unter den linden, zwichen ca. 1890 und 1900 (quelle)
an dem bild oben finde ich faszinierend, dass unter den linden wie in einem alten western aussieht. was ja auch nicht völlig abwegig ist, weil es die gleiche epoche ist, so um die vorletzte jahrhundertwende. und wenn man sich den google streetview aus der gleichen perspektive anschaut, fällt einerseits auf, dass die vermeintlich historischen strassenlaternen zumindest nicht die version aus den 1890ern imitieren und dass heute deutlich weniger pferdegespanne unterwegs sind als damals.
viktoriapark berlin zwischen ca. 1890 und 1900 (quelle)
dieses bild vom wasserfall im viktoriapark setze ich mir hier als reminder irgendwann ein foto aus der gleichen perspektive zu machen. obwohl dieses bild schon ziemlich nah dran kommt.
Wie erfüllend so Nichts sein kann Wie eine grosse, leere Kirche ist es hier – einfach ohne Gott (oder mit Gott, das ist wohl eine individuelle Angelegenheit) Das blosse Hiersein ist erholsam wie ein Saunabesuch – einfach ohne die Hitze
[Lindsay Ems] schreibt: „Mir wurde klar, dass die Amish der Technologie gegenüber eigentlich neutral eingestellt sind. Es ist für sie zweitrangig, worum es sich bei einer neuen Technologie handelt oder wie sie funktioniert; entscheidend ist für sie, welche Auswirkungen ihre Einführung auf die Gemeinschaft hätte.“
I became less intrigued by Amish restrictions on technology than by the social world they sought to preserve and protect with those restrictions. In the end, I came to realize that the Amish are, in fact, technology-agnostic. They do not care much about what a new technology is or how it works; they care about what its adoption would mean for the surrounding community.
lindsay ems buch über die amisch ist schon etwas älter (2022), auch wenn der artikel auf mitpress.mit neu ist. leider scheinen die inhalte des buchs bereits ein bisschen veraltet zu sein. so schreibt ems über den service pcfreemail, mit dem einige amish per fax emails schreiben und empfangen würden. den service gibts allerdings nicht mehr — nur noch auf archive.org.
aber darum gehts ja nicht, sondern eben darum, dass man sich fragen sollte/könnte, welche auswirkungen technologie auf die gemeinschaft hat. auch wir nicht amish tun das ja, man denke nur an die diskussionen um das social media verbit für jugendliche oder neil postmans buch von anno dazumal über die auswirkungen von fernsehen auf die gesellschaft. wobei wir als nicht amisch uns schon länger dazu entschieden haben, dass es ok ist, wenn technologie unsere gesellschaft verändert.
abgesehen davon, das ist ein schönes beispiel, dass religöse gebote durchaus auch etwas für unreligöse menschen bereithalten können. die drei C’s finde ich gut: danach streben ein vorbild zu sein, kritik annehmen und für eigene fehler einstehen.
One of my closest Amish contacts was Noah, a 57-year-old entrepreneur and self-described “technology buff.” Noah himself was a minister yet used a smartphone, email, and text messages, and even had a Facebook account. His usage was animated by the three C’s: conviction (modeling the right behavior), confession (asking others to hold you accountable), and contrition (being willing to own up to your mistakes). “Whether or not you use a technology is less important than how you use it,” he told me.
jetzt habe ich endlich mal ein pro-argument für pixelfed gehört, dass ich verstehe:
Mastodon kann ja immer nur die ersten vier davon anzeigen, aber Pixelfed kann mit mehr Bildern umgehen.
trotzdem: nur um mehr als vier bilder ins fediverse posten zu können werde ich mir kein pixelfed-konto zulegen. zumal die probleme die steffen hier beschreibt und die ihn zum umzug bewogen haben, genau die gleichen sind, denen ich auch aus dem weg gehen möchte.
„wir“ wundern uns ja immer über immigranten die trump wählen oder der afd nahe stehen. so nach dem motto: „verstehen die nicht, dass sie sich damit selbst schaden?“
wenn politiker hingegen verschärfungen des straf- oder zivilrechts fordern sind wir auch oft zu schnell an bord. populismus funktioniert, weil wir immer irgendwie denken, dass wir nicht mitgemeint sind, dass verschärfungen und freiheitseinschräkungen uns bestimmt nie betreffen werden. ich finde die wiederkehrenden forderungen scharf zu differenzieren von thomas fischer teilweise auch sehr anstrengend und gelegentlich bräsig, aber genauso finde ich sie wichtig und richtig. macht ja sonst kaum noch jemand.
Zwei alte Bücher mit Bukowski-Kurzgeschichten gefunden. Habe mal durchgeblättert; ich glaube nicht, dass ich das Zeug heute noch lesen möchte. In Zeiten des Heranwachsens war Charles Bukowski für viele eine große Sache. Anti-bürgerlich, verkommen und sowohl gegen rechte als auch gegen linke Lehrer zu gebrauchen.
Kurz kam mir auch wieder die Erinnerung daran, wie ich mit den Söhnen, als sie noch klein waren, einen vermeintlich lustigen Film aus meiner Kindheit sehen wollte, mit Bud Spencer und Terence Hill. Denn was hatten wir gelacht damals! In den ersten Minuten des Films wurden dann Frauen und Kinder geschlagen, wurde ohne Gurt Auto gefahren, wurde beim Familienessen geraucht und gesoffen. Ich hatte so viel spontanen Erklärungsbedarf, wir haben den Film dann nicht weitergesehen. Zumal auch keine einzige der Pointen bei den Söhnen funktionierte.
Tempi passati, das gilt oft auch für den Humor der Zeit.
dieses überwachsene gitter fiel mir heute früh auf. das sieht wirklich schön aus und so sollten eigentlich alle gitter und gullis dekoriert sein.
beim weitergehen fiel mir dann ständig weiteres grünzeug auf, dass sich über die blanken zivilisationsartfakte legt und lanfsam den asphalt aufbricht oder den stein verdeckt.
sugar s02e07 (läuft auf appletv) gesehen. das diner in einer szene kam mir bekannt vor.
also kurz in meinem externen gedächnis gesucht und daran erinnert worden, dass frank’s restaurant schon vor 11 jahren in sons of anarchy und the bridge mitgespielt hat. das internet sagt, in gone girl und parks and recreation hat es auch mitgespielt.
ich nutze ja einige dienste in der ATmosphere. die „ATmosphere“ sind anwednungen oder webseiten die man (verkürzt gesagt) mit seinem bluesky konto nutzen kann, die aber nix mit bluesky zu tun haben (müssen). leaflet erklärt das hier ganz gut für nicht-so-technisch-versierte:
grain ist das was instagram mal war: foto posten und verschlagworten und fotos angucken. dieser minimalismus, bzw. die konzentration auf das unkomplexe visuelle hat einen ganz eigenen reiz. ich beobachte mich wild dabei alles zu liken was mir gefällt und menschen deren fotos mir gefallen unbesehen zu folgen. bei textbasierten inhalten bin ich da meistens zurückhaltender oder bedachter. fotos sind so wunderbar niedrigschwellig und oft eben auch einfach schön.
das scheint in beide richtungen zu funktionieren. grain ist bisher der reaktionsstärkste AT-dienst den ich (testweise) nutze. auch das fühlt sich ein bisschen wie das frühe instagram an. posten, gucken, liken. nicht gross nachdenken. keine videos die einen fesseln und weiterswipen lassen. ein ruhiger fluss, kein jahrmarkt mit marktschreiern.
es ist wirklich einfach: wer ein bluesky (oder eurosky) konto hat, kann sich damit einfach bei grain anmelden. dein profil wird übernommen, lässt sich aber auch anpassen. alles sehr unkompliziert, keine popups, kein gedöns. grain steckt noch in der entwicklung, so gibts zum editieren von eigenen posts auf der website oder der app (ja, app gibts auch) keinen button, aber auf der website kann man einfach ein /edit an die url hängen und man ist im edit modus. posting per api ist auch möglich indem man auf den PDS schreibt.
bei solchen privat gestemmten projekten kann man sich natürlich — genau wie bei projekten der grossen plattformen — nie 100% sicher sein wie langlebig sie sind oder ob sie verkümmern, verscheissen oder kaputtgehen. deshalb mache ich es wie bei allen anderen diensten: fotos, beiträge erst bei mir veröffentlichen und dann syndizieren, also anderswo, zum beispiel zu grain, kopieren.
fragmentebloggt wieder. mindestens dreissig tage lang will sie das machen. ich bin sicher, sie wird danach weitermachen. ich habe nie aufgehört und doch vier jahre kaum bis nichts ins internet geschrieben. zumindest keine längreen texte. ich war beschäftigt mit hundeerziehung und brot backen und heimautomatisierung — und doch: gelegentlich musste ich die eindrücke aus meinem leben teilen. das hab ich dann vier jahre lang hauptsächlich auf instagram gemacht.
was ich sagen will: das leben ist auch schön ohne bloggen. aber mit bloggen ist es interessanter. ich habe das gefühl bloggen zwingt mich auf mehr, auf anderen ebenen zu denken. das denken strukturiert sich anders, mein innerer monolog bekommt eine zusätzliche stimme die versucht erlebtes anders aufzuarbeiten, als wenn ich es nur für meinen inneren monolog aufarbeiten würde.
normalerweise, beim einschlafen, wenn mein bewusstsein langsam in den hintergrund tritt und mein unter- oder neben- oder autonom-bewusstsein langsam die bilder und gedanken in meinem kopf übernimmt, sehe ich luftbilder. im wahrsten sinne des wortes. ich sehe schwarz mit leuchtpunkten, so als ob man nachts mit dem flugzeug in einer grossen stadt landet (und dabei aus dem fenster schaut). eine weite dunkle ebene, die mit lichtpunkten gespickt ist. das fliegen ist nicht das thema, es geht auch nichts um licht oder die dunkelheit. es ist offenbar einfach ein bild das beruhigend auf mich wirkt.
gestern sah ich beim einschlafen einen kleeteppich auf einer wiese. in den letzten tagen betrachtete ich auch im wachzustand sehr viele kleeteppiche auf wiesen und versuchte — im langsamen gehen — vierblättrige kleeblätter zu sehen. seit mehreren tagen vergeblich — aber nicht umsonst. auch diese kleeteppiche die ich im übergangszustand zwischen wach und unwach sah hatten auch eine beruhigende und befriedigende wirkung. aber obwohl ich eigentlich beim einschlafen war, dachte ich im gleichen moment, kurz vor dem wegdämmern, darüber nach ob und wie ich das wohl ins internet schreiben könnte.
ich mag es, wie mein vorsatz regelmässig ins internet zu schreiben meine wahrnehmung verändert. genau deshalb mag ich es auch, wie mein vorsatz weitere vierblättrige kleeblätter zu finden, auch meinen blick auf die welt verändert.
jedenfalls lese ich das was fragmente ins internet schreibt sehr gerne. gestern zum beispiel über urlaub.
Vor fünfzehn Jahren habe ich angefangen zu arbeiten, also außerhalb der akademischen Welt, in einem Angestelltenverhältnis, und ich habe seither nicht mehr aufgehört. Erst hatte ich 26, dann 28 und mittlerweile 30 Tagen Jahresurlaub. Aber mehr als drei Wochen am Stück hatte ich nie frei.
Es fehlt mir. Diese langen, staubigen, heißen Tage. Pläne immer nur bis übermorgen. Ein Badeanzug, irgendwas drüber, Sandalen und seit Wochen keine Socken. Schwimmbadpommes und Cornetto-Eis und Gummitiere. Mit dem Fahrrad unterwegs. Grillenzirpen und Rasensprenger.
Es war so nie, außer in meiner Erinnerung. Trotzdem.
mir ist urlaub egal. unseren letzten campingurlaub vor 10 jahren haben wir irgendwann abgebrochen und haben zuhause gemerkt, dass es viel erholsamer und schöner ist, zuhause urlaub zu machen. gelegentlich machen wir noch (kurze) städtereisen, besuchen freunde oder verwandete anderswo oder verbringen einen tag am strand. aber drei wochen am stück weg von den anehmlichkeiten und routinen zuhause? finden wir mittlerweile beide schrecklich. auch der hund sperrt sich dagegen anderswo als zuhause zu entspannen.
meine arbeitskolleginnen müssen mich jedes jahr dazu drängen meinen urlaub aufzubrauchen. einerseits finden sie es praktisch, dass ich mir über weihnachten und zwischen den jahren keinen urlaub nehme, andererseits ist es nervig wenn ich im november noch mit mehr als 20 tagen urlaub da sitze. um meinen urlaub aufzubrauchen nehm ich mir dann wochenlang einen tag pro woche frei. das strukturiert die woche ganz interessant. so kann man aus einer woche zwei wochen mit zwei wochenenden (einem langen und einem kurzen) machen:
mo | di | - | do | fr | -- | mo | di | etc.
ich arbeite gerne. aber ich stelle mir sisyphos auch als glücklichen menschen vor. kürzlich dachte ich einen gedanken wieder, den ich als kind schon öfter dachte; mit etwas abstand betrachtet ist es eigentlich schon ein bisschen absurd dass wir uns 20 bis 30 jahre ausbilden lassen um dann 5 × 8 stunden pro woche die fähigkeiten unseres ausgebildeten gehirns an einen arbeitgeber zu vermieten. andererseits ist es genau so absurd den ganzen tag durch die savanne zu latschen und nüsse und wurzeln zu suchen, um die dann zu verspeisen, zu schlafen und dann, nach dem aufstehen, wieder nach nüssen und wurzeln oder nach weniger gut ausgebildeten tieren zu suchen.
aber mit etwas abstand betrachtet ist ja wohl alles ein bisschen absurd. dreieinhalb milliarden jahre evolution, dreihunderttausend jahre menschheitsgeschichte damit ich hier auf dem sofa sitzen kann und über die absurdität der welt laut nachdenken kann.
ich suche weiter nach vierblättrigen kleeblättern. seit tagen erfolglos. mittlerweile glaube ich, dass ich die beiden einzigen vierblättrigen kleeblätter im wedding gefunden habe. which is natürlich quatsch. aber es fühlt sich so an. denn meine wahrnehmung funktioniert im prinzip. ich sehe immer wieder vierblkättrige kleeblätter, die sich dann aber leider immer als optische täuschung, überlagerung herausstellen.
dafür kenne ich mitllerweile die kleeinseln in und um den volkspark rehberge ganz gut, weiss wo das zeug wächst und erkenne mittlerweile auch die verschiedenen sorten. ausserdem hat das video von rabbithole (mein kommentar dazu) in der zwischenzeit etwas mehr verbreitung gefunden. bin mal gespannt wann ich die ersten 🍀-funde im netz sehe. weil grundsätzlich funktionieren die tricks aus dem video beim finden gut. grundsätzlich.
frida wartet währen dich auf den boden starre.
johnny ist immer noch auf substack (statt auf spreeblick), war auf der CSD trauerveranstaltung, hat ein bild-fernsehteam gesehen, still gegen die bild protestiert und ist viral gegangen.
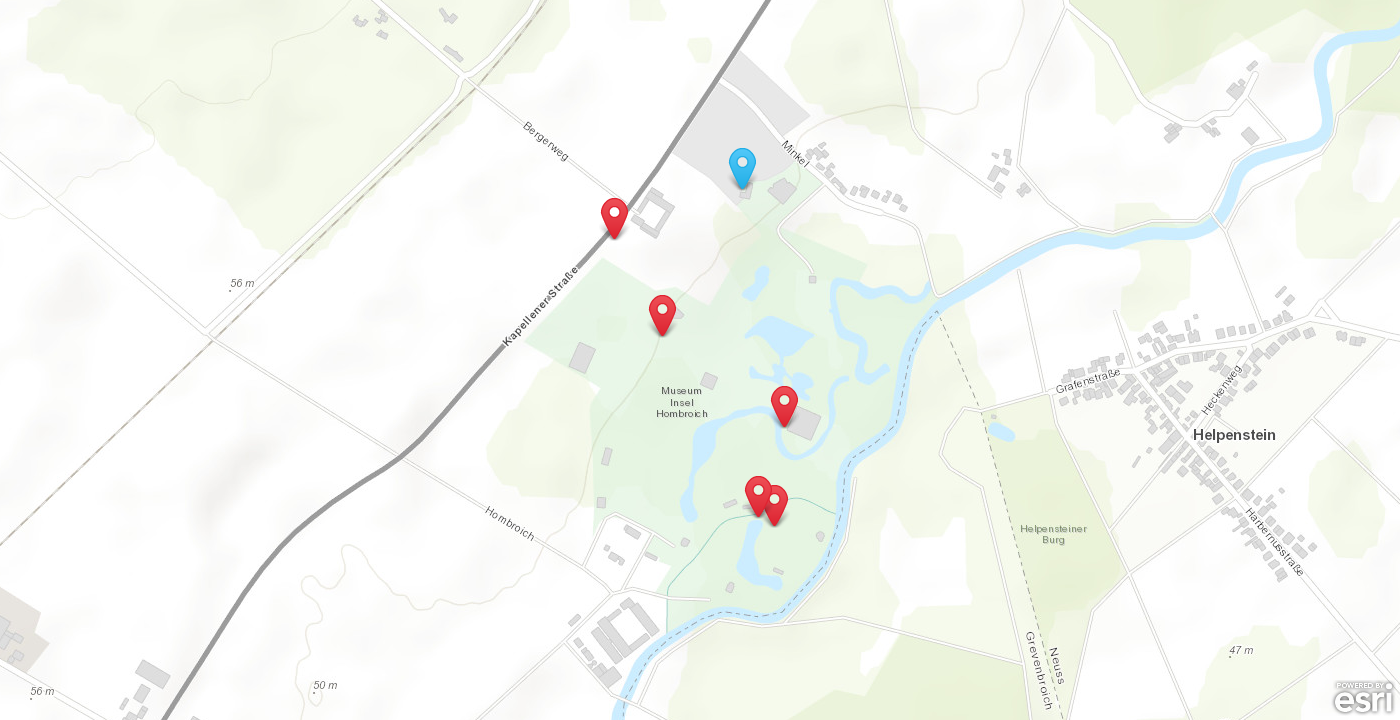
gestern bei der kaltmamsell gelesen, dass sie und herr kaltmamsell auf der museuminsel hombroich waren. an meinen letzten besuch dort erinnere ich mich als wäre es gestern, auch wenn meine erinnerungen daran leicht verblasst und verschmolzen sind. ich bin ja in der gegend mit den broichs aufgewachsen. fussbroichs, grevenbroich, korschenbroich, mörsenbroich, broichweiden waren namen sie ich in meiner jugend ständig gesehen habe. in der gegend gibt viele eigenartige ortsnamen. wenn wir nach aachen fuhren, passierten wir immer geilenkirchen (ecclesia erotica) und puffendorf (vicus lupanaris), auf dem weg nach düsseldorf gings an hombroich und grevenbroich vorbei.
jedenfalls liess sich mein internes gedächnis an den inselbesuch nicht mit meinem externen gedächnis verifizieren. ich habe hier nie etwas über die museumsinsel hombroich geschrieben oder bilder davon gepostet — oder kann sie nicht mehr finden. auch auf meinen social media profilen fand ich zunächst nichts. in meiner fotobibliothek fand ich dann über die ortssuche einen haufen bilder aus dem april 2011. mein archiv vom april 2011 zeigt schöne texte von der #rp11, aber nix von hombroich. mein twitterarchiv reicht nur bis 2012 (obwohl ich mich bei twitter 2007 angemeldet habe), mein erster instagram post ist vom oktober 2011 (lokale kopie). ich war mir aber sicher, dass ich zu diesem besuch etwas ins internet geschrieben oder gepostet hatte. mit spotlight fand ich dann einen hinweis in einer backupdatei auf dieses youtube video aus dem graphischen kabinett der museumsinsel, dass ich 2011 gepostet habe.
meine erinnerungen an die museumsinsel sind, wie gesagt, verwaschen. ich erinner mich aber sehr gut an die cafeteria. essen und getränke dort sind im eintrittpreis inbegriffen. die museumsinsel selbst erklärts (in einfacher sprache) so:
In der Cafeteria bekommen Sie ein kostenloses einfaches Buffet.
Das Essen kommt von Landwirt:innen und Lieferant:innen aus der Nähe. Darum ist das Essen besonders frisch.
meine erinnerung ist, dass es rosinenbrot gab. das brot war vorgeschnitten und es gab butter. die einfachheit dieser mahlzeit hat mich damals sehr begeistert. und die wespen auf der insel auch.
ich hab das schon öfter geschrieben, dass ich kunst die einem im alltag begleitet oder einfach entdeckbar ist interessant finde. meine eltern hatten nicht wenig kunst bei uns im haus und das zusammenleben mit diesen arbeiten öffnete permanent neue perspektiven. das alles funktioniert in einem museum auch, aber eben anders.
mir gehts in museen oft so, dass ich schnell gesättigt bin. beim sushi essen wird der ingwer traditionell ja nicht mit dem sushi gegessen, sondern zwischen verschiedenen sushi-sorten. damit verschafft man dem geschmackssinn angeblich eine erholung. und genau deshalb ist die musueminsel hombroich so toll. man wandert durch wunderschöne natur und stösst wie zufällig auf gefällige architektur in der oder um die kunst hängt, liegt oder steht.
natur@museumsinsel.homboich
mit dem prinzip der discoverability von kunst in der natur habe ich auch eine frühe kindheitserinnerung. meine eltern hatten bekannte die bei ludwig schokolade oder trumpf arbeiteten. ihr wohnhaus war ein frmen-bungalow, der direkt am park der familie ludwig lag und auch zugang zu diesem park hatte. der park war weitläufig und mit vielen skulpturen und bäumen gespickt. kristof und ich erkundeten den park regelmässig wenn wir bei den bekannten unserer eltern zu besuch waren. wir bekletterten die skulpturen und freuten uns über die abwesenheit von erwachsenen. der park war damals nicht öffentlich und ist heute mehr oder weniger komplett zugebaut. kunst einfach rumstehen zu lassen damit sie entdeckt, begriffen oder ignoriert werden kann, ist meiner meinung nach immer noch die beste art kunst zugänglich zu machen. mindestens genau so gut wie geschnittenes rosinenbrot.
die architektur, die bauten die auf der insel stehen sind einerseits typisch für die region und andererseits untypisch, weil geschmackvoll und minimalistisch. einfache geometrische formen umgeben von gezähmter, halb wilder natur. gelegentlich wird die natur getrimmt um die bauten zu ergänzen, an manchen stellen darf die natur machen was sie will.
auf den fotos der beifahrerin fummel ich ständig am handy rum. ich habe damals ganz offensichtlich beim besuch der insel an die verwertbarkeit im internet gedacht. sollte ich das noch rausfinden wo ich das damals gepostet habe, schreibe ich einen nachtrag. die fotos oben sind alle von der beifahrerin (mit einer Canon PowerShot SX200 IS powergeschossen). hier sind noch ein paar fotos die ich damals (mit einem HTC Incredible S) gemacht habe.
selfie anno 2011
falls das noch nicht deutlich geworden ist: ich kann einen besuch der museumsinsel hombroich sehr empfehlen. das museum ist in der nähe von düsseldorf und ist mit dem auto am besten zu erreichen. bus und bahn gehen auch, wenn man gut zu fuss ist.
gestern an der fischerpinte am plötzensee stand die tür offen. der ort ist einerseits sehr einladend und romantisch, aber gleichzeitig ein bisschen unheimlich. rechts auf einer liege hatte sich jemand zum schlafen gelegt.
zum erhalt der fischerpinte gibt es eine info-seite und eine petition. auf der info seite heisst es:
Nach dem Tod des bisherigen Pächters ist die Fischerpinte geschlossen. Wann es weitergeht ist eine Sache, die vom Amtsgericht geklärt werden muss – was danach entstehen könnte oder bleiben darf, dass ist Sache des Bezirksamtes.
Wir, als Anwohner des Wedding, setzen uns dafür ein, die Fischerpinte zu retten – im Einklang mit dem Naturschutz. Und mit den Booten, so wie seit über 100 Jahren.
[E]s ist jetzt alles ultra, alles transzendiert unaufhaltsam im Denken wie im Tun. Niemand kennt sich mehr. […] Junge Leute werden viel zu früh aufgeregt und dann im Zeitstrudel fortgerissen; Reichtum und Schnelligkeit ist, was die Welt bewundert und wornach jeder strebt […]
ich habe cursor mal meine apache logs auswerten lassen, wer in den letzten 14 tagen hier seiten aufgerufen hat. wie man sieht, machen offenbar suchmaschinen-indexer und echte besucher nur einen sehr kleinen teil aus. den grössten batzen machen hier täglich so um die 40-50 tausend bots oder scripte aus. im prinzip habe ich hier ein riesiges cache-warming botnetz.
RSS feeds häufig und von überall aus abzurufen ist durchaus im sinne des erfinders, aber wenn man das auf minuten runterrechnet, sind das im schnitt acht abrufe meiner RSS feeds pro minute.
bots & scripts
LLM
indexer
humans
Σ
seiten
43.000
4.800
4.200
400
52.400
RSS
10.900
-
-
1.000
11.900
.md
180
-
30
-
210
summe
54.080
4.800
4.230
1.400
64.510
eigentlich wollte ich sehen, wie die markdown-dateien angenommen werden. es zeigt sich: nicht schlecht, im schnitt 200 aufrufe pro tag, aber nichts gegen den abruf von 50 tausend html-seiten durch bots, scraper und indexer. die „humans“ zahlen sind auch eine optimistische näherung. das matomo-pixel das ich in den RSS feed gepackt habe tählt um die 400 RSS leser täglich, aber da mein matomo-host stats.wirre.net auf einschlägigen ad- und trackerblocker listen steht, dürfte 1000 leser ungefähr und mit etwas optimismus passen. die 400 menschlichen seiten-leser sind der tägliche schnitt laut matomo ohne optimismus zuschlag.
tl;dr: i’m blogging for the bots
interessant finde ich, dass rezepte mittlerweile dank google die meistbesuchten seiten hier sind (ausser der startseite). die zahlen sind auch aus den letzten tagen auf die unique pageviews pro tag runtergerechnet.
tl;dr: google schickt suchende nur noch auf rezepte.
zwei tage in folge beim morgenspaziergang kein vierblättriges kleeblatt gefunden, dafür heute eine gurke.
nachtrag:
ich hatte mir ja vor ein paar tagen in den kopf gesetzt morgens, beim spaziergang, immer ein vierblättriges kleeblatt zu finden. zwei mal hat das geklappt. dann, am freitag, habe ich intensiv gesucht und auch einige grosse, saftige klee-inseln gefunden. aber eben keine vierblättrige kleepflanze. das hat mich erstaunlich stark frustriert und natürlich ist diese angespannte, verkrampfte haltung beim kleeblattsuchen wohl eher kontraproduktiv. oder ganz allgemein im leben.
auch heute wollte ich gerne ein vierblättriges kleeblatt finden, aber mir war es viel egaler als am freitag. ich hab mich wieder ordentlich dem hund zugewandt und in erster linie auf frida konzentriert — was dann auch für gute laune bei mir sorgte. oder genauer, ich hab mich von fridas guter laune anstecken lassen und mich von meinem komische, selbstgestellten aufgaben nicht runterziehen lassen. trotzdem kein 🍀 gefunden, aber wieder viel darüber gelernt, wei man sich gekonnt selbst verarschen kann.
das war einerseits alles ziemlich vorhersehbar, weil ich das rezept für strange new worlds und star trek langsam in und auswendig kenne. obwohl das rezept stereotype und ungeniessbare zutaten hat, kommt am ende, auf der metaebene, doch immer was ansehnliches raus, was man zwar nicht essen will, aber schön anzusehen ist.
diese folge versucht auch explizit besondern klug zu sein und greift wieder rief in den temporalen bausteinkasten und was am ende rauskommt ist zwar albern, aber nicht doof. irgendwie ergibt sich im ganzen ein bild, das klüger ist als die summe des addierten quatsches.
mir fiel auf jeden fall auf, dass ich diese geschmacksrichtung star trek der noch pathosgetränkteren geschmacksrichtung star fleet academy um längen vorziehe. ich habe mich gut unterhalten gefühlt und musste mich über den quatsch und pathos nicht aufregen, weil das gesamtpaket passte.
nachdem ich zwei tage in folge jeden tag ein 🍀 gefunden habe, fiel mir enflich das deutsche wort für streak ein: strähne. weil man ja auch glückssträhne sagt.
vierblättrige kleeblätter zu finden hat natürlich nichts mit glück zu tun. weder das finden, noch das was einem danach passiert.
ich habe die 🍀 nicht wegen glück oder tüchtigkeit gefunden, sondern weil ich nach ihnen geguckt habe. so wie gabriella gerhardt in diesem video gesagt hat, man findet sie nicht, sondern man sieht sie. das klappt tatsächlich im (langsamen) vorbeigehen.
obwohl glück lösen 🍀 dann doch auch aus, aber eher glück im sinne von zufriedenheit. es befriedigt mich durchaus so ein 🍀 zu finden und mich dann wieder auf den morgenspaziergang konzentrieren zu können.
und ich würde da gerne eine gewohnheit draus machen. ein paar minuten pro tag in so etwas sinnloses zu investieren, das so befriedigend ist, hört sich für mich interessant genug an, um meinen ehrgeiz zu wecken. deshalb folgen hier in den nächsten wochen nicht nur unzählige baumbilder, sondern (hoffentlich) auch unzählige kleebilder.
ich hab in den letzten monaten immer wieder überlegt wie ich artikel von hier auf instagram bringen kann oder umgekehrt. auf instagram habe ich immer noch viele menschen die mir folgen, oder besser gesagt, die auf pflanzenbilder und selfies von mir reagieren. instagram selbst nutze ich selbst so gut wie gar nicht mehr, weil ich mich immer ärgere wenn ich die app offen habe und verführt werde kurze videos in mich reinzustopfen. zack sind 30, 40 minuten vorbei und ich ärgere mich, dass ich meine zeit nicht selbstbestimmt verschwendet habe.
die schwierigkeiten die instagram einem in den weg legt wenn es darum geht eigene inhalte von instagram zurückzuholen sind erstaunlich. instagramm gibt sich sehr viel mühe öffentliche beiträge nicht automatiert auslesabr zu machen, ausser man heisst googlebot. jedenfalls hab ich mehr oder weniger aufgehört auf instagram zu posten, weil das kopieren der beiträge von instagram hierher zu mühsam wurde und umgekehrt nicht möglich ist.
ausser man wandelt sein instagramkonto in ein professionelle konto um, meldet sich bei facebook als entwickler an, verknüpft sein facebook und instagramkonto und stellt an einigen stellschraben rum. nach langem zögern hab ich das jetzt gemacht und kann beiträge von hier einfach auf instagram posten — per knopfdruck im kirby backend.
im indieweb nennt man das posse: „Publish (on your) Own Site, Syndicate Elsewhere“
ich veröffentliche also hier ein foto und von hier dann zu mastodon, bluesky, standard.site — und jetzt auch zu instagram. und jetzt wo ich über meta/facebook auch eingeschränkten zugang zur API habe, kann ich auch kommentrae von instagram hierherholen.
so nutze ich zwar meta/facebook/instagram, aber wenn die mich morgen sperren solten oder ich sie oder meta verendet oder nur noch spanner-brillen verkauft ist mir das egal — weil ich nix verliere.
ich bin kein freund davon zu behaupten sei irgendwas oder gar alles besser gewesen. aber den zustand der isntagram-app, bzw. der instagram-timeline, würde ich schon gerne beklagen. alles ist unübersichtlich geworden, ständig will mir jemand was verkaufen oder mich hypnotisieren und meine aufmerksamkeit absaugen.
wie wohltuend ist da zum beispiel grain: ein vertikaler, scrollbarer sreifen mit fotos, nichts als fotos. und: dark mode, herzchen zum drücken und … fotos. ich schleiche zwar seit wochen durch die ATmosphere, aber auf grain hat mich heute nochmal pxlnv.com gestupst.
weil grain auf dem ATprotokoll basiert und die fotos und metadaten auf meinem, bzw. dem PDS von bluesky speichert, kann ich kirby auch einfach beiträge auf grain posten lassen (indem kirby eingach im richtigen format/schema metadaten und einen blob speichert). auch das geht aus dem kirby-backend per knopfdruck und sieht dann so aus.
warum nicht pixelfed? ich würde sagen weil es meinem verständnis von digitaler unabhängigkeit widerspricht mir ein weiteres social media konto anzulegen nur um einen weiteren ausgabekanal für das zu haben was ich hier auf wirres.net und meiner eigenen fediverse gotosocial instanz schon habe. bei grain hingegegn melde ich mich mit meinem vorhandenen bluesky-konto an und dort, auf dem bluesky PDS wird das auch alles gespeichert und ich kann mit den daten machen was ich will. keine reibung, kein zusätzlicher login, kein zusätzlicher API key, einfach ein weiterer kanal.
weil es so einfach ist bei diensten mitzumachen, die auf dem ATprotokoll aufsetzen, hab ich mir gedacht mal alle profile die ich im lauf der zeit angelegt habe aufzulisten. das ist auch ganz einfach, indem ich in meinen PDS gucke.
ich weiss nicht ob mein verständnis von unabhängigkeit richtig ist oder der reinen lehre entspricht, aber dieses possen fühlt sich gut an. alles zuhause an einem ort zu haben und da wo es geht, da wo es vielleicht wen interessiert, auch meinen quark hinschieben zu können. oder eben auch nicht. wiediewied es mir gefällt.





































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}