ich will keine APPs, ich will APIs (meistens)
ich muss leider nochmal an einem teil meines publikums vorbeischreiben. das ATmosphere-rabbithole, in dem ich gerade stecke fasziniert mich gerade zu sehr, um das nicht aufzuschreiben.
man sagt ja: wenn man einen hammer in der hand hat, sieht man überall nägel. ich sehe im moment überall das AT-protokoll und die formate, bzw. lexika die dahinterstecken. mich fragen leute was der vorteil des standard.site-formats gegenüber RSS sei. der vergleich geht ein bisschen an der sache vorbei. die frage ist einfach: was sind die sachen die man mit einem protokoll machen kann, was sind die potenziale?
bereits 2002/2003, noch bevor es wordpress gab, hatte ich auf wirres.net bereits RSS (mit volltexten) eingebaut. weil ich potenzial, anwendungsfälle dafür sah — und weil es anwendungsfälle gab. ich weiss nicht ob ich es damals schon nutzte, aber netnewswire, also einen tollen RSS-reader, gabs seit 2002. 99,99% aller menschen interessierten sich damals nicht für RSS (und blogs), aber die die es nutzten fanden es grossartig, weil es grossartig und praktisch war.
mike masnik erinnert sich an das internet von damals, dass es angeblich nicht mehr gibt und von plattformen und apps zerfressen und zerfasert wurde. allerdings mit dem twist, dass das einerseits nicht stimmt, das alte internet ist noch da, und es keimt unter dem plattform-beton gerade wieder auf.
mike masnick:
But, as Godier’s piece notes, protocols are… boring. They change slowly (for a good reason, because you need stability to build on). They tend to change by consensus, which is messy. And rather than having billion dollar companies throwing a whole massive engineering team at making everything work, in the protocol world, we rely on constant experimentation by anyone who wants to experiment.
The open web of the nineties didn’t win because the tools were better. It won because a critical mass of people decided that the alternative, a handful of AOL-style walled gardens choosing what everyone saw, was not the future they wanted. Then they built their way out of it. Slowly, unglamorously, in rooms that looked a lot like this one.
Whether atproto ends up being the thing, or a stepping stone to the thing, I don’t know. Nobody in the room claimed to know. But the work is real, the apps are shipping, and the people building them are taking it seriously without taking themselves seriously. That combination is rare, and historically, it’s the one that wins.
das entscheidende und spannende, damals wie heute, sind nicht die grossen visionen, die massenwirksamen apps und plattformen, sondern die greifbareren, jetzt nutzbaren werkzeuge die genutzt, ernsthaft weiterentwickelt werden und funktionieren. die arbeit im maschinenraum ist real. nicht meine, sondern die von tausenden frickelnden menschen, auf deren schultern man sich stellen kann und ihre werkzeuge mitbenutzen kann.
gestern habe ich eine liste von ein paar apps die auf dem AT-protokoll aufsetzen veröffentlicht die funktionieren und mit denen man spannenede sachen machen kann.
- bei sill meldet man sich mit seinen bluesky- (oder beliebigen anderen ATproto-) login an und bekommt ohne weiteres zutun eine von seinen bluesky- (oder mastodon-) kontakten kuratierte und gewichtete linkliste.
- bei margin meldet man sich mit seinen bluesky-login an und sieht bookmarks, anmerkungen oder hervorhebungen von textbasiertem zeug aus dem internet von allen menschen in der ATmosphere — und sicher auch irgendwann eine filtermöglichlichkeit auf menschen denen man folgt.
- mein sifa-profil zeigt ohne weiteres zutun von mir auch meine bei popfeed als gesehen markierten serien und filme an.
das tolle am AT-protokoll ist, dass sich dienste und menschen auf basis dieses protokolls — und seiner (beliebig) erweiterbaren, strukturierten lexika — verbinden können. eine gemeinsame, offene, gestalbare sprache ist die basis von gemeinschaft.
man muss meine (aktuelle) begeisterung für protokolle nicht teilen. ich interessiere mich zum beispiel sehr wenig für den CAN bus oder das OBD-II protokoll. aber ich weiss, dass man mit ihnen spannende sachen mit autos machen kann. vor allem weiss ich, dass standardtisierte, offene protokolle jede technologie soweit voranbringen können, dass sie für jedermann und jederfrau nutzen bringen. kaum jemand interessiert sich für TCP/IP, http oder SSL, aber mittlerweile nutzten sie fast alle und freuen sich darüber, ohne zu wissen worüber sie sich freuen.
für mich ist wirres.net die quelle der wahrheit. nicht in dem sinn, dass alles was hier geschrieben steht stimmt, sondern das alles was ich ins internet schreibe und poste seine heimat hier hat. ich veröffentliche hier und verteile anderswohin. in ausnahmen veröffentliche ich auch anderswo, aber dann hole ich es auch wieder hierher. dafür gibts die beiden indieweb-begriffe POSSE und PESOS, aber das ist egal, weil das grundprinzip wichtiger ist, als wie man es nennt. der entscheidende punkt ist, dass ich einerseits hier alles an einer stelle beisamen und persistiert haben möchte und andererseits aber auch die menschen dort erreichen möchte wo sie gerade sind.
- meiner mutter schicke ich automatisiert jeden artikel per mail. technikartikel wie diesen ignoriert sie einfach, zu langen, pseudophilosophischen texten schreibt sie mir fast immer zurück.
- ich weiss dass (relativ) wenig menschen lust haben wirres.net in ihrem browser aufrufen, es aber gerne im RSS-reader ihrer wahl lesen. deshalb stelle ich RSS-feeds zur verfügung und gebe mir grosse mühe dass sie gut funktionieren und keine (oder wenig) einschränkungen zum original haben.
- selfies poste ich weiterhin in kopie auf instagram, weil die menschen auf instagram aus mir unbekannten gründen gerne selfies und blumen sehen.
- fotos und links zu manchen längeren artikeln poste ich auf bluesky und mastondon, weil es dort menschen gibt, die gerne auf diese art daran erinnert werden, dass ich ins internet schreibe und fotos poste.
- filme und rezensionen zu filmen kopiere ich gelegentlich auch auf letterboxed, weil es dort (vielleicht) leute gibt die sie auf wirres.net nicht gefunden hätten und sich (vielleicht) über meine rezension freuen.
- ich mache wieder checkins mit swarm, weils geht und es für mich der einfachste weg ist fotos mit text auf wirres.net zu posten (mit ownyourswarm). gelegentlich favt auch jemand checkins von mir auf swarm.
die liste kann ich fast beliebig weiterführen, der entscheidende punkt ist, dass die gezielte verteilung meiner inhalte im internet einerseits anderen entgegegnkommt und andererseits die beschäftigung mit interessantem technik-gedöns bedeutet.
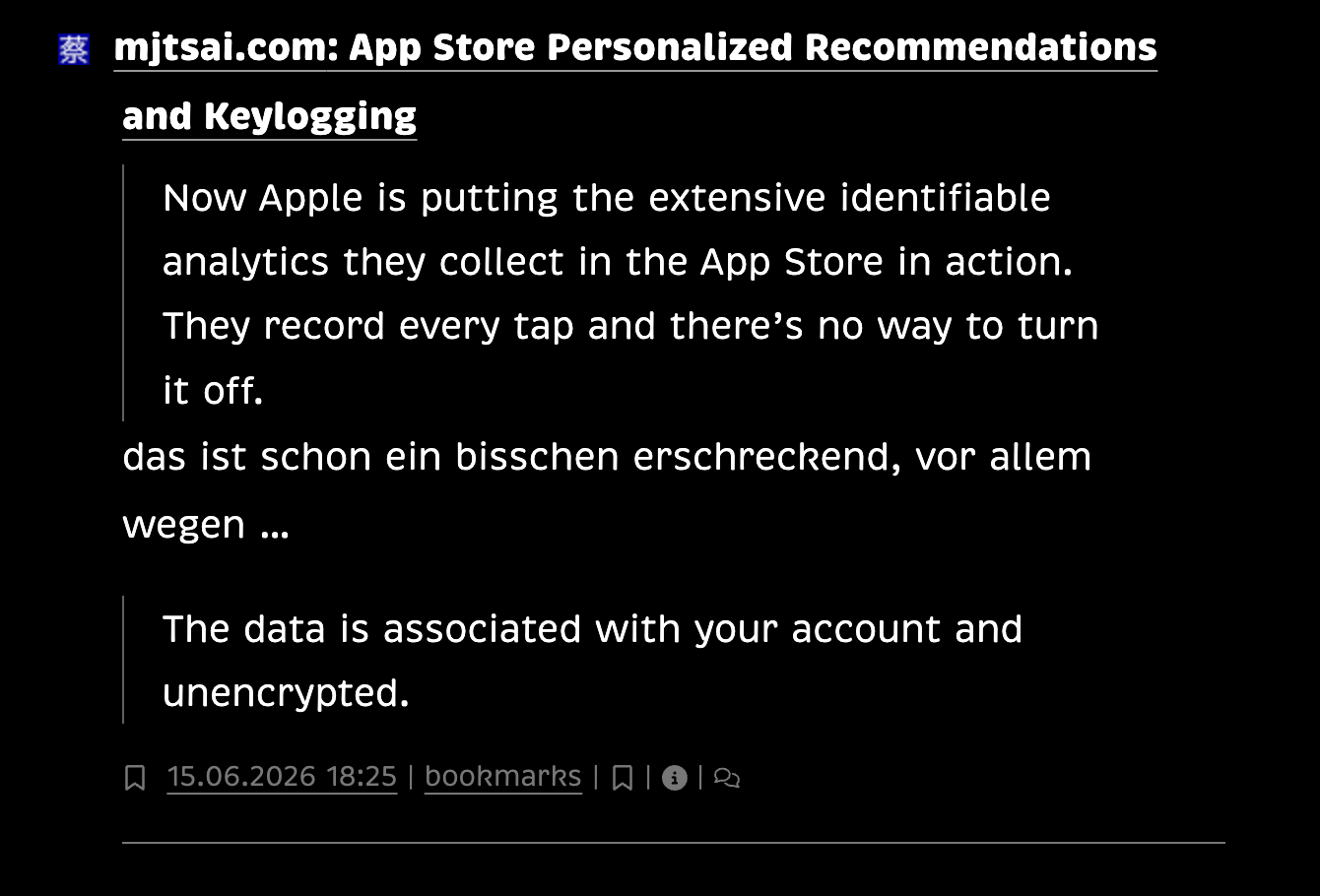
artikel im volltext mit dem standard.site protokoll in die ATmosphere zu blasen ersetzt RSS nicht. aber es eröffnet neue potenziale der entdeckbarkeit, von empfehlungs- und interaktionsmöglichkeiten. wenn ich einem RSS feed folge weiss das niemand. wenn ich einer standard.site publikation folge, wie zum beispiel nicos couchblog, sieht man das hier oder auch hier.
wenn ich ein bookmark in meinen river werfe sieht das kaum jemand. man kann die bookmarks zwar per RSS abonnieren (oder alles, wirklich alle abonnieren), aber vielleicht ist es ja besser dieses bookmark auch in einer dezidierten bookmarkanwendung finden zu können. hier zum beispiel. oder hier. wenn man sich mit seinem bluesky-login dort angemeldet, kann man mein bookmark kommentieren, weiterverteilen, faven oder selbst sichern.
das verteilen meiner artikel oder bookmarks ist und war nicht kompliziert. ausser schreibzugriff auf mein (bluesky) PDS (per app-passwort) brauche ich nichts weiter. kirby schickt dann ziemlich leichtgewichtige json-blobs an den PDS und fertig. obwohl margin.at keine ausgewachsene API hat, kann ich dort bookmarks, anmerkungen oder markierungen einfach (per knopfdruck) aus meinen ohnehin vorhandenen bookmarks auf wirres.net senden. ich brauche keine margin.at-app, das AT-protokoll reicht. wobei eine margin-app (fürs handy) gibts eh nicht, wohl aber eine chrome extension. die brauche ich dank des protokolls nicht zum anlegen von bookmarks, aber sie ist trotdem toll, weil zitate die ich ins bookmark kopiere, dann mit der extension in chrome auch auf der seite markiert werden.
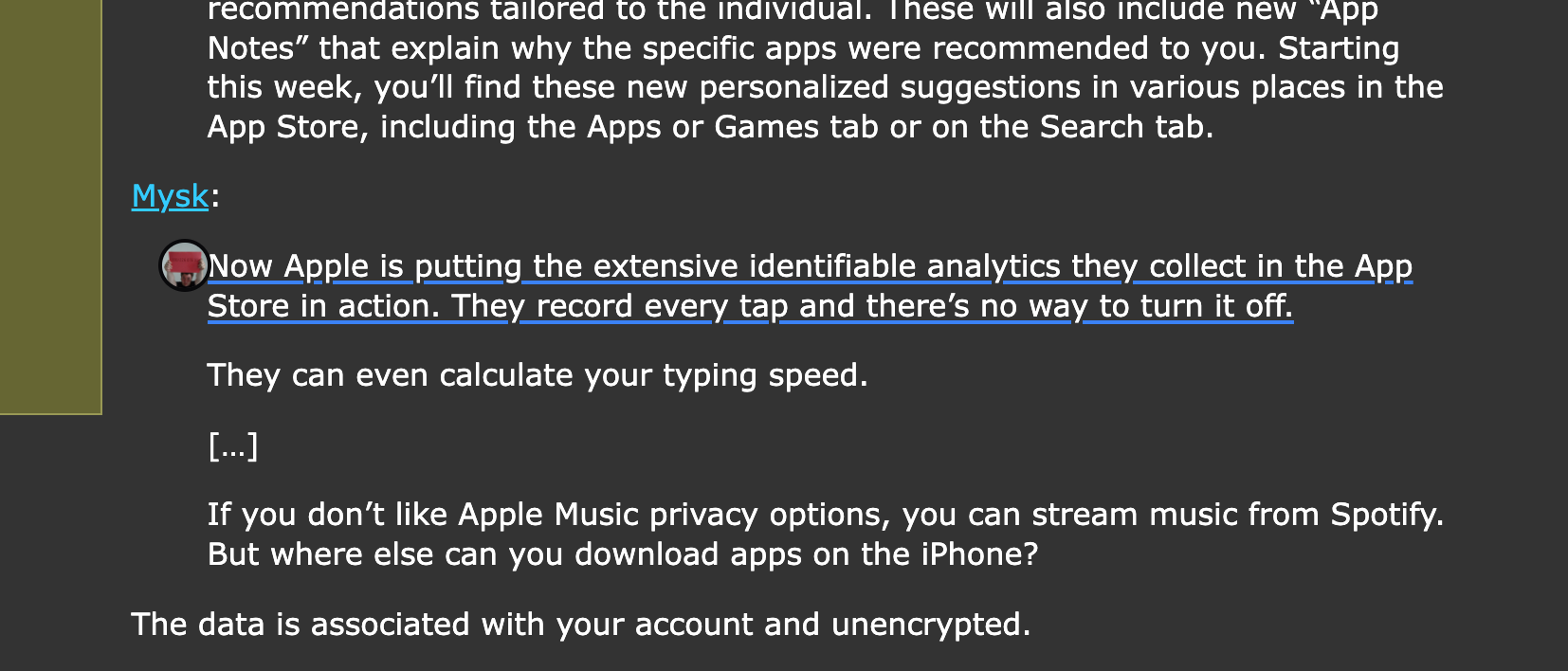
diese markierung wäre dann auch sichtbar für jemanden der bei margin.at angemeldet ist und die chrome extension installiert hat.
ich weiss, alles technische, komplizierte spielereien deren nutzen zweifelhaft oder zumindest nicht sonderlich weit verbreitet ist. null relevanz. aber so viel potenzial.
um nochmal das zitat von tim trautmann von oben zu wiederholen:
Whether atproto ends up being the thing, or a stepping stone to the thing, I don't know.
weiss niemand, ob das zu was führt oder jemals von normalen menschen adaptiert wird. aber interessant ohne ende isses schon — und es funktioniert.
die überschrift („ich will keine APPs, ich will APIs“) habe ich ein bisschen im text vernachlässigt. das hole ich jetzt nach.
mir ist das schon seit vielen jahren aufgefallen, dass viele hersteller von sachen glauben, dass ihre sachen eine app brauchen. in der praxis geht das oft völlig am bedarf vorbei. bei der heimautomatisierung setzt sich (j sei dank) langsam die erkenntnis durch, dass es keinen sinn macht wenn der kühlschrank, die spülmaschine, der airfryer, der staubsaugerroboter und die lichter jeweils eine eigene app haben. langsam setzt sich (dank matter) die erkenntnis durch, dass offnene protokolle der weg sind, mit denen technisch komplexe sachen irgendwann mal akzeptanz finden können.
mit protokollen kann ich mit den sachen entweder machen was ich will oder etablierte, stabile systeme eines herstellers meiner wahl nutzen. im fall von heimautomatisierung zum beispiel home assistant, homekit, google home oder dieses alexa-gedöns.
wedium hat den schuss offenbar nicht gehört. wedium, das ich seit der republica „testen“ darf, erscheint mir als das langweiligste, verschlossenste und nutzloseste „soziale Netzwerk“ der welt.
im web ist wedium nicht zugänglich, beiträge sind auch nicht ausserhalb der app teilbar. der share-button in der app kopiert lediglich eine url des beitragsbildes. ich kann auf ios noch nicht mal aus der photos-app ein bild per share-button zu wedium sharen. nicht eine schnittstelle habe ich in der beta-version der app gesehen.
aber das ist neben dem „sozialen“ der ganze witz an einer netzwerk app: dass man sie vernetzen kann, dass man mit APIs spielen kann, potenziale ausloten kann, dass man als nutzer die app besser machen kann, indem man mit auf dem netzwerk rumhackt. völlig unverständlich, dass man bei wedium glaubt nicht nur das rad netzwerk neu erfinden kann, sondern dass man es auch von null auf besser machen könne.
so überwältigt ich in den letzten paar tagen vom AT-protokoll war, davor ganz ähnlich vom fediverse und activityPub fasziniert war, so unterwältigt bin ich von wedium.
wenn wedium schon das marketing verkackt, wie soll das dann erst mit der eigentlichen maschine klappen? bei der konkurenz? also konkret den grossen (über-) mächtigen plattformen und den vielen kleinen, spannenden, lebhaften und dynamischen projekten, die auf offenen protokollen aufsetzen.
spannende zeiten, aber höchstwahrscheinlich nicht für wedium.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
andrew von @theartofstirytelling erklärt nachvollziehbar warum manche geschichten von star trek zeitlose klassiker sind, die in der oberliga der erzählkunst mitspielen. und in einem 5 sekunden-schlenker zeigt er auch, warum das bei den aktuellen inkarnationen der serie oft nicht mehr funktioniert: die funktionieren oft deshalb nicht, weil sie die moralischen konflikte zu offensichtlich und zu eindeutig präsentieren. gute geschichten fordern ihr publikum heraus, indem sie nachvollziehbare gegensätze zeigen und die grenzen zwischen richtig und falsch ausloten.