park am nordbahnhof

ein bisschen sonne …
ein bisschen sonne …
ich liebe youtube. also nicht youtube an sich, aber videos auf youtube zu sehen. im monat zähle ich ungefähr 50 stunden, die ich vor der tube sitze. ich habe auch grossen respekt vor dem algorithmus der mir die videos zusammenstellt. die mischung der videos ist interessant genug um mich bei der stange oder tube zu halten, aber ich bekomme trotzdem keine schwurbler-videos vorgesetzt oder videos in die timeline gespült, nur weil sie gerade „trenden“ oder so. youtube ist meine guilty pleasure, mein gar nicht mal so heimliches laster1.
wer den videos die ich mag folgen will, alle videos, unter die ich einen positiven daumen setze, landen im favoriten stream (RSS).
als ich gestern ein video von der 2MR Konferenz sah, habe ich zunächst gar nicht gemerkt, dass es kein youtube-video war, saondern auf peertube lag. um es so auf wirres.net einzubetten wie ich es mag (ohne explizite freigabe kein fremdcode oder iframe oder javascript von drittservern), musste also ein neuer embed block her. cursor und claude konnten das schnell umsetzen und das funktioniert auch, wenn ich ein peertube-video fave (beispiel).
soweit das neue aus dem maschinenraum.
was mir dann aber noch auffiel: ich muss mich bei jeder peertube-instanz separat anmelden, wenn ich dort übeer den browser einen echten fav hinterlassen will. das ist ja eigentlich bei allen fediverse instanzen so, egal ob mastodon oder gotosocial oder pixelfed. im browser stehe ich immer dumm unangemeldet da. ich weiss, ich kann die url der peertube seite in meinem mastodon client im suchfeld eingeben und dann interagieren (faven, kommentieren), aber warum dieser umweg? im indieweb gibts indieauth was wirklich einfach zu nutzen ist und mit dem man sich über die eigene webseite anmelden kann. das ist so dezentral wie es nur sein kann und ich frage mich, warum können fediverse instanzen nicht auch identity-provider sein? wenn ich mich an beliebigen fediverse instanzen, die ich im browser besuche, einfach so anmelden könnte um dort zu interagieren, wäre das aus meiner sicht ein echter fortschritt in sachen bedienfreundlichkeit und konsistenz. oder übersehe ich etwas? gibts das schon? oder ist das komplizierter als ich gerade denke?
ich gucke youtube werbefrei in safari, ohne youtube dafür geld in den rachen zu werfen. der trick ist eine safari erweiterung namens vinegar. vinegar tauscht einfach den youtube-player mit dem nativen browser-player aus und umgeht damit die werbung. das funktioniert so gut, dass youtube in meiner anseh-historie sogar werbeclips anzeigt, die ich angeblich gesehen hätte, aber nie gesehen habe. das heisst im umkehrschluss, den youtube-kreatoren entgehen dadurch keine werbeeinnahmen und ich muss den scheiss nicht sehen. ↩
über den metabene newsletter bin ich auf dieses video gestossen, in dem robin thiesmeyer (meta bene), rocko schamoni und marc-uwe kling über „offene soziale Netze“ reden.

am anfang zeigt robin eine kurze präsentation, in der er sich vorstellt. ich fand das sehr witzig.
… weil ich minimalist bin, als ästhetisches konzept, das kennen sie vielleicht, das is ne sehr anstrengende art von faulheit …
der rest war nicht so lustig, weil die drei, vier auf der bühne, dann über reichweite und monetarisierung reden. über reichweite reden oder nachdenken ist immer irgendwie traurig. wenn einen keiner liest (oder sieht), ist man traurig, wenn man merkt dass ein paar leute das lesen oder sehen was man ins netz veröffentlicht, ist man auch traurig, weil andere ja bestimmt mehr aufmerksamkeit bekommen. und wenn man 1000 follower oder abonnenten hat, ist man traurig, dass man nicht 2000 hat.
damit will ich mich keinesfalls über die drei auf der OMG 2MR-bühne lustig machen, sondern es ist eine erfahrung die ich in den letzten 30 jahren gemacht habe. noch trauriger wird es, wenn dann neben reichweite auch noch über monetarisierung gesprochen wird, weil beides wahnsinnig schwer ist und mit diesen „offenen sozialen netzwerken“ noch schwerer. und wenn man wirklich viele leute erreichen will, muss man sich gegebenenfalls auch noch verbiegen und die angebote von amerikanischen tech-buden in anspruch nehmen und sich da an absurde regeln halten oder mit bürokartischen bots auseinandersetzen.
wenn mich am montag alex matzkeit in seinem panel auf der republica fragt, wie es denn damals in den frühen tagen der blogosphäre war, werde ich möglicherweise (auch) sagen: wir konnten uns für eine kurze weile einbilden viel reichweite und eine gewisse relevanz zu haben. einbildung deshalb, weil das vielleicht eine relativ hohe reichweite war, aber absolut eher nicht. wir haben halt in unserer blase „gebloggt“ und gelegentlich vergessen, dass unsere blase eigentlich teil eines riesigen schaumteppichs mit milliarden anderen blasen ist.
unsere blogoblase (vielleicht ein besseres wort als blogoshäre?) hatte allerdings eine eigenschaft, die die reichweite vermeintlich massiv erhöhte: die blogoblase hatte viele schnittstellen mit der journalisten-blase. deshalb gab es multiplikationseffekte und gelegentlich sowas wie gefühlte relevanz. aber meine these ist, dass „wir“, die bloggenden menschen der frühen 2000er und 2010er, unserer reichweite aus einem sehr begrenzten umkreis rekrutierten.
irgendwann (vor 10 jahren) wurden mal ein paar erfolgreiche youtuber auf die republica eingeladen. als die ihre zuschauer- und abonnentenzahlen nannten, fiel den meisten bloggern, mindestens mir, die kinnlade runter. trotz der beeindruckenden zahlen der youtuber waren sie trotzdem extreme nischenanbieter. auch die youtuber-blasen waren bei weitem nicht so gross, dass meine eltern einen oder eine von ihnen jemals gesehen hätten oder freunde und bekannte ausserhalb meiner internet-blase die kannten.
was ich sagen will: reichweite ist relativ. und sehr, sehr schwer zu erreichen und noch schwerer zu halten. und monetarisierung ist noch schwerer. elendig viel arbeit.
was ich auch sagen will: ich bin froh dass mir beide themen, reichweite und monetarisierung, mittlerweile (grösstenteils) völlig egal sind. das hat eine sehr entspanende wirkung. andererseits muss ich davon was ich in der öffentlichkeit veranstalte auch nicht leben.
eay hat heute ein zitat von jim nielsen verbloggt:
John Gruber, quoting Walt Disney:
We don’t make movies to make money; we make money to make more movies.
Gruber’s version: don’t make software to make money, make money to make more software.
My version: don’t make websites to make money, make money to make more websites.
das ist genau mein derzeitiger arbeitsmodus im netz: das was ich hier veranstalte tue ich nicht um geld zu verdienen, sondern ich verdiene geld, damit ich das hier machen kann. der grund warum ich anfing öffentlich zu schreiben, zuerst in einen newsletter, dann unter meiner eigenen domain wirres.net, war mein bedürfnis zu schreiben. ein bedürfnis etwas zu tun, was sich kreativ anfühlt und mich zwingt um und in mich zu schauen — und das was ich sah in worte zu fassen.
und das mache ich seitdem. reichweiten und monetarisierungsfragen haben mich auf dieser reise gelegentlich neugierig gemacht und ich habe damit viel experimentiert, aber die eigentliche monetarisierung kam immer aus der lohnarbeit.
ich bin darüber nicht traurig, im gegenteil, aber trotzdem ist es doch traurig, dass kreative arbeit mit kreativer arbeit allein so schwer finanzierbar ist. ich glaube auch nicht dass es dafür techische lösungen gibt. die gibt und gab es schon länger, steady, patreon oder youtube — und früher mal flattr. aber bis auf ganz wenige ausnahmen, können da die wenigsten von leben.
vor zwanzig oder dreissig jahren hatten wir mal die hoffnung, dass das netz die gatekeeper davonschwemmt und aufmerksamkeit demokratischer oder gerechter verteilt werden könnte. oder dass die 15 minuten fame die uns andy warhol in den 60ern versprochen hat, sich durchs netz und neue technologien vervielfachen liessen. stattdessen kamen neue gatekeeper und die konkurenz um die ware aufmerksamkeit wird immer schärfer.
ich liebe weiterhin aufmerksamkeit, aber um sie ersthaft zu verfolgen bin ich wahrscheinlich einfach zu müde und zu alt. mir gefällt, dass ich diesen text hier einfach rausrotzen kann und ihn erst später, lange nach dem drücken des veröffentlichen-knopfs, nochmal gegenlese und die gröbsten orthographischen schnitzer rauskorrigiere.
The only secret of magic is that I'm willing to work harder on it than you think it's worth.
-- Penn Jillette
dieses zitat flog mir eben in den kopf und ich musste erstmal eine quelle finden, um den wortlaut wieder zusammenzubekommen. das zitat erklärt gut wie zauberei, illusionen, aber auch ganz allgemein, jede kreative arbeit funktioniert. genau genommen gilt das für jede arbeit und alles was wir gut können. wenn jemand etwas gut kann, dann hat diese person irgendwann mal dafür geübt — und mit ziemlicher wahrscheinlichkeit mehr, als man als aussenstehender für nötig oder möglich hält.
mir fällt in dem zusammenhang auch immer die (wahrscheinlich ausgedachte) anekdote ein, die pablo picasso zugeschrieben wird. der sass in einem café und zeichnete auf einer serviette. als eine frau ihn fragte ob er sie auf der serviette porträtieren würde, war er in zwei minuten fertig und verlangte eine astronomische summe für das porträt. auf den einwand, dass er doch nur ein paar minuten dafür gebraucht habe, sagte er: „es hat mich mein ganzes leben gekostet, das in zwei minuten zu zeichnen.“
ich finde bei allem was ich tue perfektion überflüssig. ich will nicht sagen, dass ich perfektion hasse, im gegenteil, perfektion fasziniert mich. aber mir ist das zu viel arbeit. das hält mich aber nicht davon ab, regelmässig sehr viel arbeit in „gut genug“ zu stecken. oft wahrscheinlich deutlich mehr, als andere für vernünftig halten würden.

das poster habe ich vor 20 jahren bei eboy gekauft (archive-link). seitdem, also die letzten 20 jahre, lag es zusammengerollt in einer unserer kammern. bei der letzten aufräumaktion hat die beifahrerin das poster gefunden und wir haben es aufgehängt.
das poster in in vierfacher hinsicht super: ich mag wimmelbilder, isometrische darstellung und pixel-ästhetik. und dazu ist es noch eine art hiostorisches dokument und zeigt allerhand gedöns, das es nicht mehr gibt (skype, technorati, del.ici.us, feedburner). das poster ist so alt, dass damals facebook und twitter noch kein ding waren.
nachtrag 13.05.2026:
frank westphal hat das poster 2006 verbloggt und sich die mühe gemacht ein paar der web2.0-dienste zu verlinken. den html-block kopiere ich mal, weil er vortrefflich illustriert, wie viel web2.0 den exit gemacht hat.
warum heißt es eigentlich maniküre und pediküre, aber nicht kapilliküre?

das war wirklich einfach: schinken, spargel, zwiebelringe, feta und ein paar tomaten im airfryer stapeln, 14 minuten bei 180°C backen, fertig. zum servieren etwas salz, sehr lecker.
nachtrag: vergessen: 4 eier waren auch noch draufgestapelt (ohne schale)
stephen colbert hat nur noch ein paar wochen, bevor seine late-night-sendung eingestampft wird. ich fand seine late-night-sendung immer ganz okay, aber ein fan war ich nie. gelegentlich stolperte ich auf youtube über sendungsausschnitte, und gelegentlich war das eben okay. während ich von letterman und ferguson nie genug bekommen konnte, reichten mir die schnipsel von colbert. bei kimmel finde ich das ganz ähnlich, haut mich meistens nicht von den socken.
im letzten halben jahr war ich allgemein zunehmend genervt von der verwurstung und länglichen aufbereitung von trumps schwachsinn. ich finde es natürlich grandios, dass trump so dünnhäutig ist, dass er von witzen über ihn genervt ist und sich nicht zu schade ist, mit seinen kleinen händen zurückzuboxen und seine speichelleckenden untergebenen auf colbert, kimmel und sonstwen, der oder die es wagt, sich über ihn lustig zu machen, zu hetzen. ich habe keine lust mehr, donald trump überhaupt noch aufmerksamkeit zu schenken.
ich habe ein bisschen das gefühl, dass aufmerksamkeit für donald trump das ist, was zeit für die grauen männer in momo ist. in michael endes erzählung können die grauen männer den menschen die zeit stehlen, indem sie die menschen davon überzeugen, zeit sparen zu müssen. wie die grauen männer mit der zeit macht donald trump mit der aufmerksamkeit, die er uns stiehlt, nichts besonderes oder sinnvolles — ausser im rampenlicht zu existieren und anderen menschen die laune oder die existenzgrundlage zu zerstören.
um bei dem bild zu bleiben: die zeit, die wir durchs sparen an die grauen männer verlieren, hält uns, genau wie die aufmerksamkeit, die wir donald trump schenken, davon ab, die zeit etwas sinnvollem zu widmen und unsere aufmerksamkeit auf etwas konstruktives, schönes, sinnstiftendes zu lenken.
jedenfalls fand ich es sehr wohltuend, stephen colbert dabei zuzusehen, wie er barack obama interviewt und sich von ihm durch obamas noch zu eröffnende presidential library center führen lässt. ex-präsidenten werden mit abstand zum amt ja ohnehin immer sympathischer, aber obama ist so sympathisch, dass ich ihn knuddeln möchte. und stephen colbert ist teilweise wirklich witzig, so witzig, dass ich ein paarmal laut lachen musste. und auf gewisse weise ist das was obama sagt auch erbaulich, optimistisch stimmend und eben nicht vollgesogen mit der endzeit- und angstinduzierenden rhetorik der populisten-faschisten, die uns seit jahren zunehmend auf allen wahrnehmungskanälen überschwemmt. deshalb: colbert bei obama fand ich sehenswert.


die republica-app für dieses jahr ist draussen. das freut mich, weil ich dann jetzt mein #rp26-program mit der ♥️ funktion zusammenklicken kann (und die tage hier veröffentlichen kann).
noch mehr würde ich mich natürlich freuen, wenn ganz viele meinen vortrag im programm der app suchen („felix schwenzel“) und finden und mit einem ♥️ markieren würden. ich glaube, in aller bescheidenheit, dass mein vortrag dieses jahr ganz gut sein könnte. und dieses jahr isser auch nicht am letzten republica-tag, weil er schon fast fertig ist und ich die drei republica-tage nicht zum fertigschreiben brauche.

nachtrag: offenbar kann man in diesem jahr einzelne sessions oder ein zusammengestelltes #rp26 programm in die app importieren.
mit diesem link oder QR code sollte meine session zum markieren in die app importiert werden können.
https://re-publica.com/app-import?s=10417
mmen vorträge für die republica schreiben ist nicht das allergrösste vergnügen. aber alle paar jahre entscheide ich mich dazu, mich in die lage zu bringen 30 minuten einigermassen nachvollziehbaren text zu versprechen und dann auch tatsächlich im mai abzuliefern.
die idee dahinter ist immer die gleiche. ich formuliere eine steile these zu einem thema das mich fasziniert, interessiert oder beschäftigt und versuche dann einen text zu erarbeiten, der die erwartungen erfüllt. dieses jahr war die these besonders steil (die welt ist scheisse — und das ist auch gut so) und auch wenn ich bei der einreichung eine idee hatte, in welche richtung das ganze gehen sollte, erfordert das schreiben dann doch noch ziemlich viel denk-akrobatik.
mir fällt das schreiben und öffentliche reden gar nicht mal so leicht. hier im blog kann ich texte hemmungslos veröffentlichen, auch wenn sie nicht wirklich zuende gedacht sind oder noch sehr ungeschliffen sind. „hingerotzt“ nennen andere das gelegentlich und so sind die texte hier auch meistens eher fragmente, einzelteile für weitere denkprozese und zum weiterdenken, die ich später nbochmal aufgreife oder auch nicht.
so ein vortrag, eine präsentation vor publikum auf der republica sollte aber, zumindest im ansatz, in sich geschlossen sein. das rotzige, teils ungeschliffene ist oft weiter ein bestandteil, aber es muss auch etwas substanz rein, damit er bestehen kann.
andererseits bilde ich mir ein, relativ git einschätzen zu können, was ich publikum der republica zumuten kann und was nicht. und natürlich ist das republica publikum sehr offen und positiv. ich habe jedenfalls immer das gefühl, dass ich mit dem publikum eine gemeinsame wellenlänge finden kann und mir witze und andeutungen erlauben kann, die mir jedes andere publikum um die ohren schlagen würde.
trotzdem: es steckt viel arbeit in diesen prösentationen und der grund warum ich die mir alle paar jahre zumute ist der gleiche warum ich ins internet schreibe: selbstgestellte aufgaben zu lösen, den mund etwas voll nehmen und dann trotzdem was liefern können, einen auf den ersten blick unüberwindbaren berg zu ersteigen ist befriedigend. einfache aufgaben (spülmaschine reparieren, brot backen) zu erledigen ist befriedigend, aber an schwierige aufgaben (hund erziehen, öffentlich sprechen) nicht zu scheitern ist befriedigender.
der ablauf so einen vortrag zu schreiben ist meisten auch ziemlich ähnlich. ich pumpe mich wochenlang mit informationen zum thema voll, bzw. suche und finde an allen möglichen ecken des internet und in büchern (die ja auch internet sind) bezüge zu meinem thema die ich mich in seitenlangen kladden notiere. danach versuche ich das alles zu einem einigermassen kohärenten text zusammenzufassen, den ich im prinzip auch so ins internet stellen könnte. während des ganzen prozesses baue ich bereits folien die mir unterwegs einfielen, von denen ich danch mindestens die hälfte wegschmeisse. die präsenentation baue ich dann in keynote, den text aufgeteilt in den moderatoren notizen und dazu dann hiunderte folien.
den text habe ich seit gestern fertig. er muss noch geschliffen und an vielen stellen gekittet und ergänzt oder gestutzt werden, aber in ein zwei tagen könnte ich den im prinzip hier veröffentlichen.
und ich frage mich gerade ob das ein gute idee ist. so wirklich dagegen spricht eigentlich meine vortragslektorin, der ich den vortrag immr mindestens einmal vor der republica vorspiele, schaut sich auch meist noch gerne den vortrag nochmal live an. den text vorher zu veröffentlichen, sollte also niemanden davon abhalten den vortrag trotzdem noch zu sehen. andererseits habe ich dieses mal ja eine eher abseitige bühne mit offiziell 20 plätzen zugewiesen bekommen.
trotzdem weiss ich nicht ob es eine gute idee ist den text vorher zu veröffentlichen. vielleicht tut leserfeedback dem text ja noch gut? oder spoilt das die ganze geschichte?
nachtrag 08.05.2026:
ich habe eine umfrage auf mastodon gemacht, bei der ich nach ein paar stunden ausversehen 15 stimmen gelöscht habe, die stimmen danach tendierten am ende eher zu einer vorab-veröffentlichung („würd ich lesen“). heiko hingegen hat mir zwei webmentions kommentare gesendet (einen hab ich mittlerweiel gelöscht), die sich schon fast flehend anhörten: „Nicht vorher veröffentlichen“
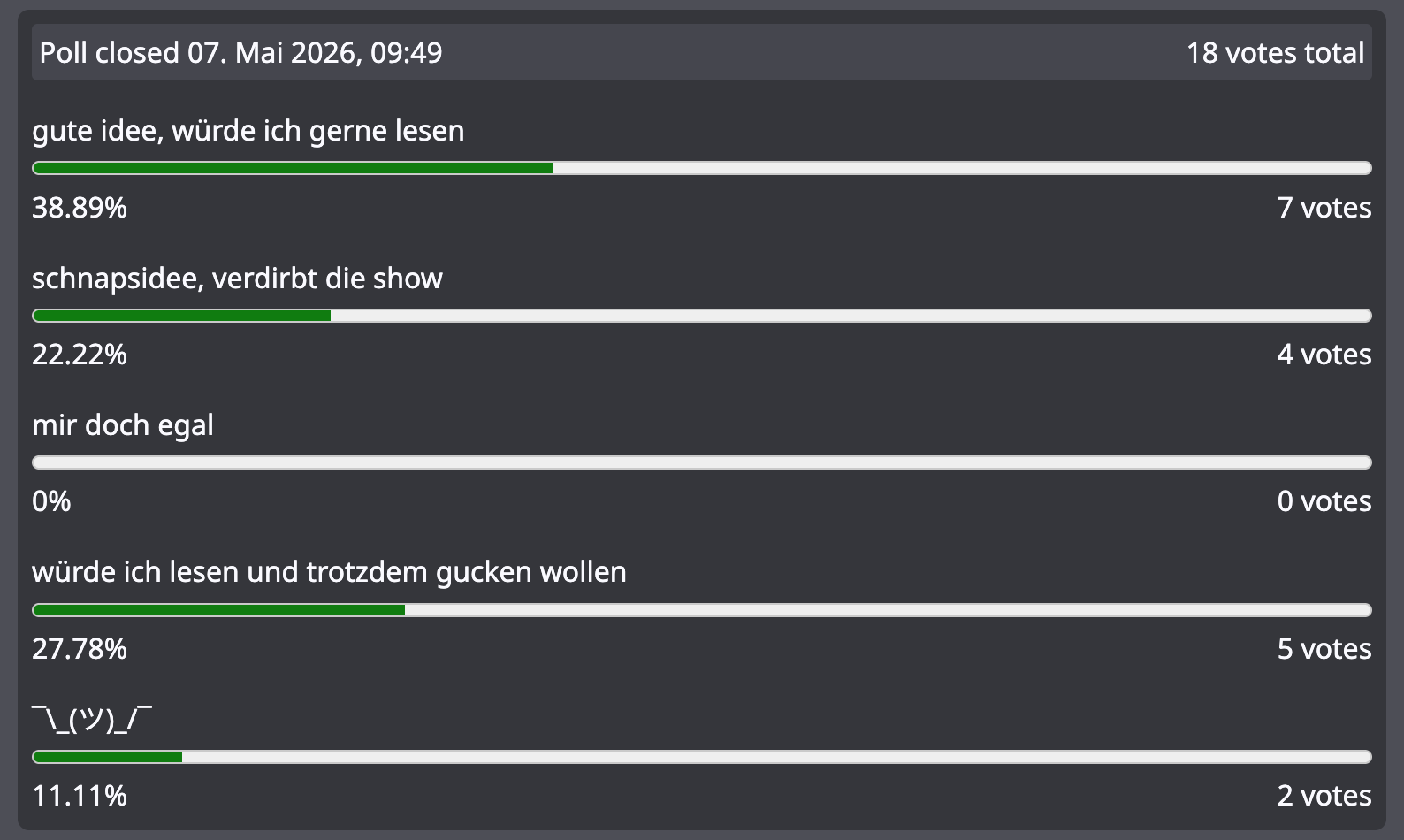
ich warte jetzt erstmal ab, was meine lektorin sagt, wenn ich ihr das am wochenende vorspiele.
nachtrag 11.05.2026:
fazit nach einer kurzen session mit der lektorin (@dasnuf): text ist noch nicht fertig.
und sie hätte mir gerne 5 minuten länger zugehört. ich brauche noch ein paar tage bis ich meine hausaufgaben erledigt habe.
jeder kennt scheinriesen: ein riese, der immer kleiner wird, je näher man ihm kommt.
für meine #rp26-präsentation habe ich mir eine variation von michael endes wunderbarem bild ausgedacht: scheinglück
wenn man dem glück hinterherrennt, desto grösser wird der frust, den man eigentlich zurücklassen möchte. gilt auch für alle anderen probleme, vor denen man weglaufen möchte.
meine präsentation, mein plädoyer für optimismus („die welt ist scheisse — und das ist auch gut so“), findet am zweiten #rp26-tag statt, am 19.05.2026 von 13:00 bis 13:30 uhr. meine „bühne“ ist das sogenannte energiemobil, 55" screen und mikrofon und platz für 20 zuschauer ist laut speaker-briefing vorhanden.
ich freue mich über jeden der kommt und noch mehr darüber, dass ich schon 35% des texts fertig habe. der rest ist auch fertig, den muss ich nur noch aufschreiben.
noch 14 tage bis zur #rp26.
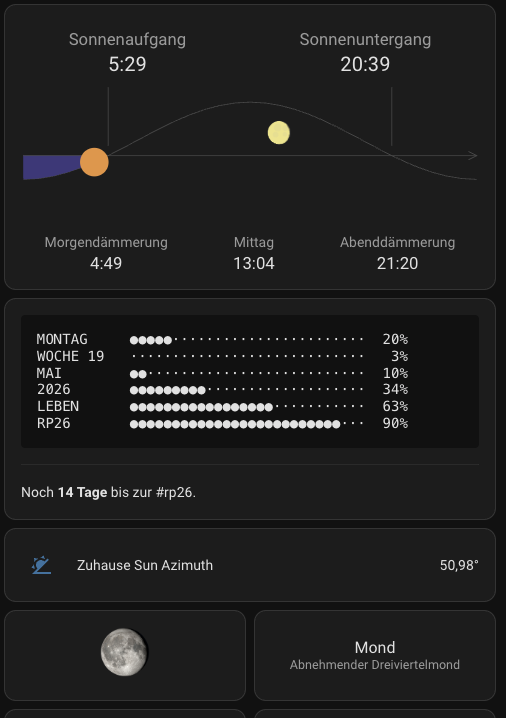
in meinem home assistant dashboard lasse ich mir den sonnen- und mondstand anzeigen. der sonnenstand ist praktisch, weil ich dann weiss, ob wann morgens die sonne aufgeht. weil es mich erfreut, hatte ich dort auch immer ein schematisches bild des mond, wie er im moment in berlin aussieht. timeanddate.com generiert dieses bild für jeden ort der erde.
das bild hat sich home assistanz dort immer gescraped. seit einer weile verhindert cloudflare für timeanddate.com jetzt das scraping. fair enough. also fragte ich cursor, ob es mir das bild mit einem script berechnen könne. es meinte zwar, dass es das könne, aber wie so oft, konnte es das nicht, auch nach sechs schrillionen tokens und mehreren iterationen kam nicht mehr als ein hitlerbild raus.
j sei dank hatte sich schon jemand anders die mühe gemacht: mit den tools in diesem repo lassen sich aus nasa-bildern und ein paar python-scripten akurate bilder des mond generieren, je nach ort und zeit.
das bringt so gut wie gar nichts, ausser dass es mir grosse freude bereitet.

Das ist der eigentlich gefährliche Punkt: Menschen haben schon immer Unsinn gedacht. Das gehört einfach dazu. Aber digitale Plattformen haben aus fast jeder Abweichung, jeder Kränkung, jeder Wut und jeder Verschwörungsfantasie sofort einen scheinbaren sozialen Raum gebaut.
das ist ein sehr schön differenzierter und nachdenklicher text von florian heinz über räume. räume im netz, in kneipen, im digitalen und im analogen. aber ich würde gerne etwas undifferenziert, bzw. kurz angebunden widersprechen.
die räume, in denen wir menschen interagieren, sind alle synthetisch, also von uns menschen konstruiert und mit regeln versehen. digitale räume sind lediglich eine weitere ausprägung.
manche räume haben eine jahrtausendealte geschichte hinter sich, und alle unterliegen einem steten wandel. ich war immer fasziniert von der idee der kaffeehäuser, orte, an denen sich kluge menschen treffen, diskutieren, ideen entwickeln und streiten. aber gibt’s das noch? starbucks und andere kaffeehausketten leben zum teil von dieser nostalgie, aber ich würde sagen: so wie sich die digitalen räume ständig wandeln, wandeln sich auch die analogen räume, die gastronomischen, politischen, kulturellen orte.
ich sehe das problem eher darin, dass wir die digitalen räume noch nicht sozialisiert haben, noch nicht die richtigen regeln, den richtigen umgang damit gelernt haben. in meiner jugend hatten wir ein gutes gefühl dafür, welche öffentlichen orte wir lieber meiden und in welche wir passen. ganz platt gesagt: nazi-kneipen gab’s auch schon vor dem internet. agitieren, radikalisieren, verschwörungstheoretisieren geht, das zeigt die geschichte, auch ganz gut mit analogen mitteln.
und, nur so ein gedanke: virtuelle soziale räume gab’s auch schon lange vor dem internet. die virtuellen, gedachten räume, die gesprochene oder geschriebene erzählungen öffnen, unterscheiden sich meiner meinung nach nicht substanziell von den neuen digitalen räumen, die sich in den letzten 20–30 jahren geöffnet haben. es gab immer wieder katalysatoren, turbolader, die die alten regeln über den haufen warfen und für aufregung, umbrüche und teils radikale veränderung sorgten. die erfindung des buchdrucks oder kürzlich des internets und jetzt unsere fähigkeit, künstliche neuronale netze mit vorher gedachtem, gemachtem oder aufgeschriebenem zu füttern — all diese umbrüche erforderten und erfordern anpassungen von gesellschaftlichen normen und regeln, um negative effekte abzuschwächen.
ja, ich sehe auch, dass aus digitalen räumen viel toxisches, übelriechendes kommt und dass die brutstätten der demokratiefeindlichkeit und ausländerfeindlichkeit sich zum großen teil in digitale räume verlagert haben. aber das muss nicht unbedingt an den strukturellen gegebenheiten der räume liegen, sondern in erster linie daran, dass wir als gesellschaft den umgang mit diesen räumen noch nicht gelernt haben. oder dass die radikalen schneller lernen, anpassungsfähiger, flexibler sind als die moderaten.
trotzdem: man kann nicht zu viel darüber nachdenken oder diskutieren, wie unsere sozialen räume funktionieren oder funktionieren sollten.
das t-shirt hatte potenzial

t-shirt mit der aufschrift „i had potential“, aber man kann von der aufschrift nix erkennen

gestern abend, kurz bevor ich ins bett gehen wollte, sah ich hohe CPU last auf dem server auf dem wirres.net läuft. normalerweise (re-) aktivere ich dann kurz cloudflare (was ich normalerweise deaktiviert habe) und die unhöflichen AI-crawler, die meine meine seite mit anfragen beschiessen, verschwinden dann relativ schnell. gestern schien das aktivierte cloudflare nicht viel auszurichten. die last blieb hoch. erst als ich das caching und die AI-crawler-abwehr auf sehr aggressiv umstellte, ging die last runter.
das heisst wohl zweierlei: die crawler scheinen etwas geschickter darin zu werden, sich als legitime besucher auszugeben, sind aber weiterhin viel zu aggressiv oder nachlässig programmiert. ich hab ja nichts dagegen, wenn die meine seiten indexiert werden. von suchmaschinen, AI-crawlern oder mechanischen türken. aber ich würde mir schon wünschen, dass sie sich an die regeln halten oder zumindest höflich bleiben. ich habe vor allem keine lust, die ganze zeit die cloudflare schutzwälle hochgezogen zu lassen oder AI-labyrinthe aufzustellen.
jedenfalls stolperte ich gestern abend bei meinem kontrollgängen über meine website über diesen fast 20 jahre alten beitrag: ich nenne es lesen
der beitrag erinnerte mich daran, dass „wir nennen es arbeit“ jetzt schon 20 jahre alt ist, dass ich seit 2006 einen youtube-kanal mit 63 abonnenten habe und einmal ein video veröffentlicht habe, das > 100k views eingesammelt hat.
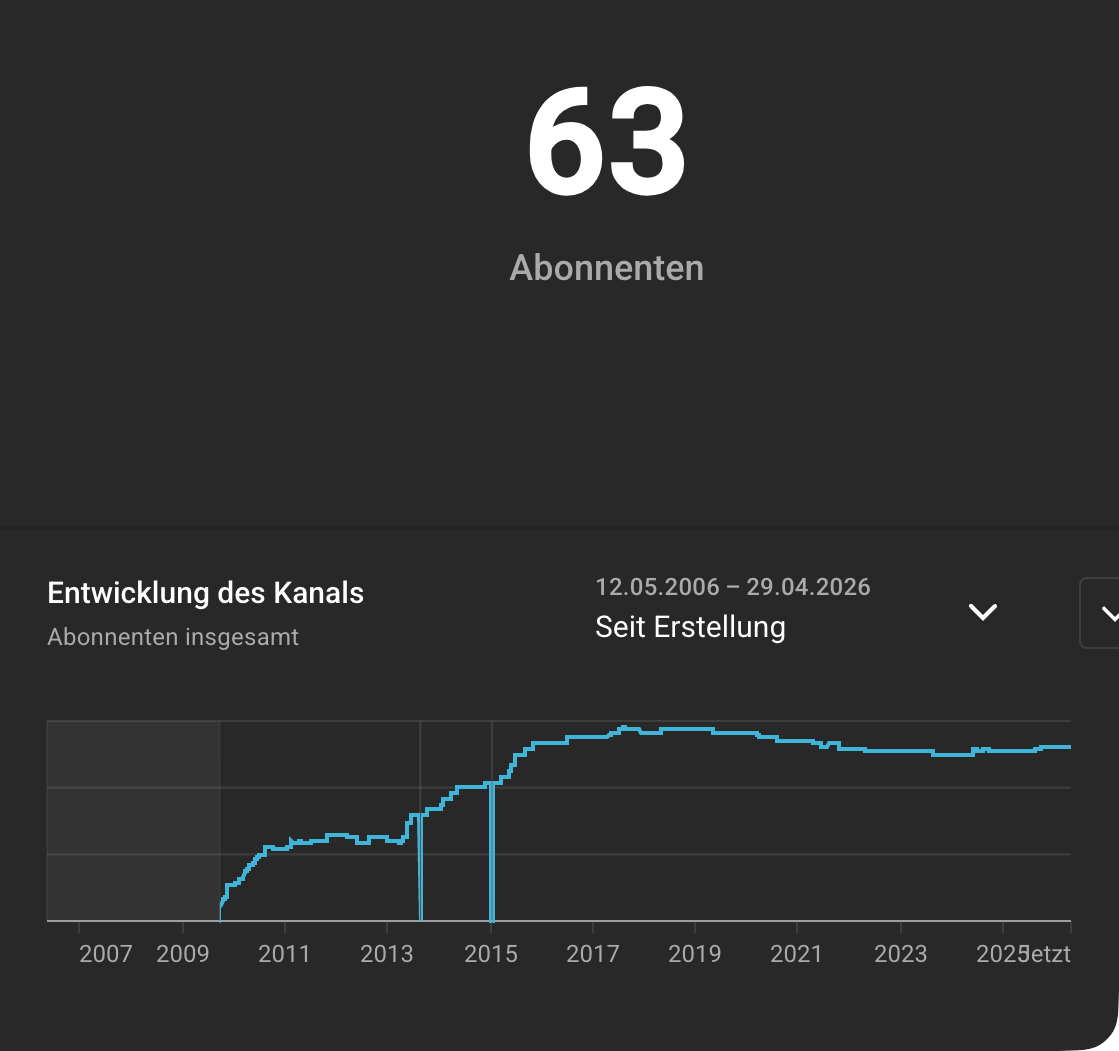
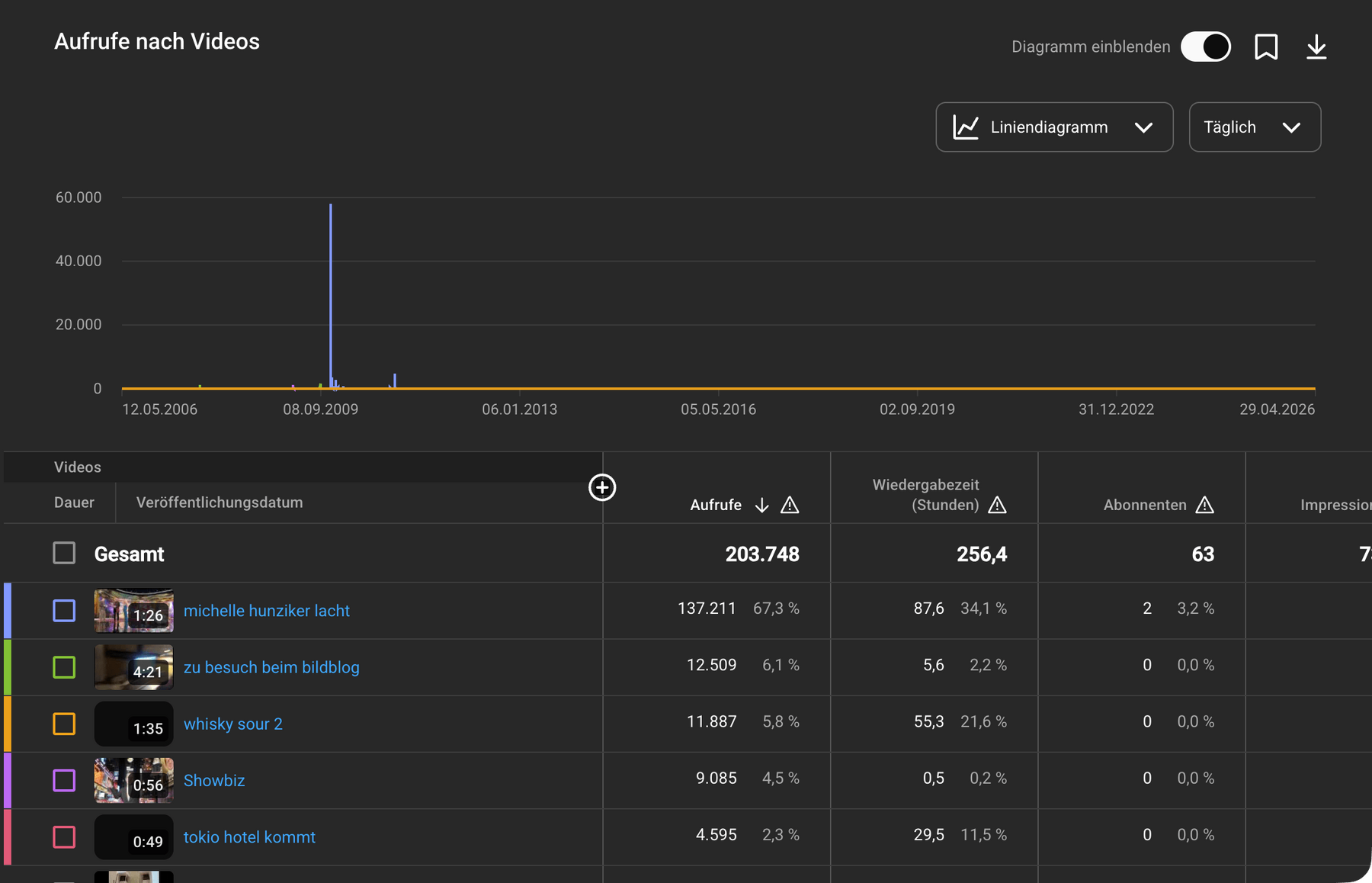
und weil alex matzkeit mir, der kaltmamsel und franzi auf der republica die frage „wie war es damals wirklich?“ stellen wird, fiel mir die offensichtliche antwort wieder ein: damals war es genauso wie heute. ausser dass wir etwas jünger waren. es gab etwas weniger crawler und das hosting war eine spur einfacher, aber es gab und gibt genau so viel oder wenig interesse von echten menschen an in text-, audio- oder videoform geloggten inhalten wie heute.
google fand blogs damals total gut und schickte gelegentlich besucher vorbei, die dann irritiert wieder abzogen. heute schickt google nur noch leute vorbei, die sich für rezepte interessieren.
was geblieben ist: bloggen ist weiterhin ein randphänomen. und das ist auch nicht weiter schlimm. im gegenteil.

Noch eine kleine Erkenntnis nebenbei: Man kann, wenn man an Krücken läuft, beim Gehen gar nicht aufs Handy sehen und dadurch erneut stürzen. Wie klug ist das denn eingerichtet? Und sollte man also einfach zur Prophylaxe an Krücken gehen?




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
extrem faszinierend, die welt der polymorphe und kristalle. sehr gut und anschaulich erklärt.
und: schokolade ist auch ein polymorph und ich hab jetzt endlich die wissenschaft hinter temperierter schokolade verstanden. kristallklare sehpfehlung.