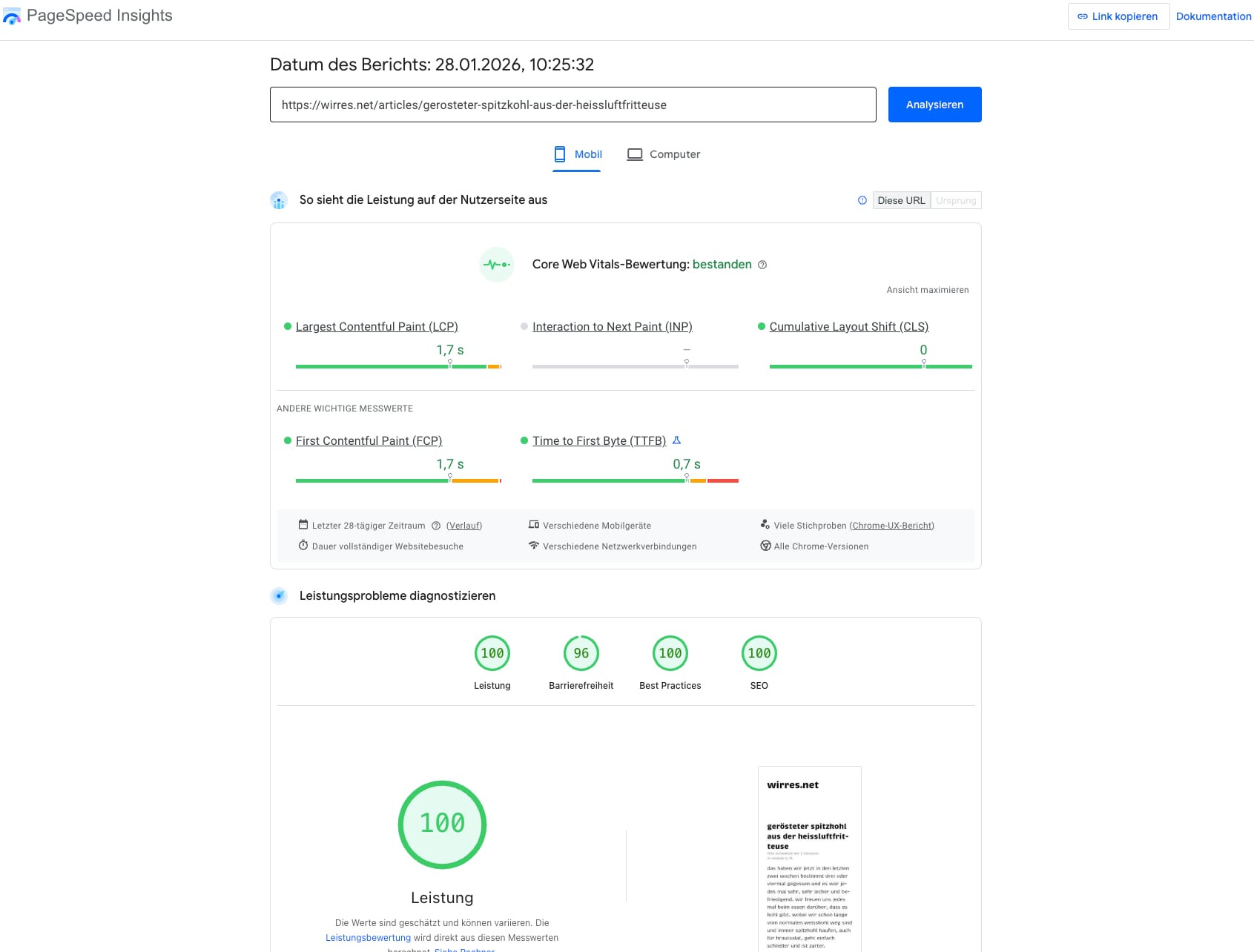
vor ein paar monaten habe ich sehr viel energie darein gesteckt in den PageSpeed Insights gute punktzahlen zu bekommen. dabei habe ich viele anpassungen am server vorgenommen, die html-struktur, lazy und eager-loading und die bildgrössen optimiert. mit der startseite ist google nicht immer 100% zufrieden, aber die einzelseiten schrammen in der regel an den 100%.
page speed test
page speed test
page speed test
gleichzeitig habe die speed-optimierungen wieder zu fehlern an anderen ecken geführt, die ich dann nach und nach wieder wegoptimiere. so ergibt sich im prinzip ein manischer kreislauf von immer neuen optimierungen. mach ich aber gerne, vor allem weil: ist ja alles meins hier.
tools die ich gerne zum rumoptimieren nutze:
ich lebe seit ewigkeiten sozusagen in meinem RSS-reader. neuigkeiten jeder art erfahre ich aus meinen > 419 abonnierten feeds. der einzige algorithmus dem ich in meinem RSS-reader begegne ist der, der nach datum sortiert.
es gibt wenige ausnahmen zu dieser regel: eine ist spiegel.de, dessen startseite ich täglich einmal aufrufe und „durcharbeite“ und eine andere ist youtube.com, dessen algorithmus mir meiner meinung nach eine gute und passende auswahl präsentiert. alle paar tage rufe ich heise.de auf. und neuerdings gehe ich ein- bis drei-täglich auf konstantins reader.konnexus.net. die feeds die dort angezeigt werden habe ich zwar auch zum grösstenteil abonniert, aber so komme ich dann bei der einen oder anderen quelle auch mal auf der webseite vorbei, statt nur die feedansicht zu sehen.
konstantins reader hilft mir auch kurzfristig eventuelle probleme mit meinem feed zu erkennen. wenn man die ganze zeit an seinem kirby rumspielt, geht ja auch mal was kaputt. natürlich habe ich meine feeds auch selbst abonniert um gegebenenfalls fehler oder probleme zu erkennen. ich hab jetzt auch mein feedly-konto reaktiviert (in der kostenlosen variante), um auch dort zu prüfen, ob alles in ordnung mit meinen feeds ist.
und da fiel mir gestern und heute leider auf, dass die neuen templates, die ich rund um mein neues favoriten und bookmark system gebaut habe, noch nicht für die RSS ausgabe optimiert waren.
kaputter youtube embed in feedly.com
eigentlich gebe ich youtube-embeds, bilder, videos, mastodon- und bluesky-embeds im RSS-feed mit vereinfachten templates aus. im screenshot sieht man, dass hier ein youtube-embed mit dem frontend-code ausgeliefert wurde. im frontend gibt’s den embed-code erst nach einem (javascript-) klick auf ein lokales vorschaubild. per RSS liefere ich den (youtube) nativen embed-code aus, weil javascript-gedöns im RSS-feed nicht zuverlässig funktioniert und von verantwortungsvollen feed-readern ausgefiltert wird.
jedenfalls sollte das jetzt wieder so funktionieren wie gedacht. die neuen templates beachten jetzt alle die vorgabe im RSS vereinfachten code auszugeben. entschuldigung für die suboptimalen RSS-lieferungen in den letzten tagen.
während ich da so bei feedly rumklickte, fiel mir auf, dass meine alte feed-adresse (wirres.net/index.xml), die weiterhin funktioniert, bzw. auf die neue feed-adresse (wirres.net/feed/) weiterleitet, laut feedly diese eigenschaften hat:
2K followers? das wollte ich einerseits nicht glauben und dachte andererseits, dass feedly dann ja wohl eine ziemlich grosse anzahl schlummernder, also ungenutzer konten haben muss. ich hatte mein feedly konto auch 3 bis 4 jahre nicht genutzt, bzw. eigentlich ohnehin nur für testzwecke angelegt. aber meine neugier war geweckt und weil gemini mir sagte, dass feedly die genaue anzahl der subscriber beim abholen des feeds nennt, aktivierte ich heute nacht meine apache access logs (die sind normalerweise deaktiviert) — und siehe da:
diese zahl widerspricht allerdings meinen eigenen messung. seit ca. 30 tagen habe ich meinen feeds einen matomo-image-tracker hinzugefügt (matomo anonymisiert die letzten zwei bytes der IP-adresse) und matomo zählt eher so um die 300 RSS-feed lesende (unique visitors pro tag).
da meine matomo-instanz (stats.wirres.net) auf einschlägigen werbeblocker-listen steht, gehe ich davon aus, dass mindestens ein drittel der aufrufe ungetrackt sind. das wären dann so um die 400 aktive rss-abos — und würde bedeuten dass feedly mindestens 2000 schlafende/ungenutzte wirres.net abos hat. (feedly reicht den image tracker durch, filtert den nicht aus.)
auffällig beim RSS-feed tracking war übrigens, dass der artikel darmspiegelung per RSS überdurchschnittlich oft gelesen wurde. oder umgekehrt dürfte das ein zeichen dafür sein, dass viele lesende die artikelvorschau meiner artikel gar nicht anklicken, ausser es interessiert sie. und darmspiegelung scheint ein guter interesse-trigger zu sein.
tl;dr: ich gebe mir mühe meine rss-feeds zu optimieren, das gelingt mir nicht immer. pro tag zähle ich derzeit laut matomo bis zu 250 einzelne besucher auf der webseite und 300-400 einzelne leser per RSS.
ich hab mich gefragt, warum soll ich die sammlungen von maston- und bluesky-beiträgen eigentlich lieblingströöts nennen? bluesky-beiträge sind ja genauso wenig trööts wie sie tweets sind. vielleicht sollte man alle kurzbeiträge im internet tweets nennen? oder bei samlungen nicht das beitragsplattform benennen, sondern die sammlung. also hab ich mir überlegt, dass ich
die favoriten jetzt etwas anders sammle, nämlich fortlaufend und hier: favoriten
die favoriten erscheinen erst auf den hauptseiten (und im RSS feed), wenn ich sie in sammlungen bündle, vorher schwimmen sie im favoritenstrom im hintergrund. genauso mache ich das jetzt auch mit bookmarks, die ich dann regelmässig zu (kommentierten) linksammlungen bündle.
bisher habe ich links oder bookmarks fast ausschliesslich auf pinboard gespeichert, entweder per bookmarklet aus dem browser oder aus meinem RSS-reader miniflux, der sie per per API dort sichert oder auf dem telefon mit einer sharing-extension. das mach ich gegebenenfalls auch weiter so, aber hauptsächlich sammle ich favoriten und bookmarks ab jetzt direkt auf wirres.net per bookmarklet und quill. quill rufe ich per bookmarklet auf, dann lässt quill mich bei bookmarks noch den inhalt bearbeiten und sichert den favoriten oder das bookmark dann per micropub hier auf wirres.net. für einen favoriten sieht der vorgang in etwa so aus:
mir gefällt dieser workflow. für die sammlungen verlinke ich die so gesicherten favoriten oder bookmarks und kirby bettet sie entsprechend ein. auch dieses vorgehen gefällt mir gut, weil einzelne favs und bookmarks dann quasi eine permalink url haben (per # unter dem embed verlinkt).
ich finde das konzept des im hintergrund leicht rauschenden favoriten- und bookmarkstroms sehr ansprechend. es stört niemanden, erfreut mich aber und wer das rauschen hören will, kann jederzeit auf wirres.net/favoriten oder wires.net/bookmarks gehen. noch gibt’s dazu keinen RSS feed, sobald mich auch nur eine person fragt, setz ich das aber bestimmt gleich um.
bis vor kurzem hab ich instagram vor allem deshalb benutzt, weil es so einfach damit ist fotos oder videos vom telefon ins netz zu bringen. instagram hat das posten von mediadateien von anfang an wirklich einfach gemacht. ich erinnere mich, dass früher, als das mobile netz noch sehr, sehr langsam war, bilder nicht erst mit dem veröffentlichen button hochgeladen wurden, sondern schon vorher, im hintergrund hochgeladen wurden. das fühlte sich damals wie zauberei an.
mittlerweile hat instagram fleissig alles in seiner app verschlechtert. das geotagging ist seit dem abschied von foursquare aus der instagram-app nicht mehr wirklich gut zu gebrauchen, ich bekomme meine beiträge rnur unter grössten anstrengungen auch wieder aus instagram raus und überhaupt, wegen digitale unabhängigkeit und so, veröffentliche ich fotos und videos eigentlich fast nur noch hier auf wirres.net.
das ist zwar auch nicht ganz unkompliziert, aber dafür ganz genau so wie ich es will. der feuchte blogger traum vom „mobloggen“, also dem mobilen bloggen, ist mit kirby zwar grundsätzlich möglich, erfordert aber ziemlich spitze finger und viel geduld. genau das was ich unterwegs nicht habe, weshalb ich meine morgenspaziergangs-fotos meist erst ein paar stunden später veröffentliche, am desktop.
vor ein paar monaten habe ich ownyourswarm reaktiviert, mit dem ich meine swarm checkins ins blog hieven kann (wirres.net/checkins). damit hatte ich eine sehr einfache möglichkeit, bilder (inklusive geodaten) mit kirby auf wirres.net zu veröffentlichen. den micropub-endpunkt, der dafür nötig ist, hatte ich mir damals mit chatGTP zurechtgehämmert. so richtig gut war die implementierung des micropub-endpunkts allerdinsg nicht. deshalb hab ich das jetzt nochmal mit cursor überarbeitet und generischer nutzbar gemacht. so kann ich jetzt auch mit quill kurze beiträge — und vor allem fotos — auf wirres.net veröffentlichen. für quill müssen die finger nicht so spitz sein wie im mobilen kirby frontend und die anzahl der optionen ist radikal reduziert — und trotzdem kann ich im hintergrund alles so einstellen wie ich es möchte und brauche.
quill notiz-eingabemaske
es gibt auch eine einfache möglichkeit geodaten an den beitrag zu hängen, ich kann beliebig viele fotos hochladen und optional die „syndizierung“ aktivieren, also den beitrag automatisch auf mastodon und bluesky weiterveröffentlichen (als platzhalter steht dort noch twitter, syndiziert wird aber nur zu mastodon und bluesky).
gestern früh habe ich innerhalb von 60 sekunden das hier aus dem volkspark rehberge gepostet: diesig, inklusive automatischer veröffentlichung auf mastodon und bluesky.
mich machen solche spielereien sehr glücklich, einerseits weil mich teilautomatisierungen immer glücklich machen und andererseits, weil da noch potenzial für weitere automatisierung und massschneiderung auf meine bedürfnisse schlummert.
ein weiteres experiment sind bookmarks die ich mit einem quill-bookmarklet einfach aus dem browser in wirres.net posten kann. ob und wie ich das langfristig nutze, muss ich noch rausfinden, aber theoretisch hab ich mit wirres.net/bookmarks jetzt einen ersatz für pinboard.in.
erschüternd und erfreulich zugleich, wie viel menschen nach spitzkohl zubereitungsmöglichkeiten im airfryer suchen. seit ich wieder angefangen habe zu bloggen, schickte mir google konsequent keine besucher mehr vorbei.
die lange beitragspause und kurze offline-zeit 2024/2ß25 haben meine relevanz aus google sicht auf 0 gedreht. langsam nähert sich google meiner website wieder an, google frisst mir die maschinenlesabren rezepte zuzusagen aus der hand. und positioniert mich bei bestimmten suchbegriffen aus dankbarkeit (oder opportunismus?) ganz nach oben.
was mir an den optimierungen meiner website gefällt: das sind alles technische optimierungen die potenziell allen maschinen, crawlern und menschen zugutekommen, inhaltlich optimiere ich weiterhin nichts.
oder anders gesagt: viele rezepte-veroffentlichende glauben ja offensichtlich, dass es eine effektive suchmaschinenoptierungsmassnahme sei vor einem rezept 400 absätze über die geschichte des rezeots, der zutaten und der welt zu schreiben, bevor man nach 16 kilometern endlich beim rezept anlangt. offenbar dient das auch dazu eine längere verweildauer zu erzeugen und damit „engangement“ zu simulieren.
um so erfreulicher, wenn google auch das gegenteil, ein hingerotzes rezept, mit einem extrem schlechten foto, orthgraphisch fragwürdiger und konsequenter kleinschreibung, nach oben befördert. wäre doch zu schön, wenn der google algoritmus irgendwann rezept-bloggerinnen dazu zwingen würde schnell zum punkt (rezept) zu kommen.
wurden wir dann für kurze zeit, so vor neun jahren stellte vine dann seinen dienst ein, ein paar monate nach der gründung wurde vine von twitter gekauft.
ich weiss nicht genau wieso ich gestern an vine gedacht habe, aber meine erinnerungen sind positiv. ich habe mal ein einigermassen witziges video dort gepostet und ich erinnere mich, dass die sechs sekunden beschräkung ein toller motor für kreativiät war und viele posteten damals extrem luustige sachen. ich dachte wahrscheinlich, schade dass das alles weg ist.
und dann dachte ich, mal schauen, ob vielleicht doch noch was da ist. teile von vine schienen noch zu funktionieren, aber an die video-dateien schien ich nicht dranzukommen. dann fand ich diese seite des archiveteams: wiki.archiveteam.org/index.php?title=Vine
dort stand beschrieben …
Sometime ca Jan 3 2025 the site showing the videos finally broke, though it is accessible via a DNS hack.[3]
der dns hack ist folgendes in die /etc/hosts datei einzutragen:
damit funktionieren die embeds sogar teilweise wieder. mit dem rest der anleitung konnte ich dann die metadaten und video-dateien meiner wenigen embeds „retten“ und diese beiträge auf wirres.net mit vine-embeds wieder „rekonstruieren“:
vor 11 jahren haben dasnuf und ich uns gegenseitig bei der arbeit gefilmt. damals und auch im nachhinein ist das schon ein bisschen witzig, vor allem wenn man bedenkt, dass wir immer noch arbeitkolleginnen sind.
nachtrag: im wikipedia-artikel über vine steht, dass sowohl kack dorsey als auch elon musk von plänen gesprochen haben, vine wieder zu reaktivieren oder zugänglich zu machen. da bin ich mal gespannt ob und wie da was draus wird.
ich habe eine seite angelegt, auf der alle gifs aufgelistet sind, die ich hier auf wirres.net bisher benutzt habe: alle gifs auf wirres.net
eigentlich nutze ich schon lange keine gifs mehr, sondern loope kleine video-dateien (ein mp4 mit den attributen autoplay loop muted playsinline). das klappt in fast allen modernen browsern und ist effektiver als gifs, die meist ein mehrfaches an dateigrösse mitbringen. das machen die grossen plattformen auch schon seit längerer zeit (ca. 2014 fing twitter damit an).
aber ich habe jetzt wieder angefangen gifs zu benutzen als fallback für die video-dateien im RSS-feed. da die meisten anbieter von rss-readern video-attribute ausfiltern, funktionieren die videodateien im feed meistens nicht. also gebe ich per RSS gifs, statt video-loops aus — wenn ich nicht vergesse das gif-fallback zu erzeugen und hochzuladen.
ein mp4 zu einem anständigen gif umwandeln geht mit diesem script ganz einfach (wenn ffmpeg installiert ist):
das script analysiert zuerst die farben des videos und passt die (eingeschränkte) farbpalette für das gif entsprechend an.
beispiel:
mp4 (899 kb)
gif (5 mb)
das schöne an gifs ist, dass sie (weiterhin) überall funktionieren. andererseits funktionieren mp4s auch fast überall, ich kann sie bei bluesky hochladen und in den meisten mastodon cients werden sie auch bewegt angezeigt. aber trotzdem fand ich es (für mich) praktisch eine übersicht über meine verwendeten echten gifs zu haben.
und kein artikel über gifs, in dem ich nicht auf das nach wie vor grossartige, 2015 eingestellte IF WE DON'T, REMEMBER ME. (iwdrm), wo irgendwer mit viel geduld subtil bewegte einzelbilder animierte und als gifs veröffentlichte. ich bin nach wie vor ein sehr grosser fan dieser animationen.
mein workflow um „live fotos“ vom iphone hier zu posten geht übrigens so:
live foto auf dem iphone zu einer „endlosschleife“ machen
airdrop auf den laptop (kommt als mp4 an)
mp4 in pixelmator öffnen und auf ca. 1000-1500 px breite skalieren
optimiertes jpg als poster-bild speichern
mp4 in pixelmator als optimiertes mp4 speichern (oder mit ffmpeg oder mediacms fürs web optimieren)
mit kirby baue ich dann ein figcaption-video-html konstrukt das in etwa so aussieht:
in den letzten tagen habe ich oft mit gemini über maschinenlesbaren code und meine implementierung davon hier auf wirres.net geredet. die implementierung mache ich mir cursor, was wiederum im hintergrund verschiedene agenten für das coding selbst nutzt. von daher ist es wahrscheinlich nicht schlecht, die arbeit von cursor nicht nur selbst zu reviewen, sondern auch noch weitere meinungen, diagnosen und einschätzungen einzuholen.
es zeigt sich, nicht alles was validiert ist auch unbedingt richtig. ein paar sachen funktionieren bereits richtig gut und google (der suchbot, der indexer, whatever) versteht hier und da meine inhalte, oder besser, meine intention. an anderen stellen klemmt es noch. so erkennt google ein paar meiner bilder als cc lizensiert, aber nicht alle.
ich finde das alles irre spannend, weil ich google bei der arbeit zugucken kann, erkenne wo noch verständnisprobleme stecken und was gegebenenfalls optimiert oder angepasst werden muss.
eben habe ich gemini gefragt, wie es die relevanz von maschinenlesbarer auszeichnunng von webinhalten insgesamt bewertet. der grösste faktor dürfte weiterhin google sein, das mit der rich-result-anzeige eine dicke, fette karotte in der hand hält, die es vor die nasen von website-betreibenden halten kann.
aber dieses argument, dass sich gemnini ausgedacht hat finde ich faszinierend. nämlich das maschinenlesbarer code auch eine antidot gegen ironie sein kann, ein faktenbett, mit dem ironie besser kontextualisiert werden könnte.
[Maschinenlesbare Auszeichnungen sorgen dafür], dass auch die dümmste KI kapiert, dass dein Verriss eigentlich eine 5-Sterne-Empfehlung ist. JSON-LD ist der einzige Ort im Internet, wo Ironie verboten ist – und genau das brauchen Maschinen.
das ist die detailierte herleitung:
Fakten vs. Nuance: Dein Blog ist ironisch ("fachblog für irrelevanz", "werbung ohne werbung"). Ein Mensch versteht die Ironie. Eine KI könnte verwirrt sein.
Text: "Die Mühle ist hässlich, aber mahlt super."
JSON-LD: reviewRating: 5.
Das JSON liefert der KI die "Ground Truth" (die faktische Wahrheit). Es reduziert das Risiko, dass die KI deine Ironie missversteht und sagt: "Der Autor hasst die Mühle."
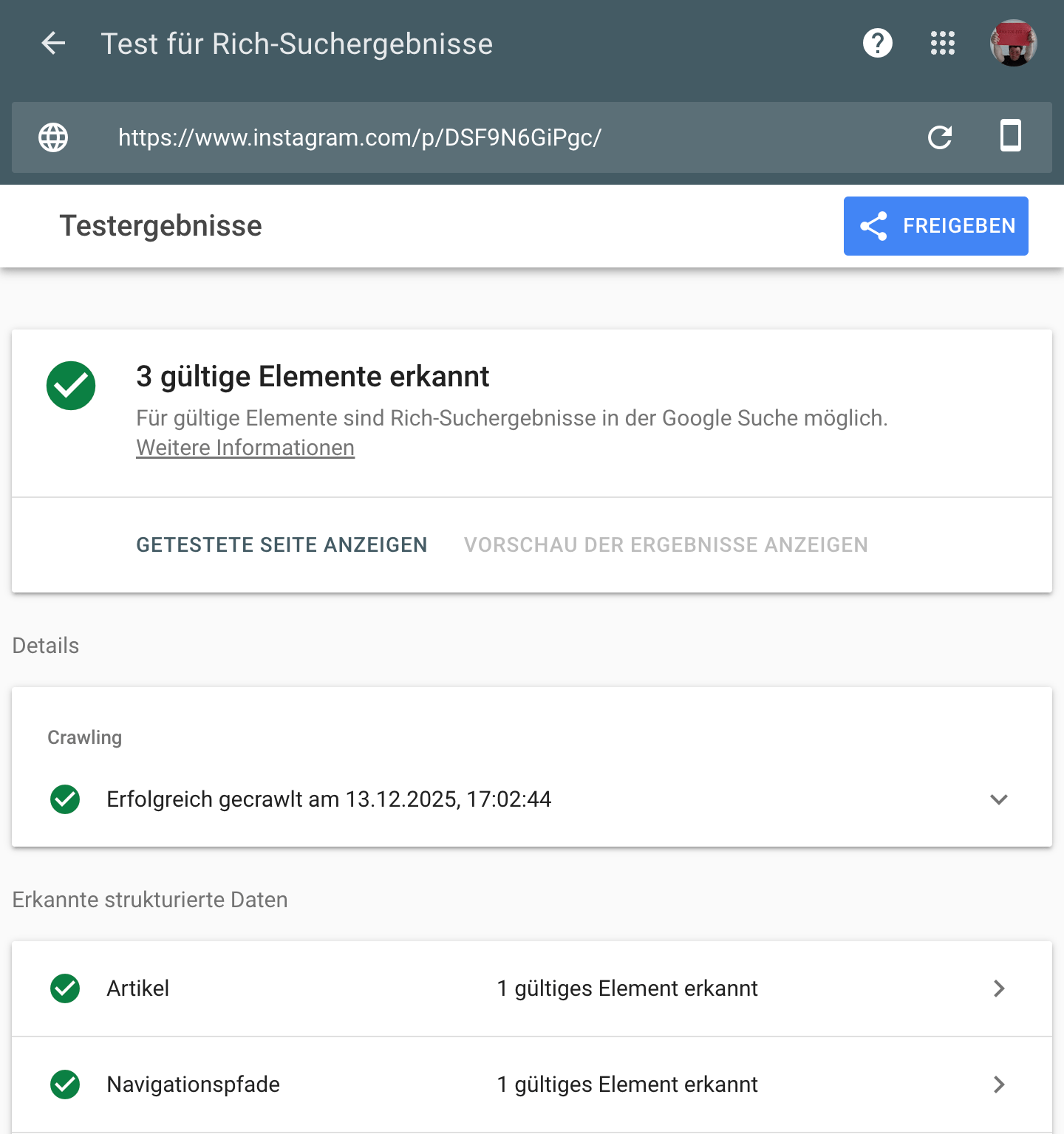
instagram nutzt wohl auch json-ld, wer hätte das gedacht? eigentlich ist instagram dafür bekannt sehr aggressiv gegen scraping vorzugehen. von der instagram-webseite kann man mit bordmitteln keine bilder sichern oder kopieren und selbst um an die eigenen inhalte zu kommen muss, man technisch sehr tief gehen und bekommt dann ständig auf die nase.
instagram nutzt json-ld, allerdings sperrt es offenbar alle user-agents ausser denen von google aus.
wenn ich diesen instagram-beitrag von mir im browser aufrufe enthält der quelltext keine json-ld (keine maschinenlesbaren infos)
bemerkenswert: die im json-ld ausgegebenen bildurls scheinen permanent zu funktionieren, ein privileg, das instagram offenbar lediglich google gönnt: testlink. bildurls die man instagram aus der entwicklerkonsole entlockt, verlieren ihre gültigkeit nach ein paar stunden (testlink) (noch halten beide links).
das ist so ähnlich wie das was der spiegel mit seinen videos veranstaltet. otto-normal-besucher bekommt die videos nur mit werbung versehen zu gesicht, google darf die werbefreie quelldatei aus den maschinenlesbaren metadaten ziehen. die karotten die google websitebetreibenden oder hier instagram und dem spiegel verspricht, verleiteten beide zur diskriminierung von menschen und maschinen, wobei instagram zusätzlich auch noch nach herkunft diskriminiert (google only).
Die Plattform erstellt(e) offensichtlich automatisch Überschriften und Beschreibungen für Nutzer-Posts, damit diese besser bei Google ranken. […] Viele Nutzer fühlen sich dadurch falsch dargestellt und haben keine Kontrolle darüber, wie ihre Inhalte im Netz präsentiert werden. Gerade bei sensiblen Themen oder kreativen Inhalten kann das schnell problematisch werden.
als ich das gelesen habe, dachte ich natürlich wie schön es wäre, wen man bilder und filme einfach bei sich auf einer eigenen webseite hosten könnte, auf einer webseite die man unter kontrolle hat und selbst bestimmen kann, was die maschinen zu sehen bekommen und was nicht.
ich poste mittlerweile nur noch sporadisch auf instagram. die insights, die instagram mittlerweile jedem zugänglich macht, zeigen auch, dass meine bilder dort ohnehin nur an wenige meiner follower ausgespielt werden. möchte ich dass mehr meiner follower die beiträge sehen, muss instagram schon sehr gut gelaunt sein oder will werbegeld von mir.
ich mag meinen workflow hier im blog mittlerweile lieber, als das mal-eben-schnell-posten auf instagram:
ich kann lizenzinfos anhängen und die lizenz und zugänglichkeit meiner bilder selbst steuern
ich kann schlagworte, links, text, video, geodaten frei schnauze benutzen
ich kann einmal für alle bilder alt-texte setzen und beiträge und bilder dann inklusive der alt-texte zu mastodon und bluesky „syndizieren“
ich kann meta-beschreibungen, titel nachträglich ändern und die präsentation, anordnung, grösse der bilder auch komplett selbst bestimmen
der preis dafür (alles selbst bestimmen zu können) ist etwas weniger reichweite und gefühlt eine etwas geringere „interaktion“.
für mich das stärkste argument bilder und filmchen selbst zu hosten, unter eigener kontrolle, ist die gestaltungsmacht über alles, zum beispiel mein archiv zu haben. die halbwertszeit eines post hier im blog dürfte sich nicht gross von der halbwertszeit eines beitrags auf instagram, mastodon oder bluesky unterscheiden. mit anderen worten: kaum jemand schaut sich beiträge an, die älter als 24 stunden oder eine woche sind. aber wenn ich will, kann ich (und jeder andere) schauen, was ich im dezember 2012 so getrieben habe. ich kann alte beiträge von mir einfach einbetten, ohne mir einen haufen tracker von einem dritten ins haus zu holen.
wo war ich? ach ja. mir fiel heute auf, deshalb die überschrift „mit einer maschine über maschinenlesbarkeit reden“, wie viel vergnügen es mir bereitet mit gemini oder cursor über solche technischen details zu plaudern. ich bilde mir ein, die maschinen haben interesse an solchen detail-diskussionen und ich muss keinen menschen mit solchen gesprächen langweilen. wobei ich mich natürlich schon frage, wer diesen text, ausser ein paar maschinen, bis hier überhaupt gelesen hat?
vor langer, langer zeit (1997) haben sich verschiedene interessenverbände aus dem bereich der fotografie und des journalismus darauf geeinigt, wie man manipulierte, gephotoshoppte oder nachträglich veränderte (manipulierte) bilder kennzeichnen wolle:
Memorandum
zur Kennzeichnungspflicht manipulierter Fotos
Jedes dokumentarisch - publizistische Foto, das nach der Belichtung verändert wird, muß mit dem Zeichen [M] kenntlich gemacht werden. Dabei spielt es keine Rolle, ob die Manipulation durch den Fotografen oder durch den Nutzer des Fotos erfolgt.
Nach Pressekampagnen haben sich bisher folgende Publikationen bereit erklärt, manipulierte Fotos zukünftig mit dem Symbol [M] zu kennzeichnen: stern · Süddeutsche Zeitung · Brigitte · Handelsblatt · Heilbronner Stimme · taz · Autoforum · Comopolitan · Das Sonntagsblatt · Amica · Fit for Fun · Max · Cinema · TV Spielfilm · Bellevue · Der Tagesspiegel. Die Initiative im Grundsatz begrüßt haben: GEO · DER SPIEGEL · DIE WOCHE · Frankfurter Rundschau · DIE ZEIT.
wer sich jetzt wundert und fragt: „[M]? nie gesehen, nie gehört“, dem kann ich sagen: das memorandum scheint ein rohrkrepierer, bzw. eher ein obliviorandum gewesen zu sein. dieser artikel von maria jansen vom april 2000 legt nahe, dass die verleger das im detail zu kompliziert fanden:
Die Verlegerverbände BDZV und VDZ konnten sich bislang nicht zur Unterstützung des Memorandums durchringen. »Wir konnten uns in der verbandsinternen Diskussion nicht auf eine verbindliche Definition einigen, wo die kennzeichnungspflichtige Manipulation anfängt«, erinnert sich VDZ-Jurist Arthur Waldenberger an Diskussionen im Verlegerkreis. Einen Leserschutz »im Sinne der Glaubwürdigkeit der Printmedien in Abgrenzung zu anderen Medien« erachte der VDZ zwar für wünschenswert. Doch eine Verbandsempfehlung habe er nicht aussprechen können. »Wir haben es den Mitgliedern jedoch freigestellt, sich dem Memorandum anzuschließen.«
Der BDZV hingegen lehnt die [M]-Kennzeichnung bislang als inakzeptabel ab. Angeblich befürchten die Zeitungsverleger, dass eine Vielzahl von Fotos unter die Kennzeichnungspflicht fallen würde, da sehr häufig Details verändert würden, was zu einer Verunsicherung der Leser führen könnte. Außerdem sähen sich die Zeitungen nicht in der Lage, ihren Lesern den Sinn der Kennzeichnung zu erklären.
und tatsächlich wird das ja wirklich ganz schnell sehr philosophisch. eigentlich müsste jedes bild aus einem modernen smartphone heutzutage mit einem [m] gekennzeichnet werden, weil die geräte nach der belichtung heftig am bild rumoptimnieren (HDR, entrauschen, tiefenunschärfe, belichtungs- und farbkorrektur, nachschärfung, siehe auch diesen artikel zu „computational photography“).
wer hätte gedacht, dass uns fotoapparate eines tages vor philosophische dilemmata stellen würden, bzw. dass wir (und die verleger) plötzlich vor ontologischen grundsatzfragen stehen: „was ist ein foto?“
zu einem pragmatischem ansatz konnte man sich bis heute offensichtlich weder in verlegerkreisen, noch in den „wichtigsten“ interessenverbände im bereich der fotografie und des journalismus durchringen. und jetzt steht das problem, wegen KI dringender denn je wieder an der tür.
als ich vor 20 jahren zum ersten mal von diesem memorandum gehört habe, entschloss ich mich manipulierte fotos konsequent in der bildunterschrift mit einem [m] zu kennzeichnen. ganz unphilosophisch, immer dann, wenn ich das bild absichtsvoll manipuliert habe. natürlich habe ich das im laufe der jahre auch wieder vergessen, aber hiermit möchte ich mich selbst daran erinnern, manipulierte bilder (einigermassen) gut sichtbar mit [m] zu kennzeichnen. mit ki bildern sollte das genausoleicht gehen: [ki]
theoretisch wäre so eine kennzeichnung auch perfekt für maschinenlesbares gedöns. json-ld kann das wohl nicht — zeigt zumidnest oberfächliche recherche. lizenzinformationen kann man mit json-ld auszeichnen, hinweise auf ki-generierte inhalte sollen wohl in den IPTC metadaten von fotos untergebracht werden. stand jetzt ist jedenfalls bei chatgpt, dass bilder die es genereriert nicht von chatgpt mit diesen metadaten versehen werden. auch hier sind diejenigen die solche bilder verwenden in der selbstverpflichtung.
nachträglich gesehen ist es auch sehr praktisch, dass ich manipulierte bilder über die jahre nicht nur in der bildunterschrift kennzeichnete, sondern meistens auch so verschlagwortete: [m]
so hab ich heute wieder einige, teils sehr kindische, mainpulationen wiedergefunden.
patriotischer joghurt [m]
für weitere kindische bildmanipulationen siehe auch:
für alle die fleisch lieben der anus mit saftigem anus beef [M]
anus|ˈānəs| noun Anatomy & Zoology the opening at the end of the alimentary canal through which solid waste matter leaves the body. ORIGIN late Middle English : from Latin, originally ‘a ring.’ (New Oxford American Dictionary)
Anus [lat.] m. Gen. - Mz.Ani After (Knaurs Rechtschreibung)
vor langer zeit, als es noch keine mobiltelefone gab, habe ich regelmässig öffentliche telefonapparate benutzt. münzfernsprecher standen überall rum, aber gerade an viel besuchten orten, zum beispiel bahnhöfen, war es manchmal gar nicht so einfach einen freien apparat zu finden. irgendwann in den neunzigern kamen dann telefonkarten auf. man kaufte sie mit guthaben und steckte sie in öffentliche kartentelefone wo dann das guthaben beim telefonieren reduziert wurde. die kartentelefone sahen etwas moderner als die münzfernsprecher aus und waren rund.
das eigentlich interessante war aber, dass in den ersten jahren sehr wenige menschen telefonkarten hatten, weshalb man an kartentelefonen meistens telefonieren konnte, auch wenn schlangen vor den münzfernsprechern standen. gelegentlich werden early adopter belohnt.
mit json ld, also bestimmte inhalte auf dieser webseite maschinenlesbar auszuspielen, bin ich zwar kein early adopter, aber offensichtlich einer der wenigen adopter.
vor ein paar tagen hab ich erklärt, warum ich die maschinenlesbarkeit meiner website für sinnvoll halte und warum ich das eigentlich nur in zweiter oder dritter linie als optimierung und in erster linie als experiment sehe: zwischenstand search engine experimentation (SEE)
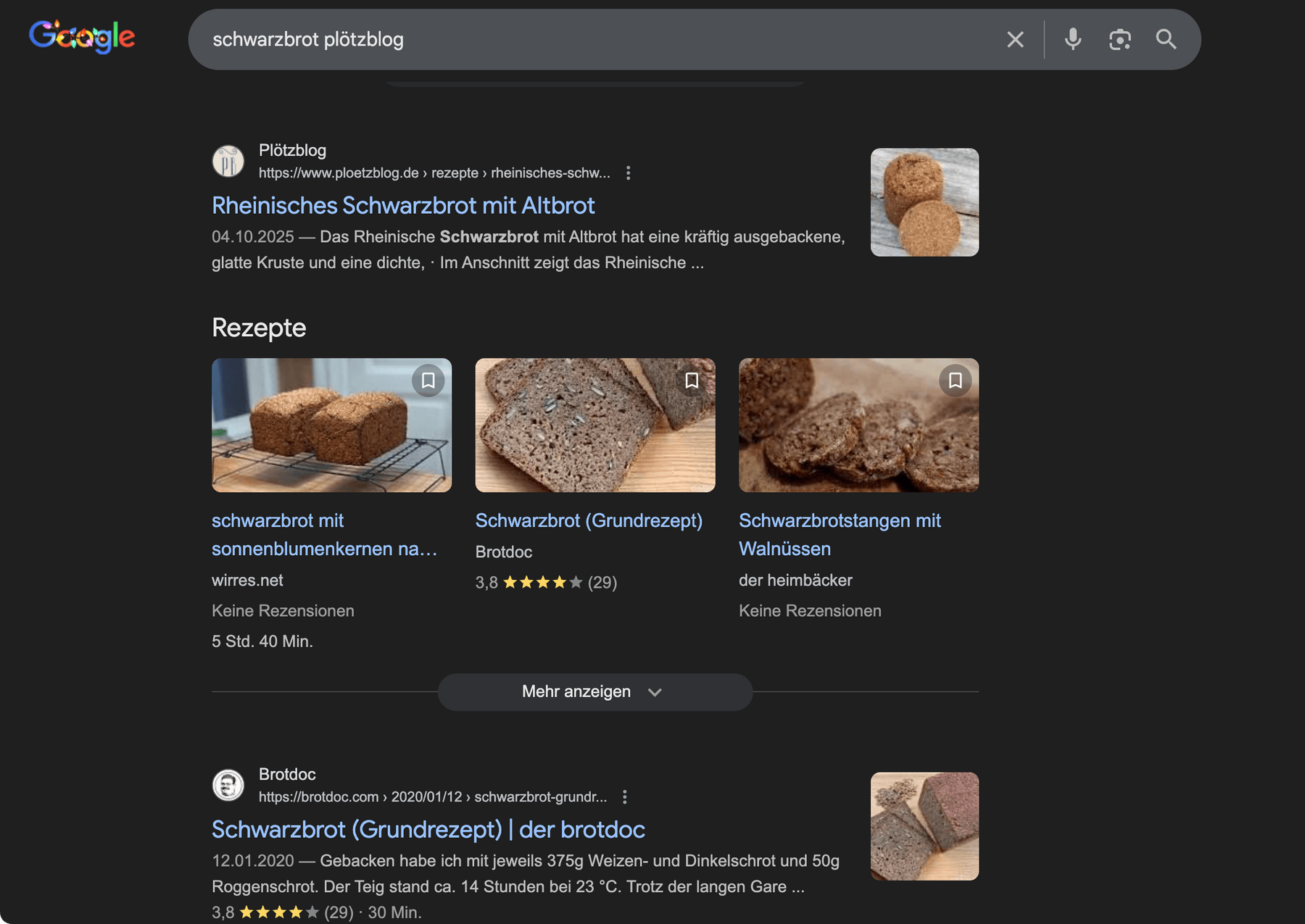
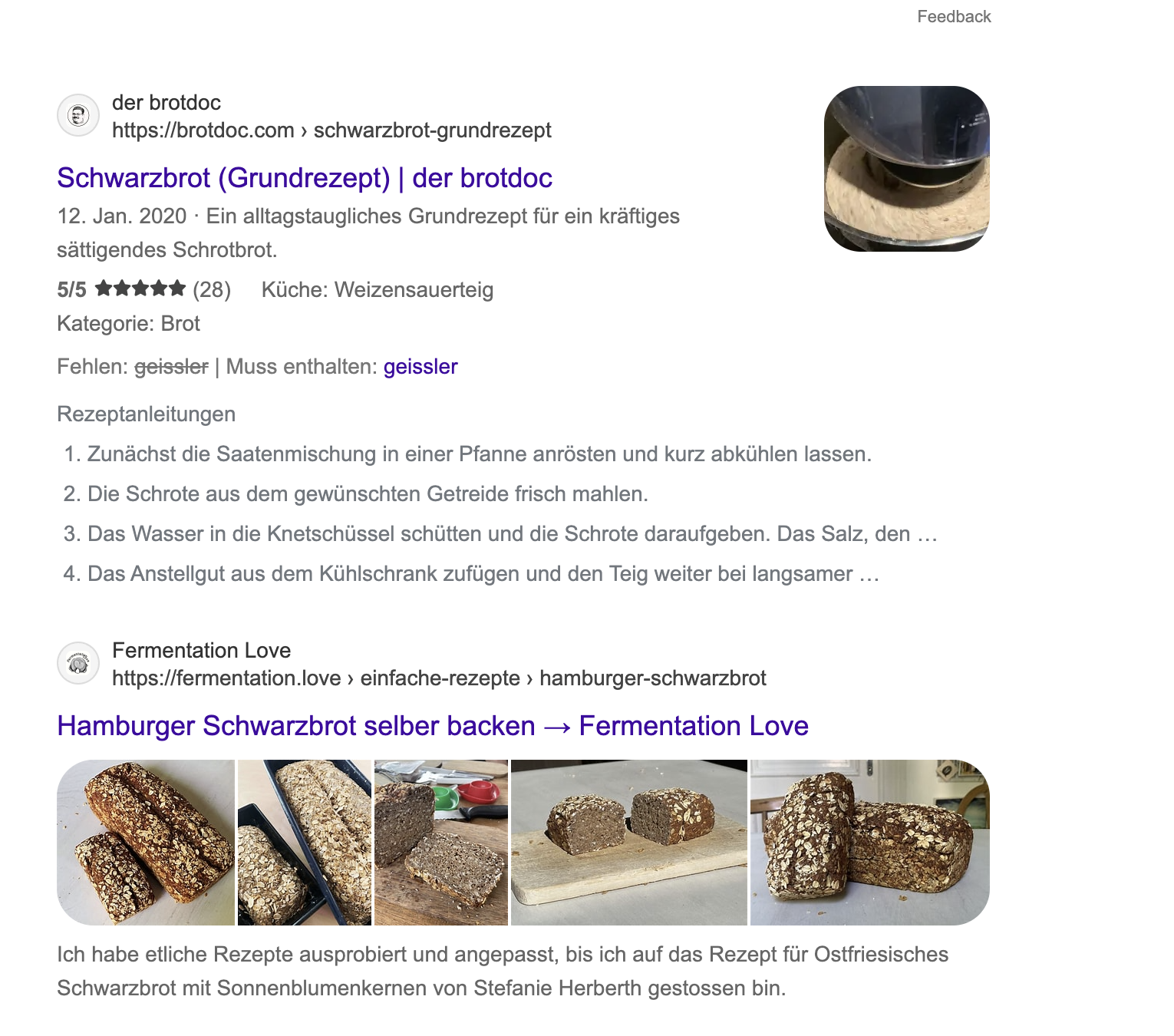
auf gewisse weise ist ein teil des experiments geglückt. dadurch dass ich rezepte auch maschinenlesbar als json-ld ausspiele, hab ich es mit meinem reproduzierten schwarzbrotrezept nach dem plötzblog auf die erste seite, in ein karussel, einer suche nach „schwarzbrot“ und „plötzblog“ geschafft. und das obwohl wirres.net google so egal ist, dass es bei einer solchen suche eigentlich noch nicht mal auf den ersten 30 seiten auftauchen würde.
suche auf google.com nach „schwarzbrot“ und „plötzlog“ mit rezept-anzeige in einem „karussel“
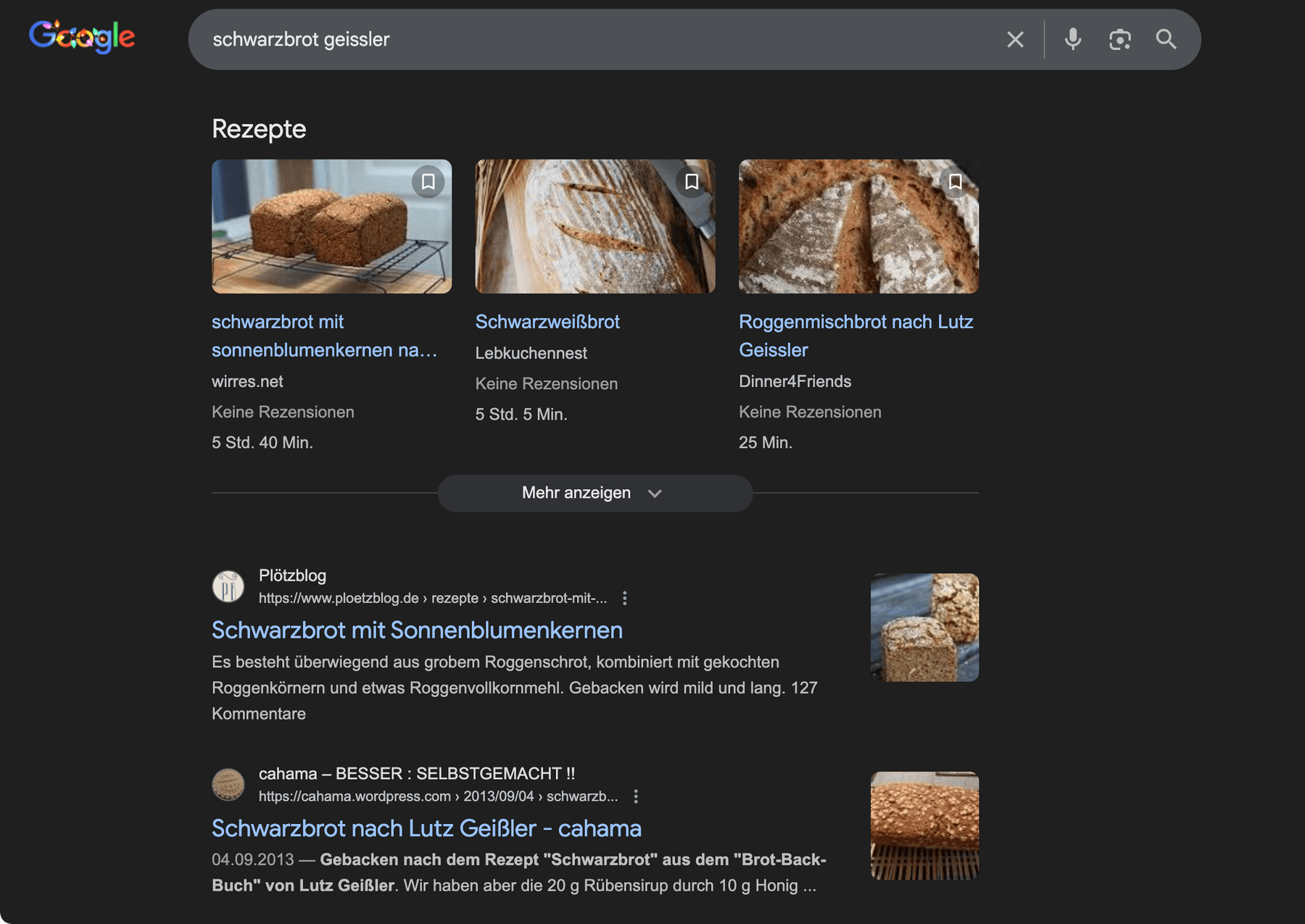
suche auf google.com nach „schwarzbrot“ und „geissler“ mit rezept-anzeige in einem „karussel“
es scheint einfach mein glück zu sein, dass sehr wenige leute ein plötzblog schwarzbrot rezept mschinenlesbar veröffentlicht haben. noch nicht mal lutz geißler selbst, der betreiber des plötzblog. ein bisschen so, wie früher mit den telefonkarten, wo ich telefonieren konnte, obwohl die telefone überlaufen waren.
ausser google scheinen sich andere suchmaschinen wenig für meine maschinenlesbare rezepte zu interessieren. bing ist zwar sehr grosszügig mit meiner platzierung direkt unter dem plötzblog auf der ersten ergebnisseite, ignoriert aber (noch?) mein json-ld. für den brotdoc, der seine rezepte auch per json-ld ausspielt, stellt es das rezept sehr explizit auf der suchergebnisseite dar.
suche auf bing nach „schwarzbrot“ und „plötzblog“
„rich-rezept“-anzeige für den „brot-doc“ auf einer bing-suchergebnisseite
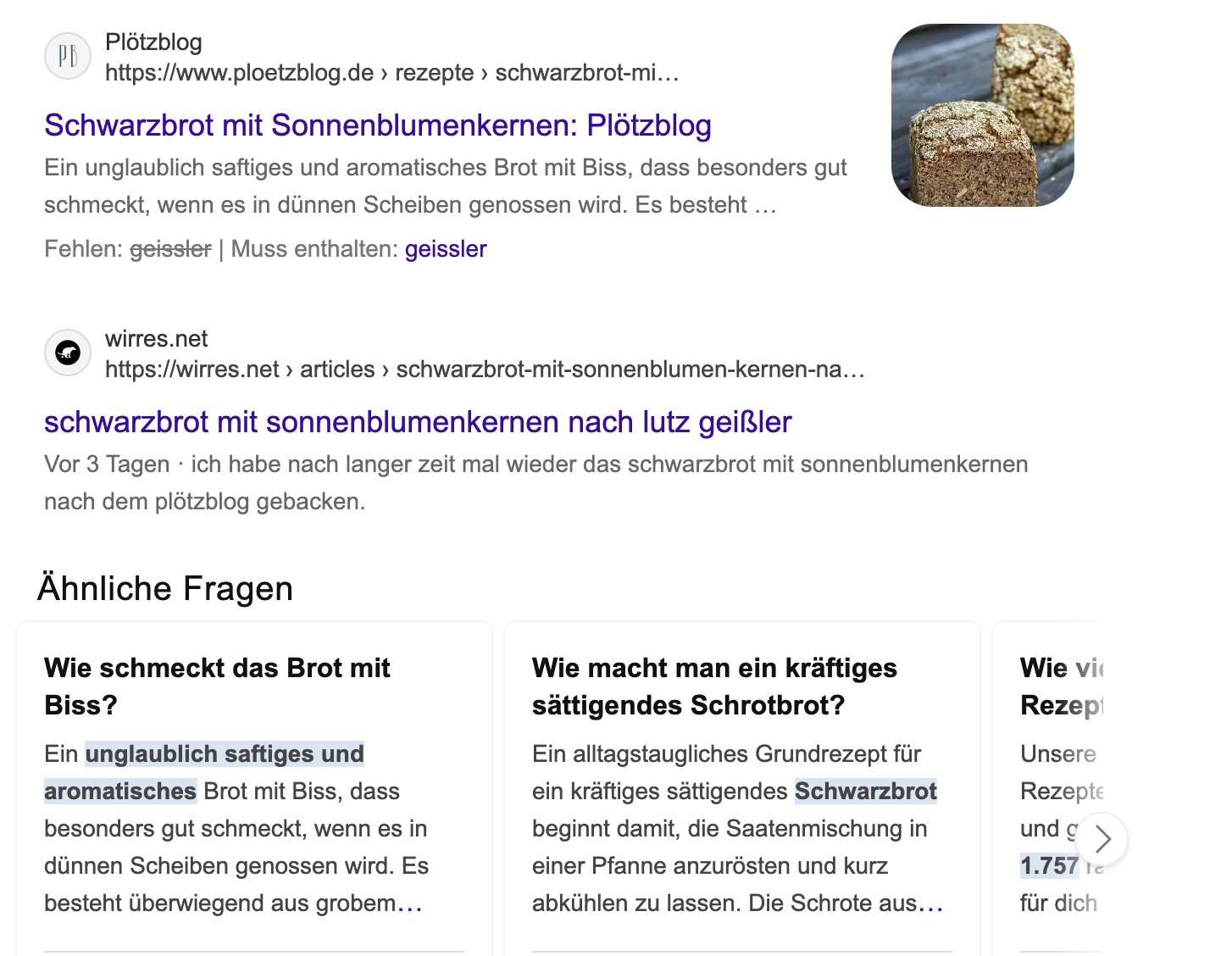
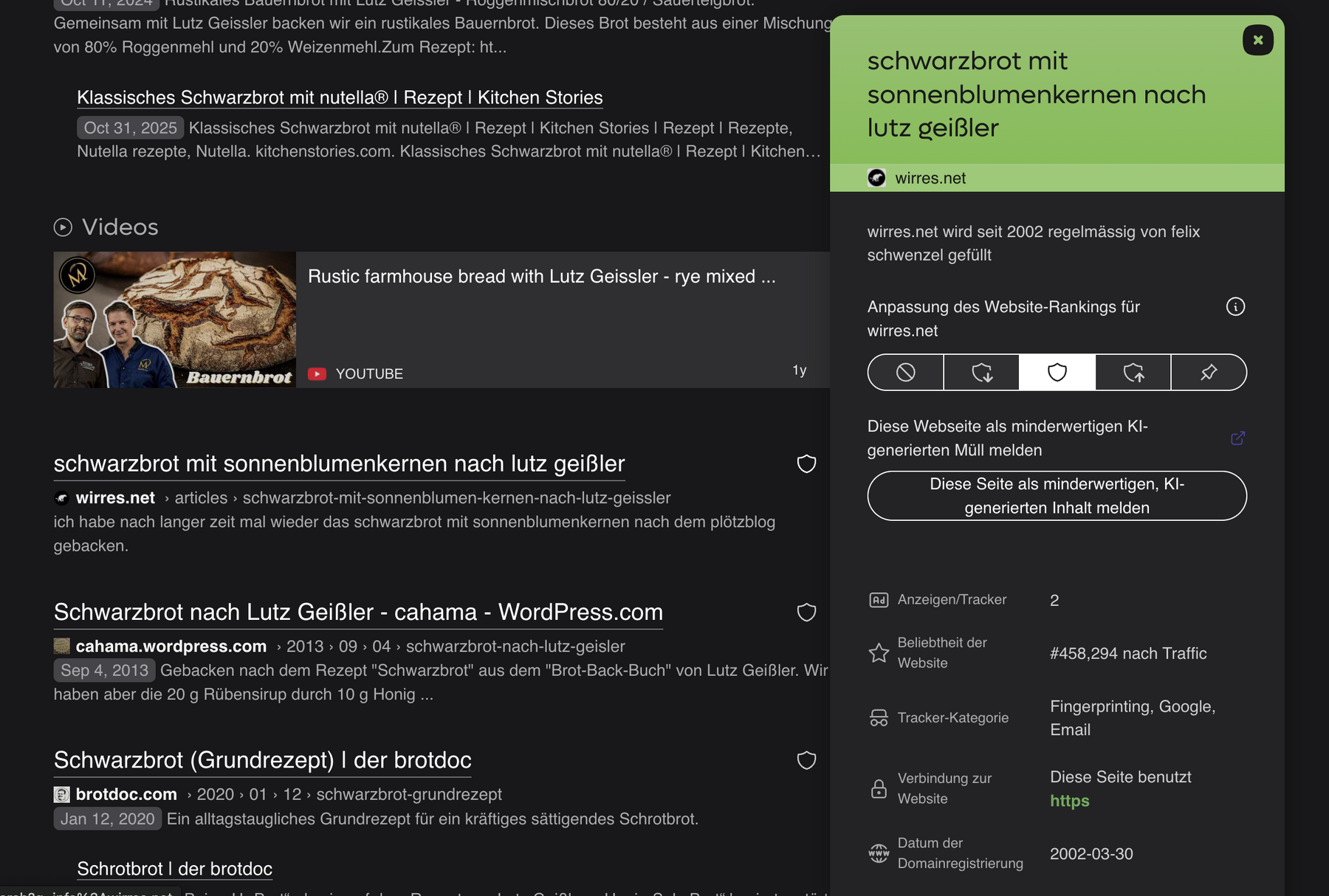
kagi.com, die kostenpflichtige suchmaschine die john gruber immer wieder empfiehlt, plaziert wirres.net auch sehr weit oben, ignoriert aber auch (noch?) die maschinenlesbare rezept-auszeichnung. dafür phantasiert es aber zwei tracker herbei („Fingerprinting, Google, Email“) die es hier eigentlich nicht gibt, ausser ich habe etwas übersehen (bin dankbar für hinweise).
kagi-suche nach „schwarzbrot“ und „geissler“, inklusive falscher warnung vo trackern auf wirres.net (den font, bzw. das abgeschnittene *geissler* „g“ auf der grünen fläsche, würde ich gerne als minderwertiges grafikdesign oder „inferior font“ melden, dafür gibt’s aber keinen button)
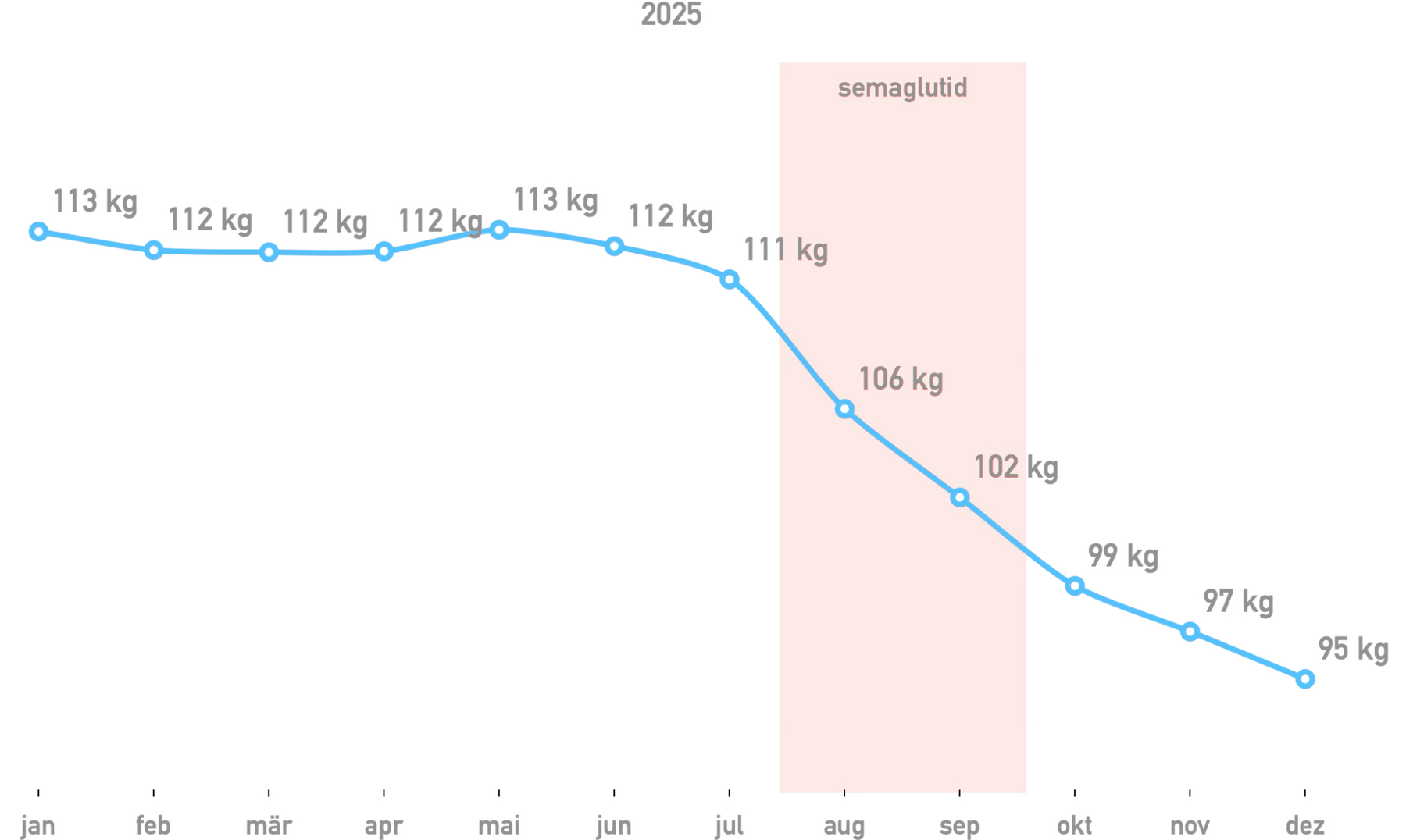
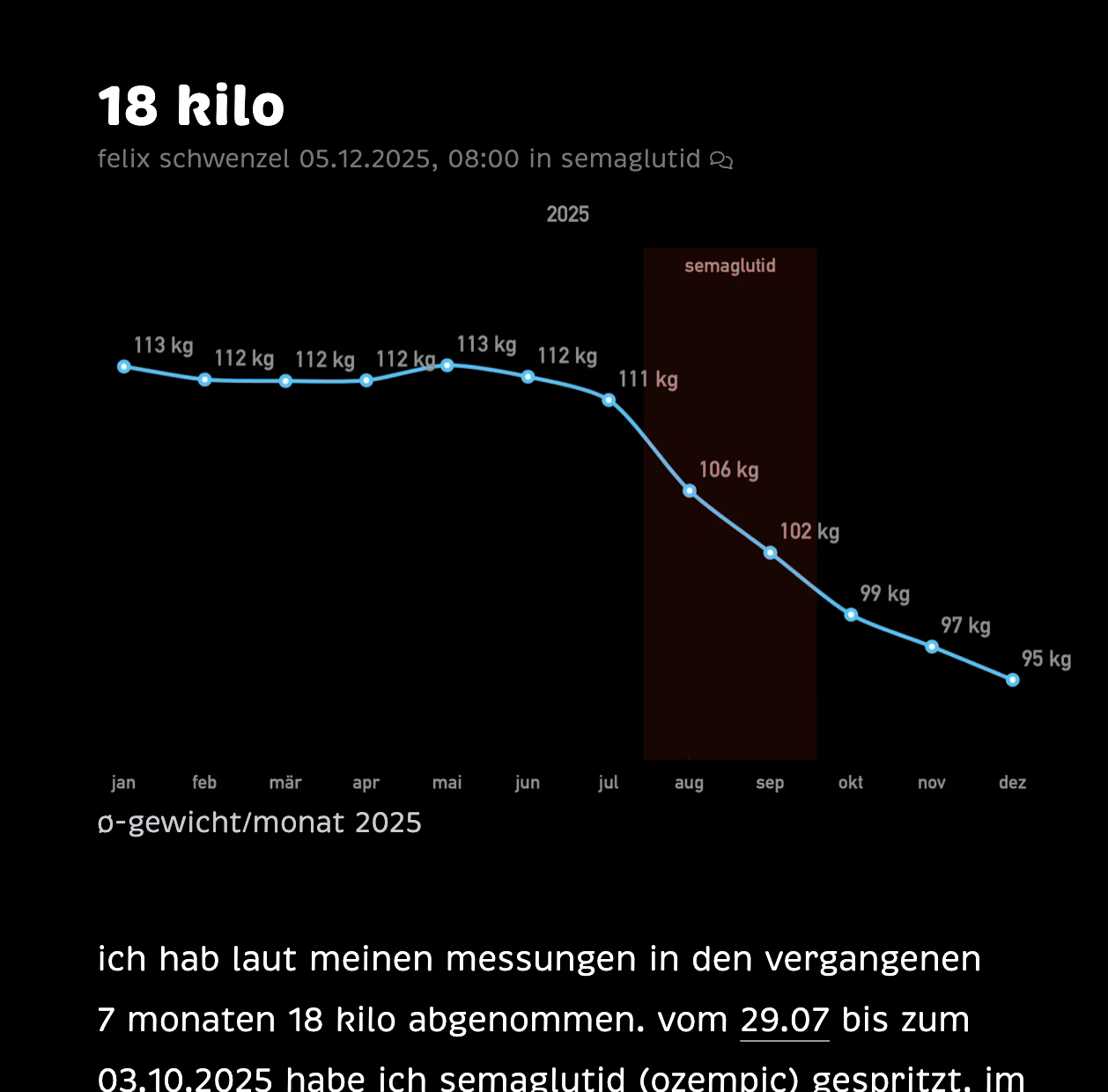
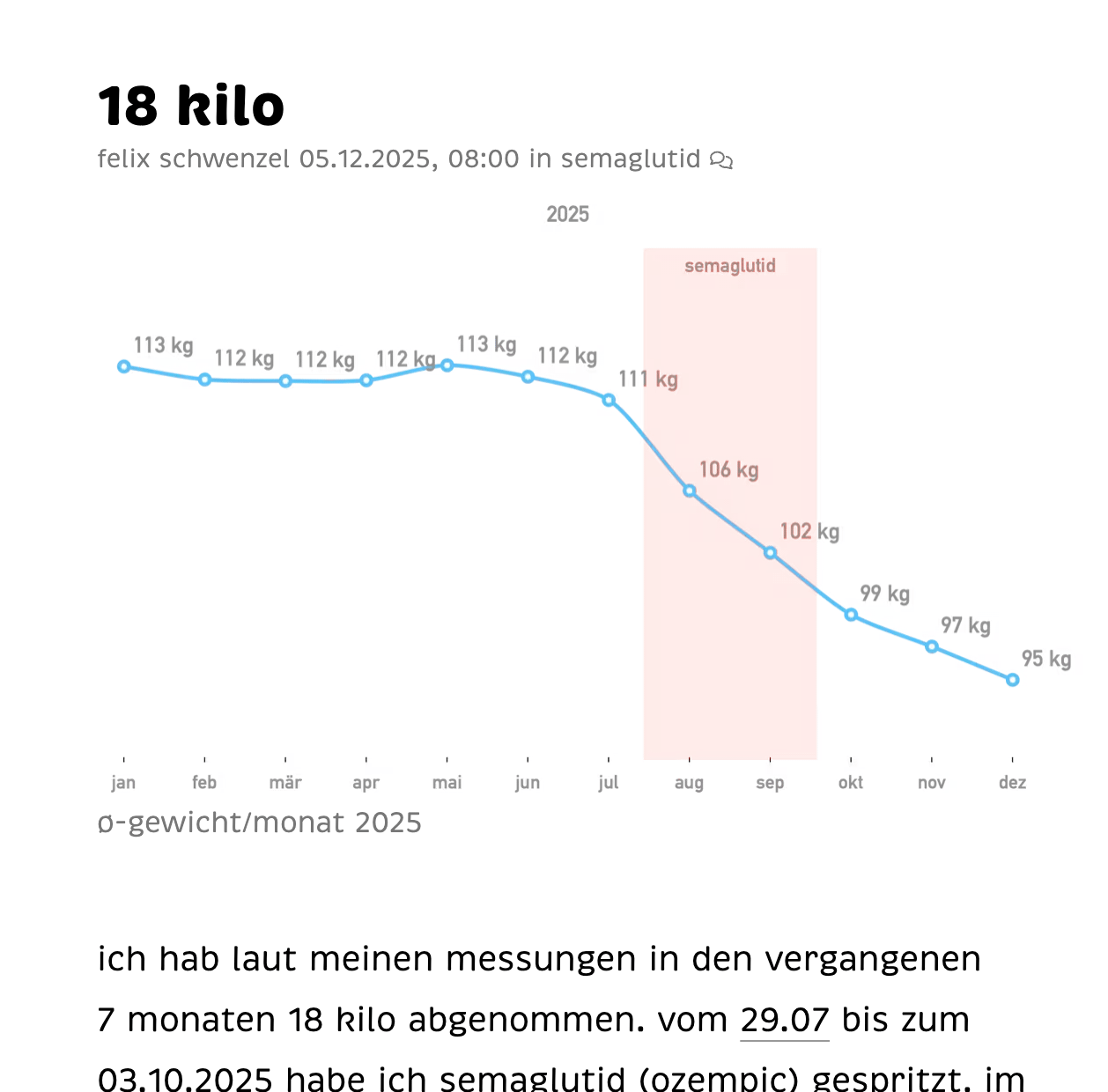
ich hab laut meinen messungen in den vergangenen 7 monaten 18 kilo abgenommen. vom 29.07 bis zum 03.10.2025 habe ich semaglutid (ozempic) gespritzt. im schnitt hab ich 2 ½ kilo pro monat abgenommen. heute hab ich zum ersten mal unter 94 kilo gewogen. aus meinem körper ragen knochen, an die ich mich gar nicht mehr erinnere.
ich nehme kaum noch zucker oder süsses zu mir, obwohl ich das nougat aus dem adventskalender, das die beifahrerin nicht mochte, gegessen habe, was mir aber nur halb so gut geschmeckt hat wie die 250 gramm quark, die ich jeden mittag mit einem haufen TK-obst (kalt passierte mango, him- oder blaubeere) mit süssstoff und etwas sahne, milch oder kokosmilch zu mir nehme. ich esse ca. 500 gramm sambal olek pro monat und verzichte eigentlich auf nichts. morgens esse ich nach einer stunde spaziergang nach wie vor deftig, entweder reste vom vorabend, käsebrot, rührei oder salziges müsli (gemüsesalat). abends viel (saisonales) gemüse, aber gerne auch überbacken mit käse, nudeln, pommes oder gerösteter spitzkohl mit humus.
ich esse allerdings mehr oder weniger nur halb so grosse portionen, bzw. eine portion statt zwei, ein käsebrot statt zwei. bier habe ich grösstenteils auf alkoholfrei umgestellt, sonst, wie mein leben lang, wasser aus der leitung und espresso mit kuhmilch, jetzt allerdings ohne zusätzlichen zucker neben dem milchzucker.
die 300,00 € die ich für eine pakung ozempic ausgegeben habe, waren eine gute investition und hätten sich allein durch den weniger gekauften käse bezahlt gemacht, wenn ich nicht so viel mehr TK-obst essen würde, was auch nicht gerade billig ist.
beide sätze sind wahr: ich verzichte auf nichts. weniger essen und den zucker weglassen fühlt sich nicht wie verzicht an.
ich sehe keinen grund warum ich das nicht die nächsten 20 oder 30 jahre so weiter machen sollte.
aus dem maschinenraum
ich habe vor sechs jahren eine unserer waagen umgebaut, damit sie wifi spricht und die wäägungen an home assistant weitergibt. um die daten an die apple health app weiter zu geben, nutze ich ifttt (home assistant triggert einen ifttt web-hook). das ist ziemlich praktisch. ich wiege mich morgens nach dem aufstehen, nach dem spaziergang und gelegentlich auch tagsüber. apple health macht einen guten job aus den werten glatte kurven zu machen und alles in durchschnittswerte zu verrechnen. aber homeassistant speichert langfriste statistiken auch bereits normalisiert und um an die monatswerte zu kommen, habe ich diese SQL-abfrage gemacht (2008 ist die metadata_id des gewichtssensors).
SELECTDATE_FORMAT(FROM_UNIXTIME(s.start_ts), '%Y-%m') AS monat,
AVG(COALESCE(s.mean, s.state)) AS durchschnitt
FROMstatistics s
WHEREs.metadata_id=2008ANDCOALESCE(s.mean, s.state) IS NOT NULLANDs.start_ts>= UNIX_TIMESTAMP('2025-01-01 00:00:00')
ANDs.start_ts< UNIX_TIMESTAMP('2026-01-01 00:00:00')
GROUP BY monat
ORDER BY monat;
das diagram hab ich dann aus den 12 werten in apple numbers gebaut. um die grafik aus numbersmit transparentem hintergrund rauszubekommen, hab ich die grafik einfach per copy 6 paste in pixelmator kopiert. man kann die numbers datei auch als pdf exportieren und mit pdf2svg (brew install pdf2svg) in ein SVG umwandeln.
svg version des gewichtsdiagrams
wichtig war mir nur, dass das diagram sowohl im dark, als auch im light mode gut aussieht. das klappt sowohl beim svg, als auch dem png. auch wenn die SVG-datei 70 kb kleiner ist, hab ich keine ahnung wie das mit der photoswipe-vergrösserung und im RSS funktioniert, weshalb ich oben das png verwende. (nachtrag: rss-reader scheinen kein problem mit der SVG-darstellung zu haben.)
diagram im dark und light mode
wenn ich nicht so bequem wäre, hätte ich schon lange eine funktion in kirby implementiert, mit der man bilder „artdirected“ ausgeben kann, je nach dark oder light mode. im prinzip geht das so:
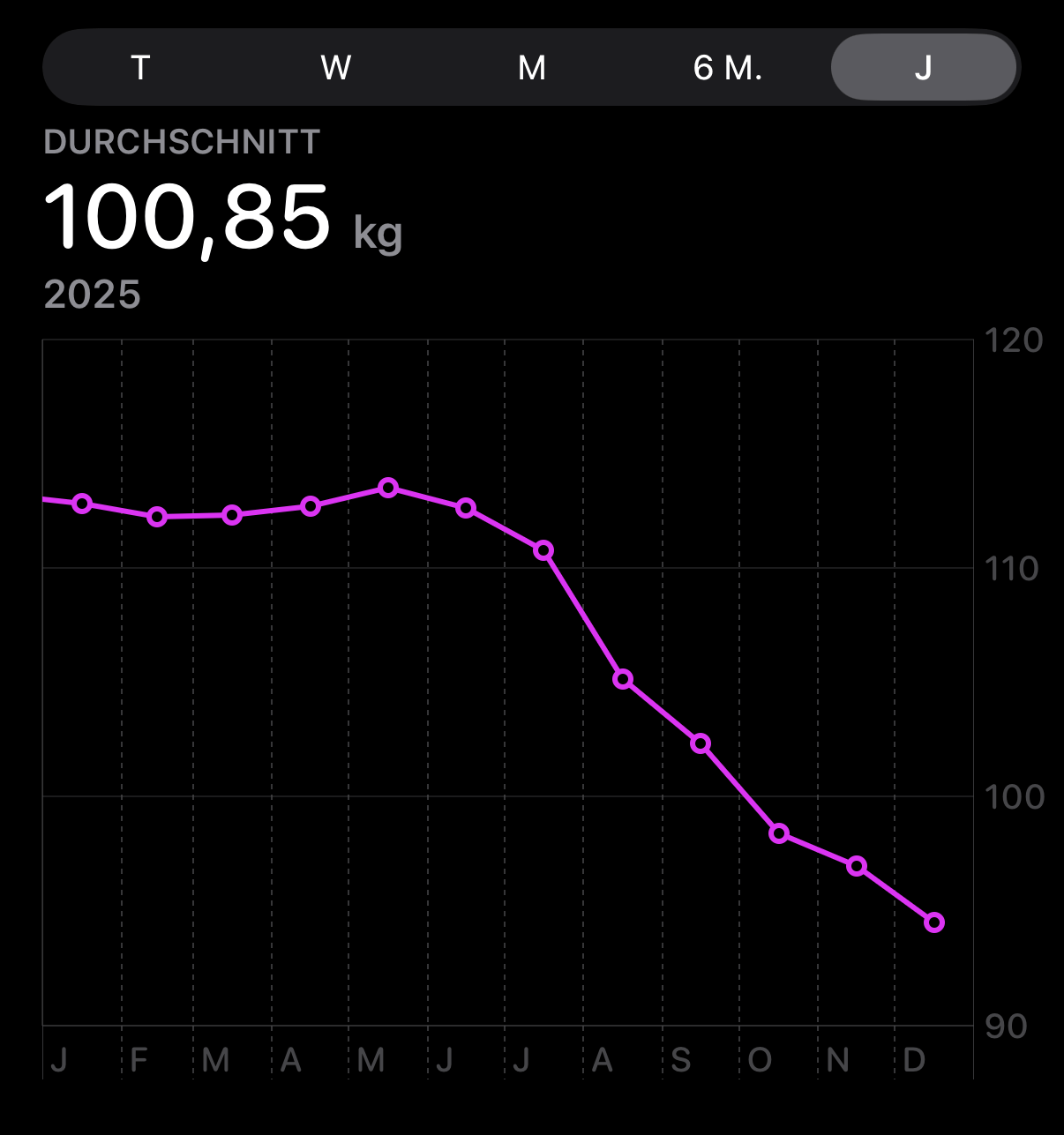
dieser artikel ist ein prototypisches beispiel für meine motiviation ins internet zu schreiben. gestern in der dusche habe ich darüber nachgedacht, wie man wohl transparente diagramme erstellen könnte. geschrieben hab ich den artikel also gar nicht in erster linie um meinen gewichtsverlauf in 2025 darzustellen, sondern um zu testen wie man diagramme am besten im web darstellt, bzw. welche optionen am besten funktionieren. natürlich visualisiere ich auch gerne meine daten, aber im fall meines gewichts visualisiert apple health ja bereits perfekt.
jahresverlauf meines gewichts in apple health
allerdings sieht der screenshot aus apple health eben nur im dark mode gut aus. und es fehlt der semaglutid-balken, den ich mir gestern unter der dusche als interessante visualierung vorstellte.
am ende sieht die apple grafik dann aber doch besser aus, als mein selbstgebasteltes diagram. aber immerhin hab ich unterwegs etwas gelernt und was zum bloggen.
beim ego-googlen bin ich heute auf wikimedia commons gelandet, wo ein foto von mir liegt, das ich vor > 10 jahren in vernonia (washington state) aufgenommen habe.
Teilen — das Material in jedwedem Format oder Medium vervielfältigen und weiterverbreiten und zwar für beliebige Zwecke, sogar kommerziell.
Bearbeiten — das Material remixen, verändern und darauf aufbauen und zwar für beliebige Zwecke, sogar kommerziell.
Der Lizenzgeber kann diese Freiheiten nicht widerrufen solange Sie sich an die Lizenzbedingungen halten.
Unter folgenden Bedingungen:
Namensnennung — Sie müssen angemessene Urheber- und Rechteangaben machen , einen Link zur Lizenz beifügen und angeben, ob Änderungen vorgenommen wurden. Diese Angaben dürfen in jeder angemessenen Art und Weise gemacht werden, allerdings nicht so, dass der Eindruck entsteht, der Lizenzgeber unterstütze gerade Sie oder Ihre Nutzung besonders.
Weitergabe unter gleichen Bedingungen — Wenn Sie das Material remixen, verändern oder anderweitig direkt darauf aufbauen, dürfen Sie Ihre Beiträge nur unter derselben Lizenz wie das Original verbreiten.
Keine weiteren Einschränkungen — Sie dürfen keine zusätzlichen Klauseln oder technische Verfahren einsetzen, die anderen rechtlich irgendetwas untersagen, was die Lizenz erlaubt.
aber mit der nennung im fuss, sind fotos von hier keinesfalls explizit mit der cc-lizenz gekennzeichnet. die lizenz müsste an jedem einzelnen bild angebracht werden und dann am besten auch maschinenlesbar. das ist einerseits das schöne an flickr, dass die bilder dort strukturiert liegen und so dass zum beispiel wikimedia bots die lizenz prüfen können.
um meine bilder hier ordentlich mit einer lizenz zu kennzeichnen, müsste ich:
jedes bild das ich hochlade mit einer, bzw. der cc by-sa 2.0 lizenz (oder besser der 4.0er version) auszeichnen — das geht bereits im backend
alle so gekennzeichneten bilder (such-) maschinenlesbar mit json-ld auszeichnen — das geht sehr einfach mit dem kirby-seo plugin, sobald die bilder im backend ausgezeichnet sind
bilder entsprechend mit einem icon oder link kennzeichnen — ein bisschen an den templates rumschrauben
für alle bilder eine einzelseite bauen, auf der die metadaten und lizenzinfos nochmal stehen und die bilder auch in vollauflösung runter zu laden sind —
alles relativ einfach machbar — aber wozu?
gute rhetorische frage, die ich mir hier selbst stelle und die antwort lautet: weils geht, bzw. weils richtig ist. ich habe mich gefreut, dass mein bild in der wikimedia commons liegt, und ich würde mich auch freuen, wenn es in der google bildersuche mit einer suche nach cc-lizensierten bildern auftaucht. und umgekehrt freue ich mich, wenn ich eine bildersuche benutze, um irgendwas zu bebildern, und ordentlich lizensierte bilder finde, deren lizenz eine weiterverwendung erlaubt.
für mich fühlt sich das an, wie die archivierung von schnappschüssen von archive.org, bzw. wie das was ich hier überhaupt veranstalte: ich halte dinge für mich, die jetzt- und nachwelt fest und hoffe, dass das was ich hier an gedanken oder eingefangenen bildern dokumentiere andere zum nachdenken bringt, inspiriert oder in irgendeiner form nützlich ist. wenn diese schnipsel, die ich hier veröffentliche, von meinem tellerrand in einen anderen teller überschwappen, dann freut mich das — solange die zuordnung oder rückverfolgbarkeit erhalten bleibt. und genau dafür sollte ja die lizenz sorgen.
deshalb schliesse ich hier auch keine ki-crawler explizit aus, ausser dass ich den zugang zu altem zeug erschwere. ob und wie das alles relevant ist, wen das interessiert oder nicht ist für mich eigentlich sekundär. mein vorrangiges ziel ist und war schon imemr hier dinge festzuhalten die mir wichtig erscheinen und dafür zu sorgen, dass sie gut zugänglich sind, sei es auf einer auf allen bekannten geräten einigermassen lesbaren webseite, per abonnierbarem RSS, über suchmaschinen, (KI-) chatbots oder eben strukturierte, maschinenlesbare daten.
alle die denken, dass man webseiten eher dafür benutzen sollte zu schreiben, als zu schrauben, sind ohnehin schon vor acht absätzen ausgestiegen, weshalb ich jetzt auch noch in ein technisches details gehen kann, das ich interessant finde.
mir ist nämlich seit ein paar wochen aufgefallen, dass in der bildersuche zu wirres.net teilweise (fremde) youtube-thumbnails auftauchten. das will ich eigentlich nicht, also ich will die originalthumbnails zur illustration von eingebetteten videos durchaus benutzen, aber zu eigen machen möchte ich mir sie nicht.
ich weiss nicht ob das meine idee war oder ob ein KI-chatbot mir dabei geholfen hat, aber diese anweisung in meiner .htaccess datei hilft, youtube-thumbnails, deren dateien ich lokal sichere, ausspiele und immer youtube_[ID].jpg nenne, von der indexierung auszuschliessen (durch einen noindex header):
<IfModule mod_headers.c># alle dateien, die mit "youtube_" beginnen (youtube thumbnails) # und ein bildformat haben<FilesMatch "(?i)^youtube_.*\.(avif|jpe?g|png|webp|gif)$"> Header set X-Robots-Tag "noindex"</FilesMatch># alle dateien die mit "noindex" beginnen<FilesMatch "(?i)^noindex.*\.(avif|jpe?g|png|webp|gif)$"> Header set X-Robots-Tag "noindex"</FilesMatch></IfModule>
ausserdem kann ich so bilder von der indexierung ausschliessen, indem ich den dateinamen einfach mit noindex beginnen lasse.
ich hab mal in einer steve jobs biographie gelesen, dass steve jobs versessen darauf war auch unsichtbare dinge schön zu gestalten. wenn ich mich recht erinnere war steve jobs vater hobby-schreiner und achtete sehr darauf, dinge gründlich und schön zu machen und entsprechend auch die eigentlich nicht sichtbaren rückseiten seiner möbel visuell ansprechend zu gestalten.
ich war aber auch schon lange bevor ich von steve jobs hörte mal selbst schreiner und entsprechend schon lange fan von schönen rückseiten und versteckten details, die — wenn überhaupt — nur von fachleuten beachtet werden.
hier auf dieser webseite war ich zunehmend genervt davon, wie schwierig es ist aus php-code schön formatierten quelltext rausfallen zu lassen. die einrückungen passen nie und schöner php code mit entsprechenden einrückungen führt fast nie zu schönem html code.
also fragte ich gestern cursor ob wir nicht das kirby html prettifyen könnten. herausgekommen ist ein plugin, der mit dem kirby page.render:after hook das gerenderte html durch html-pretty-min jagd. das ergebnis erfreut mich so sehr, dass ich es als kirby-plugin auf github veröffentlicht habe: github.com/diplix/kirby-html-pretty
ich finde das jetzt ordentlich und lesbar eingerückte html nicht nur schön anzusehen, es hilft mir auch beim debuggen. auf der rückseite hatte ich offenbar ein paar html-tags nicht ordentlich geschlossen oder strukturiert, was ich nie merkte, weil alle browser das stillschweigend korrigierten. html-pretty-min hat das etwas anders korrigiert und zwar so, dass es das layout leicht zerschoss. nachdem ich den quellcode der rückseite angepasst hatte, funktionierte alles so wie es sollte.
das minifizieren bringt theoretisch ein paar KB datenersparnis (die wahrscheinlich ohnehin nicht ins gewicht fällt, weil der server ohnehin komprimierte dateien ausliefert), aber dass überflüssiges leerzeichen verschwinden und die struktur insgesamt lesbarer ist, daran kann ich mich stundenlang erfreuen. das ist in etwa so, als ob ch mir selbst einen schrank baue und den mit den türen zur wand montiere, damit ich mich an dessen rückseite erfreuen kann. wie meine mutter schon sagte: manchmal muss man sich einfach auch mal ne freude machen.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}