Verlage sind für freie Links und Überschriften; es ist nur fair, dass etwa Aggregatoren eine Lizenz brauchen, um ihre auf fremden Inhalten basierenden Geschäftsmodelle zu realisieren. Das Prinzip des Leistungsschutzrechts ist also: wer gewerblich nutzen will, muss fragen.
Die deutschen Verlegerverbände lehnen die Vorschläge zur Medienüberwachung entschieden ab. Für den Zeitschriftenverlegerverband VDZ lässt die Sicht des Berichts auf Pressefreiheit aufhorchen: Man beklage politische Einflussnahme und übe sie gleichzeitig aus. Man setze auf staatliche Co-Regulierung statt auf Selbstregulierung. „Seit wann braucht freie Presse eine Zulassung, die entzogen werden könnte?", sagte ein Verbandssprecher dieser Zeitung. Wer Lizenzen vergeben möchte, übe Kontrolle aus, teilte der BDZV mit. „Der Weg zu staatlicher Zensur ist dann nicht mehr allzu weit."
verleger meinen also, lizenzen seien einerseits der weg in den unrechtsstaat, andererseits „nur fair“? staatliche zensur ist mist, zensur durch verleger ein wichtiger beitrag für die pressefreiheit in deutschland? ich bin dafür das sich der vdz und der bdzv in veb (verband ehemaliger baumschüler) umbenennen.
judith horchert und konrad lischka versuchen sich auf spiegel.de über einen reisebericht der tochter von eric schmidt aus nordkorea zu empören. vielleicht wollten sich die beiden auch nur über die 19 jährige lustig machen und sind aus witzmangel aufs empören ausgewichen.
empörend finden die beiden beispielsweise, dass sophie schmidt schreibt pjöngjang sei „auf eine seltsame Art charmant“, obwohl sie doch wisse, „wie die herrschende Elite in Nordkorea herrscht - mit Gewalt, Abschottung und Propaganda“.
meine lieblingsstelle in horcherts und lischkas text ist diese:
Mancher Leser wird sich womöglich fragen, wie Eric Schmidt seiner Tochter erlauben konnte, dieses Geschwätz ins Netz zu stellen.
genauso kann man sich fragen, wie christian stöcker seinen beiden digitalressort-redakteuren horchert und lischka erlauben konnte ihr skandalisierendes gegeifer auf die angeblich „führende Nachrichten-Site im deutschsprachigen Internet“ zu kippen. vor allem da der lischka-horchert-artikel mindestens so irrelevant ist, wie die beiden glauben dass das „geschwätz“ von sophie schmidt irrelevant sei.
ich fand den artikel von sophie schmidt grösstenteils ziemlich gut, auch weil sie, anders als horchert und lischka, ohne stock im arsch ohne journalistenschulenüberheblichkeit schreibt und stellenweise fein beobachtet, beispielsweise als sie über einen computerraum an der kim-il-sung-universität in pjöngjang schreibt:
All this activity, all those monitors. Probably 90 desks in the room, all manned, with an identical scene one floor up.
One problem: A few scrolled or clicked, but the rest just stared. More disturbing: when our group walked in--a noisy bunch, with media in tow--not one of them looked up from their desks. . They might as well have been figurines.
Of all the stops we made, the e-Potemkin Village was among the more unsettling. We knew nothing about what we were seeing, even as it was in front of us. Were they really students? Did our handlers honestly think we bought it? Did they even care? Photo op and tour completed, maybe they dismantled the whole set and went home.
dieser raum hat auch für spiegel online eine gewisse attraktivität. er taucht in der fotostrecke des horchert-lischka-artikels als agenturbild auf, aber auch in der fotostreckeeines artikel aus dem dezember. man vergleiche den erkenntnisgewinn der spiegel-bildunterschrift, mit dem oben zitierten absatz aus sophie schmidts „geschwätz“:
In Nordkorea werden die Studenten mit moderner Technik ausgebildet - das soll wohl dieses Bild aus der Bibliothek der Kim-Il-Sung-Universität beweisen. Die Studenten werkeln an Computern - im Anzug.
an vater schmidts „knappen“ nordkorea-reiseberichtmonieren judith horchert und konrad lischka schliesslich, dass er nicht die „anderen Probleme“ nordkoreas erwähnt.
dankenswerterweise übernehmen die beiden diese herkules-aufgabe und nennen alle anderen probleme nordkoreas beim namen:
unerernährung
mangelnder zugang zu leitungswasser
zwangsarbeit
hunderttausende politische gefangene von denen tausende in menschenunwürdigen gefangenenlagern umgekommen sind
brutalität bei hinrichtungen und folter
am ende ihres artikels fordern judith horchert und konrad lischka dann etwas überraschend, dass tom grünweg künftig unter alle seine artikel schreibt, für welche probleme autos verantwortlich sind. die ansprüche, die man an teenager stelle, müsste man als deutschlands führende nachrichten-site schliesslich mindestens ansatzweise auch selbst erfüllen.
[den artikel habe ich beinahe mit „horchert hört ein hu!“ überschrieben, fand das aber gegenüber konrad lischka ein bisschen unfair und ausserdem völlig sinnfrei. den inhalt des letzten absatzes habe ich mir ausgedacht bevor ich gestern abend ins bett gegangen bin. gestern abend fand ich das noch witzig.]
gestern im mehringhoftheater mal wieder, nach acht jahren, fil im soloprogramm angeguckt. dabei fiel mir auf, dass fil bereits vor acht jahren über „die schwaben“ lästerte und sich jetzt nur noch über die schwabenlästerei lustig macht.
ebenfalls vor acht jahren hat irgendwer in der titanic sehr auf den punkt über fil geschrieben:
Und noch etwas kommt in FIL zusammen: Professionalität und Dilettantismus. Das Resultat ist kultiviertes Chaos. Nahezu vollkommen ist sein Timing, seine Geistesgegenwart, seine Pointensicherheit, sein Talent zum Sprachschöpferischen, seine Bühnenpräsenz. Dazu im reizvollen Kontrast stehen seine beschränkten technischen Fertigkeiten.
das gilt alles nach wie vor, eine sehr gesunde und unterhaltsame mischung aus fertig geschreibenem zeug und improvisation und publikumsverarsche. vor acht jahren dachte ich noch, fil habe das zeug ganz gross rauszukommen, jetzt zeigt sich, fil hatte das nie vor und das ist auch gut so. fil funktioniert auf der mattscheibe nicht mal halb so gut wie auf einer kleinen bühne.
abgesehen davon jongliert niemand so gut mit den metaebenen wie fil. er macht sich über alles lustig, über das lustigmachen, mütter, väter, zugezogene, einheimische, sich selbst, seine witze. mit all meiner kraft rufe ich jedem einzelnen (berliner) leser zu (und spendiere ein ausrufezeichen): hingehen!
ich bin johnny sehr dankbar, dass er mich, also uns, auf die aktuellen videos von ze frankhingewiesen hat. ich wusste zwar das er (ze frank) nach der kickstarter infusion was neues macht, habe aber nie nachgesehen ob er schon angefangen hat. so wie auch auch nie in den einen karton oben rechts im regal reingucke.
jedenfalls sind da ein paar wirkliche perlen des videoschnitts und der filmschnipselkommentierung zu finden:
zu weihnachten hab ich mal wieder ne küche gebaut, wie vor zwei jahren, nur diesmal in berlin. gekauft haben wir das ding trotz der expliziten warnung des spiegels bei ikea, für ungefähr 1500 euro. aufgebaut haben wir das ding über weihnachten, nachdem wir die raufasertapete abgekratzt haben, neu gestrichen und einen neuen PVC-boden haben auslegen lassen.
der küchenaufbau selbst hat ungefähr drei bis vier tage gedauert, was vor allem am installationgedöns, dem an die korpusse geschraubten blendwerk und dem mal wieder sehr stark gewölbten altbauwänden lag.
jetzt wo sie fertig ist ist sie um einiges praktischer und effektiver nutzbar als vorher — vor allem kann man jetzt dadrin mit mehreren personen am esstisch sitzen. die schubladen sind irre praktisch, die türdämpfer weiterhin ein nervenschinend, vor allem weil ich mehrere wochen die alte küche ohne türdämpfer nutzen musste und aus dem neuen wasserhahn schmeckt das wasser wie aus einem brunnen in den alpen.
falk lüke schrob (witzigerweise erlaubt er nur facebookmitgiedern den beitrag zu lesen, normale, nicht bei facebook eingeloggte menschen, dürfen das nicht lesen):
Facebook feels like a living corpse to me, everyone's sending, seeking even just a little attention for his/her life, a sad collection of loneliness in modern societies. And those who are listening are the algorithms of an ultra commercial platform run by a bunch of biz kids who never knew what they were doing. Dislike, strong - I'll be off this platform soon next year (as much as Facebook is allowing me and my content to leave it).
nach dem ersten kommentar, in dem daniel bröckerhoff sagte, dass man das eigentlich so für alle sozialen netzwerke und allgemein auch für das internet sagen könnte, antwortete falk lüke: „Woanders findet Interaktion statt. Hier kaum.“
als erstes fiel mir auf, dass die von falk lüke vermisste interaktion auch damit zusammenhängen könnte, dass der der beitrag auf englisch verfasst ist und damit zumindest tendenziell an der intendierten zielgruppe vorbeirauscht. denn auch wenn er das englisch etwas schnippisch mit „weil ich hier nicht nur deutschsprachige Kontakte habe...?“ erklärt, sind doch alle kommentare unter seinem beitrag ausnahmslos auf deutsch verfasst.
das problem das falk lüke möglicherweise hat, ist das gleiche das ein passionierter mau-mau-spieler in einer biker-kneipe hat; den kontext einer mitteilung oder aktivität sollte man nie aus den augen verlieren. wer das tut, ist am ende immer enttäuscht.
meine erfahrung mit facebook ist eine ganz andere. im privaten kontext funktioniert facebook bei mir ganz hervorragend. für mich fühlt sich facebook gar nicht wie eine „lebende leiche“ an, sondern wie ein algorithmisch optimierter blick durch ein schlüsselloch auf das leben meiner freunde, verwandten und menschen die ich schätze und liebe. tatsächlich filtert mir facebook freundlicherweise die statusmeldungen von leuten die mich weniger interessieren oder mir nicht sonderlich nahe sind recht zuverlässig aus. von falk lüke ist diese statusmeldung oben beispielsweise die erste seit monaten die ich zu gesicht bekam.
und auch falk lükes beobachtung einer „traurigen sammlung von einsamkeit“ auf facebook kommt mir eher vor, wie eine projektion der eigenen befindlichkeit, als eine objektive beobachtung. ich fühle auf facebook — oder genauer durch facebook — verbundenheit und nähe zu den leuten die mich interessieren. insofern scheint mir das „bunch of biz kids“ einen ganz guten job zu machen.
für mich ist falk lükes beitrag eher ein grund facebook noch hemmungsloser privat zu nutzen, also leute die ich nur vom hörensagen kenne zu entfreunden und mehr darauf zu achten, nur mit leuten verbunden zu sein, auf die ich privaten wert lege. für debatten und ausufernde diskussionen scheinen mir blogs eher geeignet zu sein, oder — wie ich von zeit zu zeit höre, aber nicht zu recht glaube — beispielsweise google-plus oder quora.
was ich auch gar nicht an falk lükes beitrag mag, ist seine susanne-gaschke-mässige verachtung von beiläufiger, trivialer kommunikation. leute wie susanne gaschke sind schockiert darüber, dass jedermann das internet einfach vollschreiben kann, auch mit irrelevanten, blödsinnigen oder flachen gemütsäusserungen (oder katzenbildern). die menschenverachtung die aus dem satz „everyone's sending, seeking even just a little attention for his/her life“ spricht, möchte ich gerne eins zu eins an falk lücke zurückgeben, den ich für eine der traurigsten und aufgeblasensten gestalten halte, die ich aus dem internet kenne. allerdings erst nach susanne gaschke — aber die nutzt ja eh kein internet ausser für wissenschaftliche und hochrelevante zwecke.
Immer wenn ich Robots.txt, die von Google bevorzugte Rechtesprache, kritisiere, hagelt es Vorwürfe der Lüge und Dummheit. Manche meinen, ich sei dumm und verlogen zugleich.
und dann zählt er eine liste von „Informationen“ auf, „die man in [eine] gute maschinenlesbare Rechtesprache eintragen können sollte, und die von anderen Marktteilnehmern zu berücksichtigen wären“. fast alle informationen die keese auflistet kann man bereits jetzt in verlagsprodukte die von verlagen ins netz gestellt werden eintragen oder genauso wie er fordert umsetzen. einige dieser informtionen werden vom axel-springer-verlag bereits auf seinen webseiten genutzt, viele nicht. was derzeit keine suchmaschine und kein aggregator auswertet, sind preisinformationen. diese wären aber ohne weiteres maschinenlesbar in jede verlagsseite einbettbar. sobald ein verlag anfängt diese maschinenlesbar eingebetteten preise für aggregation oder versnippung oder zugänglichmachung einzuklagen, werden suchmaschinen diese preisinformation garantiert sehr schnell beachten. allerdings ziert sich der axel-springer-verlag bisher sehr, diese preise irgendjemandem zu nennen. so sagte mathias döpfner kürzlich:
Nach Angaben von Döpfner hat das US-Unternehmen auch nach Jahren der Auseinandersetzung „noch nie nach dem Preis gefragt, der uns vorschwebt“.
auch die menschenlesbare „rechtesprache“ des axel-springer-verlags, beispielsweise die „nutzungsregeln“ die das springer-blatt „die welt“ ins netz stellt, zählen die rechte die keese gerne in einer maschinenlesbaren rechtesprache sehen möchte nicht sonderlich differenziert auf:
Der Inhalt der interaktiven Webseiten von DIE WELT ist urheberrechtlich geschützt. Die Vervielfältigung, Änderung, Verbreitung oder Speicherung von Informationen oder Daten, insbesondere von Texten, Textteilen oder Bildmaterial, ist ohne vorherige Zustimmung von DIE WELT nicht gestattet.
diese nutzungsrechte kommen mir vor, wie ein undiffertenzierter, grober, rechtlicher klotz oder in keeses worten ein „lichtschalter“. auf der webseite der welt kann ich ausser den oben zitierten groben nutzungsbedingungen (die defacto alles verbieten) keine informationen zur gewerblichen nutzung, lizensierung, aggregation, archivierung oder weitergabe finden.
tatsache ist, dass der grossteil von dem was keese hier fordert bereits existiert und in der praxis funktioniert. ich gehe keeses liste weiter unten mal im detail durch.
* * *
ich wundere mich in welche kategorie die aggregation von verlagsinhalten durch soziale netzwerke fällt. denn auf fast allen webseiten des axel-springer-verlags werden die nutzer (übrigens ohne differenzierung in gewerbliche und private nutzer) aufgefordert die inhalte über soziale netzwerke (twitter, google-plus, facebook) zu aggregieren. bei der nutzung dieser buttons kann es durchaus passieren, dass ich inhalte „an Gewerbe“ weitergebe. oder als gewerbetreibender inhalte an „Privatpersonen“ weitergebe. sollen twitter, facebook, google-plus küftig dann auch die maschinenlesbaren rechtesprache honorieren? muss twitter den „tweet“-button künftig für gewerbetreibende deaktivieren, wenn die seite maschinenlesbar als nicht-gewerblich-aggregierbar ausgezeichnet ist?
* * *
Name des Textautoren (✓)
machbar mit authorship-markup. wird auch auf vielen seiten des axel-springer-verlags eingesetzt. was ist eigentlich mit autorinnen?
es spricht aber nichts dagegen, den bildautoren in die maschinenlesbare bildunterschrift einzutragen. das geht bespielsweise mit einer bilder-XML-sitemap. damit kann man auch die bild-lizenz maschinenlesbar angeben.
[nachtrag 12.12.2012 23:33] mehrerekommentatoren und torsten kleinz weisen darauf hin, dass man autoren-informationen auch in den EXIF oder IPTC-daten von bildern abspeichern könne. damit kann man wohl auch die lizenz, bzw. lizeninformationen einbetten.
Name des Verlags (falls vorhanden) (✓)
welcher verlag hat denn in deutschland noch keinen namen? abgesehen davon ist es möglich den namen des verlags neben dem autorennamen anzugeben und wird beispielsweise so bei der welt gemacht. dafür kann kann man einerseits klassiche meta-tags nutzen, die es — glaube ich — seit ungefähr 20 jahren in dieser form gibt:
Name der Webseite (✓)
ist mit meta-tags, og-tags oder diversen microformaten möglich und das wird auch von den meisten aggregatoren und suchmaschinen ausgewertet:
Name der beauftragten Clearing- oder Abrechnungsstelle (✘) Name der das Recht wahrnehmenden Verwertungsgesellschaft (✘)
da es diese clearing- oder abrechnungsstellen offenbar noch nicht gibt, ist das natürlich unsinn eine angeben zu wollen. ich habe auch auf keiner webseite des axel-springer-verlags hinweise auf eine solche clearingstelle gefunden, weder maschinenlesbar oder menschenlesbar. gäbe es eine clearingstelle, lässt die sich sicherlich gut in die maschinenlesbaren lizenzinformationen (siehe unten) einbetten.
andererseits ist das für mich logisch schwer nachzuvollziehen; keese fordert, dass suchmaschinen etwas berücksichtigen für das erst durch ein leistungsschutzgesetz eine rechtliche grundlage geschaffen würde?
Einzuhaltende Zeitverzögerung bei Nutzung durch Dritte (✓)
das ist beireits jetzt unproblematisch umzusetzen. seriöse aggregatoren respektieren die robots.txt anweisungen die man auch einem einzelnen artikel mitgeben kann. es wäre also kein problem das verlagsseitig zu lösen: jeder artikel der erst nach einer bestimmten zeit durch dritte genutzt werden soll, bekommt einfach für die zeit in der er nicht genutzt werden darf einen robots-meta-tag:
<meta name="robots" content="noindex,follow"/>
sobald der artikel durch dritte genutzt werden darf, steht auf der seite
<meta name="robots" content="index,follow"/>
Gewerbliche Kopie erlaubt / nicht erlaubt (?) Preis für gewerbliche Kopie (✘) Maximal Anzahl der gewerblichen Kopien (?)
ich verstehe nicht was das genau bedeuten soll. ich fertige ja eine kopie in meinem browser-cache an, wenn ich eine webseite aufrufe. mache ich das beruflich, handle ich gewerblich. diese rechtsanweisung würde nur sinn machen, wenn es ein leistungsschutzrecht gäbe dass die gewerbliche nutzung (im sinne von lesen oder abspeichern, ausdrucken, in ein intranet kopieren) kostenpflichtig machen würde. danach sieht es aber nicht aus, denn selbst die CDU/CSU/FDP-koalition wollte sich auf diesen irrsinn nicht einlassen.
Gewerbliche Aggregation erlaubt / nicht erlaubt (✓)
verstehe ich auch nicht. 90 prozent der mir bekannten aggregatoren und suchmaschinen handeln gewerblich. ich kenne keine aus privatvergnügen betriebene suchmaschine. aggregation wird fast ausschliesslich von firmen berieben. diese gewerbliche aggregation lässt sich aber bestens mit der robots.txt ausschliessen. aggregatoren und suchmaschinen die für die aggregation zahlen möchten kann ja ein erweiterter robots.txt angeboten werden:
Preis für gewerbliche Aggregation (✘)
das wundert mich jetzt auch. laut mathias döpfner möchte der springer-verlag gar nicht sagen was soetwas kostet, sondern möchte danach gefragt werden (siehe döpfner-zitat oben).
wozu dann also eine maschinenlesbare information fordern, wenn der axel-springer-verlag diese information gar nicht öffentlich (mit)teilen möchte?
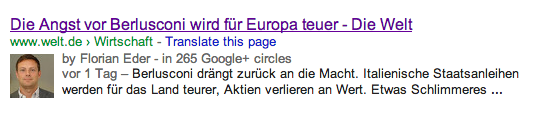
Maximale Länge der Aggregation (✓)
auch das lässt sich in der regel für alle möglichen formen der aggregation festlegen. facebook, google+, aber in den meisten fällen auch die google-suche, nutzen den text des description-tags. eine anweisung wie diese:
<meta name="description" content="Berlusconi drängt zurück an die Macht. Italienische Staatsanleihen werden für das Land teurer, Aktien verlieren an Wert. Etwas Schlimmeres könnte der Euro-Zone kaum passieren."/>
wäre der description-text kürzer, würde er auch kürzer angezeigt.
Gewerbliche Archivierung erlaubt / nicht erlaubt (✓)
auch die archivierung lässt sich per robots.txt oder dieser anweisung steuern:
<META NAME="GOOGLEBOT" CONTENT="NOARCHIVE">
da niemand private archivierung differnzieren, verbieten oder kontrollieren kann, reicht die robots.txt hier vollkommen aus: sie schliesst in der praxis ausschliesslich gewerbliche archivierung aus.
Preis für gewerbliche Archivierung (✘)
siehe gewerbliche aggregation.
Maximale Dauer der Archivierung (✓)
siehe gewerbliche aggregation; sollte es aggregatoren oder suchmaschinen geben, die sich dem lizenzmodell eines verlages für archivierung beugen wollen, kann mit diesen leicht eine anweisung vereinbart werden die das regelt, für alle anderen gilt noarchive:
Gewerbliche Teaser erlaubt / nicht erlaubt (✓) Preis für gewerbliche Teaser (✘) Maximale Länge gewerblicher Teaser (✓)
warum unterscheidet keese zwischen snippet und teaser? suchmaschinen und soziale netzwerke zeigen derzeit snippets an deren wortlaut und länge man mit dem description meta- oder og-tag festlegen kann. wozu an dieser stelle einer erweiterung auf komplette teaser? sollen suchmaschinen mit dem LSR eventuell dazu gebracht werden nicht nur snippets kostenpflichtig anzuzeigen, sondern auch teaser?
setzt man der einfachheit halber teaser mit snippets gleich, lässt sich die anzeige von teasern bei gewerblichen (also allen) suchmaschinen über die robots.txt steuern. wenn ein verlag die teaser einpreisen möchte, kann er das ja machen, alle anderen sollten dann auch verzichten dürfen:
Weitergabe an Privatpersonen erlaubt / nicht erlaubt (?) Preis für Weitergabe an Privatpersonen (?) Weitergabe an Gewerbe erlaubt / nicht erlaubt (?) Preis für Weitergabe an Gewerbe (?)
dafuck? was könnte keese damit meinen? was soll weitergegeben werden dürfen? ein artikel? ein suchergebnis? ein snippet? ein teaser? eine url? was bedeutet „weitergabe“? wie gibt man artikel auf webseiten in keeses sinn „weiter“? auf facebook? per mail? per usb-stick? als schwarz-weiss kopie?
Anzeige des Autorennamens zwingend / nicht zwingend (✓)
ah. hiermit soll wohl gezeigt werden: das #lsr ist auch gut für die rechte der autoren. auf allen seiten des axel-springer-verlages die ich stichprobenartig geprüft habe und auf denen authorship-markup verwendet wurde, zeigt sich in den suchergebnissen auch der autorenname.
Veränderungen erlaubt / nicht erlaubt (?) Mashups erlaubt / nicht erlaubt (?)
hat das etwas mit aggregatoren, suchmaschinen oder gewerblichen nutzern zu tun? an welcher stelle verändern oder mashuppen suchmaschinen oder aggregatoren verlagserzeugnisse? ist das ernsthaft ein problem? und wenn das so wäre, wäre es nicht ein anfang das in die nutzungsbedingungen der jeweiligen verlagsangebote zu schreiben? oder in die nutzungslizenz, die bereits jetzt in jede webseite maschinen- und menschenlesabr und einbettbar ist, per dublin core metadata oder rel="dc:license" (info) oder rel="license" (info).
* * *
[nachtrag 12.12.2012, 23:33]
viele der argumente die ich hier aufzähle hat bereits michael butscher in einem kommentar unter keeses artikel aufgelistet:
“Weitergabe an [...] erlaubt / nicht erlaubt”
Für die meisten Suchmaschinen/Aggregatoren nicht relevant, die geben allenfalls Snippets weiter und die vorherige Prüfung, ob der jeweilige Nutzer gewerblich ist, ist dann doch etwas viel verlangt.
Interessant wäre das allenfalls für Aggregatoren mit zahlenden (meist gewerblichen) Kunden. Für diesen Spezialfall ist das LSR aber überdimensioniert.
“Sie könnten auch das von mir skizzierte technische Zweistufenmodell verwenden: Wer ACAP unterstützt, darf zu den damit definierten Bedingungen, wer nicht, wird mit robots.txt/Meta-Tags ausgesperrt.”
Inzwischen weiß ich, daß der ACAP-Standard sogar schon einen Schalter enthält, der genau das tut (Ignorieren der robots.txt-Definitionen nach bisherigem Standard).
Dieser Schalter ergibt natürlich nur Sinn, wenn die Autoren von ACAP damit rechneten, daß eben nicht alle Suchmaschinen und Aggregatoren den ACAP-Standard unterstützen würden.
das acap-protokoll, auf das sich keese bereits einmal in aller länge bezogen hatte, lohnt sicher einen weiteren blick. ich frage mich aber, warum der axel-springer-verlag das protokoll nicht einfach nutzt. es ist abwärtskompatibel und die implementierung dauert laut acap-website keine 30 minuten.
und zumindest google liest die strukturierten daten des acap-protokolls durchaus ein, wie man in googles rich snippet tool sieht (klick auf „Google Custom Search“):















{kind=link}