wegen des neuen kommentarsystems habe ich gedacht, ich müsse nochmal meine datenschutzerklärung ansehen und gegebenenfalls ergänzen. statt mir halbwissen zusammenzugooglen habe ich die hilfe von chatgpt und gemnini in anspruch genommen um mit deren halbwissen die anmerkungen zum datenschutz ein bisschen umzuformulieren, zu kürzen und vor allem verständlicher zu machen. ich finde das ist ganz gut gelungen. danach habe ich cursor die erklärung nochmal auditieren lassen und noch ein paar ganz gute hinweise erhalten.
isso setzt beim kommentieren tatsächlich einen cookie. der authentifiziert die kommentierenden 15 minuten lang gegen die isso-API, damit die ihren kommentar editieren oder löschen können. pfiffig und für sowas — nicht zum tracken — sind die dinger ja auch mal erfunden worden.
ausserdem daran erinnert worden, dass ich tatsächlich an einer stelle die komplette IP-adresse von besuchenden verarbeite: für den shitvote nutze ich tatsächlich die ungekürzte IP adresse der besuchenden um einen hash zu errechnen und doppel-shit-votes (in ansätzen) zu verhindern. sonst sind die IPv4 adressen überall um zwei oktette gekürzt und die IPv6 adressen auf ein /48-präfix gekürzt.
ich benutzte meinen homepod eigentlich nur für zwei dinge und alleine wegen dieser beiden dinge mag ich meinen homepod sehr, sehr gerne. bis heute.
die eine sache für die ich die siri im homepod gerne nutze ist zu fragen: „wie spät?“ die andere sache ginge wahrscheinlich auch mit jedem anderen der 5 vernetzten lautsprecher bei mir im zimmer, aber ich lasse es den homepod machen: bei einem formel-eins-rennen, fünf minuten vor start ein formel-eins-wrooooom-geräusch abspielen.
seit heute fängt siri selbständig an musik abzuspielen. leise, aber immer wieder. da sich homepods nicht wirklich debuggen oder befragen lassen was sie zur jeweiligen aktion gebracht hat, steh eich völlig auf dem schlauch. ich habe zwischenzeitlich alles abgeschaltet was ich in verdacht hatte, mein iphone, home assistant, mein laptop bluetooth, die klimaanlage — nichts hilft.
aber zum automatisieren habe ich ja home assistant. eine kleine automation schaltet die musik jetzt aus, sobald die musik startet.
das funktioniert, auch wenns keine lösung ist. wenn ich in den nächsten tagen nicht rausbekomme was oder wer das verursacht, muss der homepod temporär sterben (stromlos werden). immerhin habe ich ausgeschlossen, dass der homepod das rauschen der klimaanlage als sprachbefehle interpretiert.
apropos formel 1, das guck ich ja gelegentlich gerne und fahre dafür gerne mit einem virtuellen privaten netzwerk nach östereeich. das rennen heute in östereich konnte zwar nicht viel mehr als dreissig prozent meiner aufmerksamkeit binden, war aber trotzdem ganz spannend. aber wirklich toll waren die drohnenaufnahmen, nicht mit der üblichen drohnen-vogelperspektive, sondern eine drohne, die den autos mit bis zu 300 km/h im tiefflug hinterherflog. keine ahnung was man machen muss um für sowas bei einer veranstaltung mit publikum eine genehmigung zu bekommen, aber östereich hatte ja noch kein rammstein. die bilder waren aber tatsächlich beeindruckend.
beim spiegel habe ich das schon öfter gesehen: endmarken. wenn ein spiegel-artikel zuende ist, klascht der spiegel ein logo-„S“ an den letzten absatz.
das kann ich auch, dachte ich mir und klatsche jetzt einen haufen scheisse, meinen shit-vote, bzw. „ich mag diesen scheiss!“-button an den letzten absatz — oder je nachdem, wenn ein beitrag nicht mit einem absatz endet, auch dadrunter.
ausserdem habe ich den artikel-fuss („footer“), die kommentar-sektion und die beilage ein bisschen neu geordnet, in der hoffnung dass damit auch menschen die nicht ich sind die funktion und den sinn (ein bisschen) begreifen. wenn nicht, ist auch nicht so schlimm, solange meine texte (ein bisschen) verständlich sind.
auch witzig (für mich) meine mutter, die jetzt ja ein welterste und -einzige wirres.net-beiträge per email bekommt, meinte sie hätte die letzten artikel nicht gelesen. dass habe ich ehrlichgesagt auch nicht anders erwartet, dass mein reigen an technischen deep-dives ins ATprotokoll, avtivitypub, bubbles und meine maschinenraum-geschichten an einem teil des publikums vorbeigehen und dass dieses publikum genau das tut, weiterblättern („scrollen“). das ist das schöne am internet: man kann den massengeschmack ignorieren und ganz viele nischeninteressen („long tail“) bedienen und das gezielte ignorieren funktioniert.
apropos home assistant und automatisierungen: phasenweise habe ich mich damit genauso manisch beschäftigt, wie ich mich derzeit manisch mit dieser website beschäftige. aber home assistant ist so freundlich, dass es auch ohne meine aufmerksamkeit monatelang zuverlässig funktioniert. selbst gelegentlich leerlaufende batterien bringen das system und die sensorik nicht zum erliegen, auch weil ich vieles redundant aufgesetzt habe. trotzdem habe ich der automatischen wohnung heute nochmal etwas aufmerksamkeit geschenkt, updates eingespielt, kaputtaktualisiertes („breaking changes“) gefixt, batterien getauscht und über-optimistische-sensor-wert-validierungen, bzw. glättung. als ich die aufgesetzt habe, konnte ich mir nicht vorstellen, dass am hoffenster temperaturen > 27°C auftreten (das ist immer im schatten). pustekuchen, in den letzten tagenm gings öfter drüber. deshalb hat meine sensor historie jetzt abgeflachte kurven und durch die filter-anpassung ein paar falschmessungen/ausreisser nach unten.
the agency staffel 2 hat mich in den ersten paar folgen mit 4 parallelen handlungssträngen total überfordert. aber mit jeder folge verstehe und finde ichs besser. die abgefucktheit von geheimdienstarbeit bringt die serie wirklich gut rüber, vor allem im gegenteil zu den 2000 anderen filmen und serien die geheimdienstarbeit gerne ästhetisieren, ridikülisieren oder glorifizieren. das macht the agency zwar auch, sonst wäre es ja nicht eine fiktionale unterhaltungssendung, sondern eine „true political crime“-serie auf netflix.
das klimaanlagen-/wärmepumpen-rabbithole, in das markus kürzlich gefallen ist, habe ich gerade noch vermieden. die beifahrerin hat vor ein paar jahren eine mobile, kleine klimaanlage für ihr atelier gekauft, die jetzt in meinem zimmer steht und es auf erträgliche 24,5°C kühlt. sie hat jetzt zwar auch interesse an einem weiteren gerät angemeldet, weil die temperaturen in ihrem zimmer jetzt auch auf über 25°C klettern. und meine eltern wollen auch eine. und da soll ich dann sowohl beraten als auch montieren. aber das konnte ich alles gut in den winter schieben weil man jetzt ohnehin nichts derartiges kaufen kann.
ich staune, wie viele menschen bei google nach „wassermelonensalat ottolenghi“ suchen. google verrät mir, dass dieser suchbegriff zwischen dem 18.06 und 24.06 fast 600 mal dazu geführt hat, dass meine rezeptseite dazu bei google angezeigt wurde. google hat deshalb in den letzten tagen pro tag ungefähr 60 menschen hierher geschickt. das fühlt sich beinahe an, wie früher, als google der grösste fan von blogs war. jetzt liebt google, die alte opportunistin, offenbar nur noch rezepte.
als ich die tage darüber nachdachte ob und was mir diese menschen bringen, die von google hierhergespült werden, stand ich auf dem schlauch. immerhin produzieren sie eine metrik und heben zwei meiner rezepte auf der rückseite unter „meistbesuchte seiten“ nach oben. ich habe überlegt ob ich eine einfach zugängliche (rezept) bewertungsfunktion mit ⭐⭐⭐⭐⭐ anbieten soll, weil ja niemand versteht, was das 💩 soll. dann dachte ich, vielleicht eine einfach zugängliche kommentarfunktion und habe mir nochmal isso angeschaut. das hatte ich mir zuletzt vor einem jahrzehnt angeschaut als haloscan eingestellt wurde. aus unerfindlichen gründen hatte ich mich damals dann für disqus entschieden, deren javascript ich (optional) unter meine artikel klebte.
jedenfalls war ich überrascht wie unkompliziert sich isso anfühlt. keine anmeldung und nach dem absenden des kommentars bleibt der sogar noch editierbar oder löschbar. kommentare lassen sich mit markdown formatieren und das ganz lässt sich auch noch leicht mit docker installieren. also erstmal isso unter die zwei rezepte geklebt, die gerade so viel besuch bekommen.
dann habe ich gedacht, wenn selbst menschen mit jahrzenhnten interneterfahrung von meinem jetztigen kommentarsystem überfordert sind und mich teilweise per mail um bedienungstipps fragen, kann ich ja auch mal einen regulären beitrag kommentierbar machen und schauen was passiert.
dieser beitrag ist also kommentierbar. name, email oder website sind optional, lediglich javascript ist voraussetzung. moeration ist erstmal deaktiviert. was hälst du von (isso-) kommentaren unter beiträgen auf wirres.net?
nachtrag 20:00 uhr: ich habe die kommentare aus maurice komments plugin in isso importiert und erstmal die kommentarfuntion komplett auf isso umgeschaltet. isso-kommentare werden jetzt überall unter dem beitrag angezeigt, ausser man klappt die kommentare zu.
webmentions, kommentare auf mastodon oder bluesky erden erstmal weiterhin in der beilag angezeigt, aber ich hab pläne und idee das in zukunft zu verbessern und technisch eleganter zu machen.
gelegentlich mache ich sachen nur weils geht. manchmal ergeben sich dann zufällig andere, gute sachen daraus.
vor zwei wochen hatte ich die idee, dass ich beiträge ja auch als markdown ausliefern könnte. seitdem kann man im browser einfach an eine beitrags-adresse ein .md hängen und der artikel wird als text/markdown geladen:
dann las ich zufällig über standard.site und ATproto und sah, dass ich den markdown-text einfach mit ein paar metadaten in mein PDS schreiben kann und das markdown dann zu einem ordentlich aussehenden html-beitrag gerendert wird, zum beispiel hier:
weil ich die markdown-version der beiträge auch im quelltext ankündige, mit …
<link rel="alternate" type="text/markdown" title="markdown-gedöns — weils geht (Markdown)" href="https://wirres.net/articles/markdown-gedons-weils-geht.md">
… finden crawler und bots die markdown-version automatisch — wenn sie wollen — und nehmen das angebot auch dankend an, wie ich in meinen logs sehe (derzeit ca. 600 markdown-dateien-crawls pro tag).
von mir aus können sich crawler und bots hier austoben, solange sie sich benehmen, höflich bleiben und sich an die robots.txt regeln halten. eine regel mit der ich mir einbilde in den letzten jahren gut gefahren zu sein: inhalte die jünger als fünf jahre sind dürfen die crawler indexieren, was älter ist nur wenn ich es explizit zur indexierung freigegeben habe. ich weiss dass es nicht wenige arschloch-bots gibt, die sich nicht an die regeln halten, und das ich dagegen (momentan) wenig ausrichten kann. was ich aber nicht mache: markdown für bots gesperrte inhalte auszuspielen.
effektiv stehen hier also ca. 953 beiträge zur indexierung bereit. das stimmt natürlich nicht ganz, in echt sind es 3483 beiträge die laut
zur indexierung freigegeben sind. aber das sind vor allem „sofortbilder“ (mein instagram archiv, 2376 beiträge), checkins (151) und statische seiten. eine liste dieser 953 beiträge, die auch indexiert werden dürfen und keine checkins oder sofortbilder sind, stehen jetzt auch in einer übersichtlichen liste zur verfügung:
wirres.net/index (html, klassiches layout, mit link zur html- und markdown-version)
leider können browser heutzutage noch nicht nativ markdown rendern, weshalb der markdown-text eben als plaintext angezeigt wird (ausser man installiert sich zum beispiel diese chrome-extension).
wäre es nicht toll, wenn browser statt nur nach einem html-dokument zu fragen, auch — falls browsende das wünschen — auch nach einem markdown-dokumnet fragen könnten? das wäre dann wie die safari reader funktion, die aus unlesbaren seiten eine vereinfachte, gut lesbare version rendert. zum lesen von online-koch-rezepten kann man mittlerweile kaum noch html benutzen, weil die rezpte fast immer in slop-texte eingebettet sind. ich lese rezepte online fast nur noch in mela. markdown rezepte hingegen sind gut lesbar:
jedenfalls, für alle die sich fragen was das alles soll: es ändert sich nichts, ausser dass es jetzt eine schlanke, schnelle übersichtseite aller artikel gibt, die manche vielleicht übersichtlicher oder schöner finden als die klassische startseite mit 21 artikeln im volltext:
und eben ne menge markdown-gedöns, das man getrost ignorieren kann, was ich aber mal ausprobieren wollte, ob es geht. es zeigt sich: ja, es funktioniert eine markdown indexseite mit einem dünnen javascript-wrapper auch jetzt schon ohne browser extension zu rendern. und ja, bots fressen gerne markdown. und ja ich finde das fazzinierend.
und abgesehen davon, spare ich jetzt mit do it yourself einen haufen geld, weil cloudflare das alles was ich mir hier selbst gebaut habe kunden für viel geld verkauft:
Markdown for Agents is available to Pro, Business and Enterprise plans, and SSL for SaaS customers at no cost.
(pro pläne verkauft cloudflare ab ca. 20 €/monat, business geht bei 180 €/monat los und enterprise ab 2000 €/monat. und ja, „content negotiation headers“ für markdown hab ich auch eingebaut.)
nachtrag: ich habe gemini gebeten einen blick in den mascheinenraum zu werfen („wenn du dir die header von wirres.net/articles/markdown-gedons… ansiehst, was siehst du, was fehlt, was ist ungewöhnlich?“). die antwort verstehe ich als kompliment und habe sie in die beilage kopiert.
ich muss leider nochmal an einem teil meines publikums vorbeischreiben. das ATmosphere-rabbithole, in dem ich gerade stecke fasziniert mich gerade zu sehr, um das nicht aufzuschreiben.
man sagt ja: wenn man einen hammer in der hand hat, sieht man überall nägel. ich sehe im moment überall das AT-protokoll und die formate, bzw. lexika die dahinterstecken. mich fragen leute was der vorteil des standard.site-formats gegenüber RSS sei. der vergleich geht ein bisschen an der sache vorbei. die frage ist einfach: was sind die sachen die man mit einem protokoll machen kann, was sind die potenziale?
bereits 2002/2003, noch bevor es wordpress gab, hatte ich auf wirres.net bereits RSS (mit volltexten) eingebaut. weil ich potenzial, anwendungsfälle dafür sah — und weil es anwendungsfälle gab. ich weiss nicht ob ich es damals schon nutzte, aber netnewswire, also einen tollen RSS-reader, gabs seit 2002. 99,99% aller menschen interessierten sich damals nicht für RSS (und blogs), aber die die es nutzten fanden es grossartig, weil es grossartig und praktisch war.
mike masnik erinnert sich an das internet von damals, dass es angeblich nicht mehr gibt und von plattformen und apps zerfressen und zerfasert wurde. allerdings mit dem twist, dass das einerseits nicht stimmt, das alte internet ist noch da, und es keimt unter dem plattform-beton gerade wieder auf.
But, as Godier’s piece notes, protocols are… boring. They change slowly (for a good reason, because you need stability to build on). They tend to change by consensus, which is messy. And rather than having billion dollar companies throwing a whole massive engineering team at making everything work, in the protocol world, we rely on constant experimentation by anyone who wants to experiment.
The open web of the nineties didn’t win because the tools were better. It won because a critical mass of people decided that the alternative, a handful of AOL-style walled gardens choosing what everyone saw, was not the future they wanted. Then they built their way out of it. Slowly, unglamorously, in rooms that looked a lot like this one.
Whether atproto ends up being the thing, or a stepping stone to the thing, I don’t know. Nobody in the room claimed to know. But the work is real, the apps are shipping, and the people building them are taking it seriously without taking themselves seriously. That combination is rare, and historically, it’s the one that wins.
das entscheidende und spannende, damals wie heute, sind nicht die grossen visionen, die massenwirksamen apps und plattformen, sondern die greifbareren, jetzt nutzbaren werkzeuge die genutzt, ernsthaft weiterentwickelt werden und funktionieren. die arbeit im maschinenraum ist real. nicht meine, sondern die von tausenden frickelnden menschen, auf deren schultern man sich stellen kann und ihre werkzeuge mitbenutzen kann.
gestern habe ich eine liste von ein paar apps die auf dem AT-protokoll aufsetzen veröffentlicht die funktionieren und mit denen man spannenede sachen machen kann.
bei sill meldet man sich mit seinen bluesky- (oder beliebigen anderen ATproto-) login an und bekommt ohne weiteres zutun eine von seinen bluesky- (oder mastodon-) kontakten kuratierte und gewichtete linkliste.
bei margin meldet man sich mit seinen bluesky-login an und sieht bookmarks, anmerkungen oder hervorhebungen von textbasiertem zeug aus dem internet von allen menschen in der ATmosphere — und sicher auch irgendwann eine filtermöglichlichkeit auf menschen denen man folgt.
mein sifa-profil zeigt ohne weiteres zutun von mir auch meine bei popfeed als gesehen markierten serien und filme an.
das tolle am AT-protokoll ist, dass sich dienste und menschen auf basis dieses protokolls — und seiner (beliebig) erweiterbaren, strukturierten lexika — verbinden können. eine gemeinsame, offene, gestalbare sprache ist die basis von gemeinschaft.
man muss meine (aktuelle) begeisterung für protokolle nicht teilen. ich interessiere mich zum beispiel sehr wenig für den CAN bus oder das OBD-II protokoll. aber ich weiss, dass man mit ihnen spannende sachen mit autos machen kann. vor allem weiss ich, dass standardtisierte, offene protokolle jede technologie soweit voranbringen können, dass sie für jedermann und jederfrau nutzen bringen. kaum jemand interessiert sich für TCP/IP, http oder SSL, aber mittlerweile nutzten sie fast alle und freuen sich darüber, ohne zu wissen worüber sie sich freuen.
für mich ist wirres.net die quelle der wahrheit. nicht in dem sinn, dass alles was hier geschrieben steht stimmt, sondern das alles was ich ins internet schreibe und poste seine heimat hier hat. ich veröffentliche hier und verteile anderswohin. in ausnahmen veröffentliche ich auch anderswo, aber dann hole ich es auch wieder hierher. dafür gibts die beiden indieweb-begriffe POSSE und PESOS, aber das ist egal, weil das grundprinzip wichtiger ist, als wie man es nennt. der entscheidende punkt ist, dass ich einerseits hier alles an einer stelle beisamen und persistiert haben möchte und andererseits aber auch die menschen dort erreichen möchte wo sie gerade sind.
meiner mutter schicke ich automatisiert jeden artikel per mail. technikartikel wie diesen ignoriert sie einfach, zu langen, pseudophilosophischen texten schreibt sie mir fast immer zurück.
ich weiss dass (relativ) wenig menschen lust haben wirres.net in ihrem browser aufrufen, es aber gerne im RSS-reader ihrer wahl lesen. deshalb stelle ich RSS-feeds zur verfügung und gebe mir grosse mühe dass sie gut funktionieren und keine (oder wenig) einschränkungen zum original haben.
selfies poste ich weiterhin in kopie auf instagram, weil die menschen auf instagram aus mir unbekannten gründen gerne selfies und blumen sehen.
fotos und links zu manchen längeren artikeln poste ich auf bluesky und mastondon, weil es dort menschen gibt, die gerne auf diese art daran erinnert werden, dass ich ins internet schreibe und fotos poste.
filme und rezensionen zu filmen kopiere ich gelegentlich auch auf letterboxed, weil es dort (vielleicht) leute gibt die sie auf wirres.net nicht gefunden hätten und sich (vielleicht) über meine rezension freuen.
ich mache wieder checkins mit swarm, weils geht und es für mich der einfachste weg ist fotos mit text auf wirres.net zu posten (mit ownyourswarm). gelegentlich favt auch jemand checkins von mir auf swarm.
die liste kann ich fast beliebig weiterführen, der entscheidende punkt ist, dass die gezielte verteilung meiner inhalte im internet einerseits anderen entgegegnkommt und andererseits für mich die beschäftigung mit interessantem technik-gedöns bedeutet.
artikel im volltext mit dem standard.site protokoll in die ATmosphere zu blasen ersetzt RSS nicht. aber es eröffnet neue potenziale der entdeckbarkeit, von empfehlungs- und interaktionsmöglichkeiten. wenn ich einem RSS feed folge weiss das niemand. wenn ich einer standard.site publikation folge, wie zum beispiel nicos couchblog, sieht man das hier oder auch hier.
wenn ich ein bookmark in meinen river werfe sieht das kaum jemand. man kann die bookmarks zwar per RSS abonnieren (oder alles, wirklich alle abonnieren), aber vielleicht ist es ja besser dieses bookmark auch in einer dezidierten bookmarkanwendung finden zu können. hier zum beispiel. oder hier. wenn man sich mit seinem bluesky-login dort angemeldet, kann man mein bookmark kommentieren, weiterverteilen, faven oder selbst sichern.
das verteilen meiner artikel oder bookmarks ist und war nicht kompliziert. ausser schreibzugriff auf mein (bluesky) PDS (per app-passwort) brauche ich nichts weiter. kirby schickt dann ziemlich leichtgewichtige json-blobs an den PDS und fertig. obwohl margin.at keine ausgewachsene API hat, kann ich dort bookmarks, anmerkungen oder markierungen einfach (per knopfdruck) aus meinen ohnehin vorhandenen bookmarks auf wirres.net senden. ich brauche keine margin.at-app, das AT-protokoll reicht. wobei eine margin-app (fürs handy) gibts eh nicht, wohl aber eine chrome extension. die brauche ich dank des protokolls nicht zum anlegen von bookmarks, aber sie ist trotdem toll, weil zitate die ich ins bookmark kopiere, dann mit der extension in chrome auch auf der seite markiert werden.
diese markierung wäre dann auch sichtbar für jemanden der bei margin.at angemeldet ist und die chrome extension installiert hat.
ich weiss, alles technische, komplizierte spielereien deren nutzen zweifelhaft oder zumindest nicht sonderlich weit verbreitet ist. null relevanz. aber so viel potenzial.
um nochmal das zitat von tim trautmann von oben zu wiederholen:
Whether atproto ends up being the thing, or a stepping stone to the thing, I don't know.
weiss niemand, ob das zu was führt oder jemals von normalen menschen adaptiert wird. aber interessant ohne ende isses schon — und es funktioniert.
die überschrift („ich will keine APPs, ich will APIs“) habe ich ein bisschen im text vernachlässigt. das hole ich jetzt nach.
mir ist das schon seit vielen jahren aufgefallen, dass viele hersteller von sachen glauben, dass ihre sachen eine app brauchen. in der praxis geht das oft völlig am bedarf vorbei. bei der heimautomatisierung setzt sich (j sei dank) langsam die erkenntnis durch, dass es keinen sinn macht wenn der kühlschrank, die spülmaschine, der airfryer, der staubsaugerroboter und die lichter jeweils eine eigene app haben. langsam setzt sich (dank matter) die erkenntnis durch, dass offnene protokolle der weg sind, mit denen technisch komplexe sachen irgendwann mal akzeptanz finden können.
mit protokollen kann ich mit den sachen entweder machen was ich will oder etablierte, stabile systeme eines herstellers meiner wahl nutzen. im fall von heimautomatisierung zum beispiel home assistant, homekit, google home oder dieses alexa-gedöns.
wedium hat den schuss offenbar nicht gehört. wedium, das ich seit der republica „testen“ darf, erscheint mir als das langweiligste, verschlossenste und nutzloseste „soziale Netzwerk“ der welt.
im web ist wedium nicht zugänglich, beiträge sind auch nicht ausserhalb der app teilbar. der share-button in der app kopiert lediglich eine url des beitragsbildes. ich kann auf ios noch nicht mal aus der photos-app ein bild per share-button zu wedium sharen. nicht eine schnittstelle habe ich in der beta-version der app gesehen.
aber das ist neben dem „sozialen“ der ganze witz an einer netzwerk app: dass man sie vernetzen kann, dass man mit APIs spielen kann, potenziale ausloten kann, dass man als nutzer die app besser machen kann, indem man mit auf dem netzwerk rumhackt. völlig unverständlich, dass man bei wedium glaubt nicht nur das rad netzwerk neu erfinden kann, sondern dass man es auch von null auf besser machen könne.
so überwältigt ich in den letzten paar tagen vom AT-protokoll war, davor ganz ähnlich vom fediverse und activityPub fasziniert war, so unterwältigt bin ich von wedium.
wenn wedium schon das marketing verkackt, wie soll das dann erst mit der eigentlichen maschine klappen? bei der konkurenz? also konkret den grossen (über-) mächtigen plattformen und den vielen kleinen, spannenden, lebhaften und dynamischen projekten, die auf offenen protokollen aufsetzen.
spannende zeiten, aber höchstwahrscheinlich nicht für wedium.
mit seinem ATmosphere login (zum beispiel dem von bluesky) kann man sich bei sehr vielen diensten anmelden. die daten dieser dienste werden teilweise bei diesen diensten gespeichert, aber hauptsächlich auf dem zum AT-login gehörenden PDS (personal data server). auf einem bluesky-PDS werden zum beispiel alle meine bluesky-beiträge gespeichert: pdsls.dev
weil ich mich zum testen in den letzten tagen bei sehr vielen dieser ATmosphere-diensten angemeldet habe, liste ich die hier mal auf, damit ich auch selbst den überblick behalte.
hier kann man (allen existierenden) standard.site beiträgen folgen, sie liken und teilen. wie ein RSS reader, ohne RSS. was ich sehr mag: rendert meine beiträge die ich auf dem PDS sichere sauber.
Reader für standard.site dokumente und RSS. rendert markdown nicht sauber, fühlt sich etwas sluggish und überladen an und ist derzeit nicht offen für anmeldungen. trotzdem vielversprechend.
reader der links aus bluesky-beiträgen und eigenen quellen zu einem feed aggregiert:
Sill finds the most popular links in your Bluesky and Mastodon feeds to give you a clear picture of what’s happening. It does this by watching your timelines for links that people post, and then aggregates them by the number of people who shared each link.
medienaktivitätstracker für filme (aber auch bücher, spilee, fernehen und musik). gerade erst angemeldet. wenn ich einen weg finde meinen medienkonsum den ich hier tracke dorthin zu aggregieren, mach ich da auch mit. wirkt auch etwas sluggish und buggy.
Since 2023-05-01, removing the staging.bsky.app/profile part of Bluesky URLs to his posts will redirect to the canonical post on aaronparecki.com. For example
ich „syndiziere“ (mit dem indieconnector) nicht alle, aber viele meiner beiträge von wirres.net zu mastodon und bluesky. zum beispiel ist der beitrag „currywurst“ auch auf bkluesky.
leider sind die jeweiligen IDs 3mn3kzvtns72d (bluesky) oder 01KSWYPT075VEG8SEYF91ABR7X (mastodon/GTS) nicht viel kürzer als die artikel ID die kirby angelegt hat: mqmwcyaybdffzdty.
aber so richtig kurz waren die nicht gerade, deshalb bin ich zu meinen alten kurz-url-muster zurückgekehrt: mein vorheriges CMS ezpublish hat die artikel-id einfach hochgezählt. bei alten artikeln habe ich das beibehalten und das funktioniert wie eh und je, auch das alte articleview-url-muster:
das ist ein veritables rabbit hole in das ich mit dem standard.site-gedöne gestern gefallen bin.
ich habe gelernt, dass es neben dem fediverse auch eine ATmosphere gibt, hinter dem fediverse steckt das activity-pub protokoll und hinter der ATmosphere steckt das AT-protokoll. und nachdem ich mich gestern durch die spezifikationen und umsetzungsoptionen gewühlt habe, zeigt sich, dass die ATmosphere bereits gut mit inhalten aus wordpress-blogs gefüllt ist, weil der umtriebige matthias pfefferle nicht nur das activity-pub protokoll in form eines wordpress-plugins einem breiten blog-publikum zugänglich gemacht hat, sondern auch einen plugin namens wordpress-atmosphere baut. wer das nutzt und konfiguriert hat landet in der ATmosphere firehose.
ich habe mich mal imn der standard-reader.app angemeldet und ein paar abos gesetzt. dort findet man alle blogs die ihre beiträge im standard.site-format im AT-protokoll veröffentlichen oder anteasern.
ich bin ein viel zu grosser fan von RSS um RSS in naher zukunft abzuschreiben, aber dieses neue format auf basis des AT-protokolls ist schon „RSS done right“, wie ich gestern irgendwo gelesen habe. neue beiträge müssen nicht abgerufen werden, sondern werden gepusht, die nutzung mit einem client hat das potenzial kindereinfach zu sein und die inhalte in die ATmosphere zu blasen ist dank matthias pfefferle (für wordpress-nutzende) auch kinderleicht. ich hab weiter RSS, aber jetzt auch was im AT-protokoll. nächster schritt: auch mit volltext. dann steige ich aber für ein paar wochen aus dem rabbit hole aus und schau mir die entwicklung dann später nochmal an.
bei maurice habe ich vor ein paar stunden diesen artikel gelesen: IndieConnector und standard.site. standard.site? nie gehört, also hab ich angefangen mich einzulesen und LLMs meines vertrauens um erklärungshilfe gebeten.
bevor ich die frage was das eigentlich genau ist beantwortet, bzw. verstanden hatte, fragte ich chatGPT wie ich das nutzen könnte. ich verstehe technisches gedöns am besten während des machens. also habe ich mich an der doku entlanggehangelt und erstmal in einem „PDS“ einen site.standard.publication eintrag (record) angelegt.
PDS ist ein personal data server, also ein server auf dem meine daten für das AT-protokoll liegen. in meinem fall ist der bluesky-server der einzige AT-protokoll server den ich derzeit nutze. da ich mit der web-app von bluesky nicht auf die site.standard oder irgendwelceh anderen einträge schreibend zugreifen kann, nutze ich pdsls.dev. dort kann ich mich mit meinen bluesky-konto authentifizieren und dann einträge anlegen und editieren.
später habe ich dann gesehen, dass mat marquis den prozess hier genau erklärt hat: Implementing Standard.Site
aber ich habe mich da mit LLM-hilfe erstmal selbst durchgehangelt. so sehen meine einträge bei pdsls.dev aus.
pdsls.dev eintragslste
unterwegs habe ich dann langsam verstanden was das ganze soll.
site.standards.publication verknüpft wirres.net mit meiner bluesky identität (@wirres.net)
ich kann blogeinträge im AT-protokoll registrieren und damit mit meiner bluesky identität verknüpfen
hört sich erstamal unspektakulär an und ist es auch. der direkt sichtbare nutzen ist eine extra zeile bei der link-vorschau.
link-vorschau mit extra icon und „wirres.net von @wirres.net“ zusatz
im prinzip kann ich meine blogbeiträge jetzt ins AT-protokoll auf den bluesky-server kopieren. praktisch übermittle ich momentan nur ein paar metadaten von neuen artikeln, aber mit dem veröffentlichen eines neuen artikels kann ich genauso gut den volltext mitschicken. ob und wer das dann konsumiert ist eine andere frage, aber die artikel sind dann, wie RSS, mit den entsprechenden clients konsumierbar.
warum das relevant ist, oder warum mich das interessiert, erklärt steve dylan:
Thankfully, atproto is paving a different path. Instead of using the old platforms owned by the 1%, people are building solutions that are owned by everyone. One community built solution is Standard.site, a set of JSON schemas known as lexicons that finally give hope to solving the content distribution problem. When a blog, or any app for that matter, uses the Standard.site lexicons, the published content can be indexed by just about anyone. That index can be used to build so many mechanisms for distribution, and none of it is controlled by one individual or organization. You can control how you explore and consume that content.
ich bin ja der überzeugung dass jeder meine inhalte so lesen soll wie er oder sie es will — und vor allem wo er oder sie das will. um meine beiträge zu lesen muss niemand im browser auf wirres.net vorbeikommen. rss reicht. als man bei facebook (vor vielen jahren) instant articles veröffentlichen konnte, hab ich das gemacht und man konnte wirres.net in der facebook-app oder website lesen. würde es einfacher gehen oder würde noch irgendwer medium.com nutzen, würde ich alle meine artikel dorthin syndizieren — aber da ist ja, soweit ich sehe, neimand mehr. die quelle ist immer hier auf wirres.net, korrekturen, edits oder ergönzungen werden automatisch per RSS weitergegeben und so verspricht auch das standard.site-protokoll zu funktionieren. finde ich also gut und spiele da ab jetzt mit rum.
mal schauen wo das hinführt, auf jeden fall sind solche technologien für das offene web gut und spannend.
nachtrag 08.06.2026:
wenn ich meine blogposts ins AT-protokoll kopiere, was ich bis jetzt nur mit den metadaten mache, sind sie öffentlich zugänglich und mit entsprechenden clients auffindbar. das hab ich oben ja schon geschrieben. und so sieht das dann für die beiden beiträge, mit denen ich das bisher gemacht habe, aus, hier auf pckt.blog, docs.surf und standard-search
standard-reader.app ist wie ein RSS-reader für publikationen die per standard.site veröffentlichen. man meldet sich mit seinem bluesky-konto an (bzw. dem AT-protokoll handle) und kann dann einzelnen publikationen folgen oder suchen.
ich habe ein paar kleinigkeiten am layout und an den funktionen von wirres.net angepasst. ich fand den fuss meiner artikelseiten zwar immer ganz ok und er orientierte sich auch an meinen vorherigen designs, aber links und buttons waren insbesodnere auf dem handy immer sehr fuselig zu treffen. deshalb hab ich dort alles erstmal etwas entzerrt.
artikel-fuss vorher und nachher
im fuss sind ausserdem zwei buttons dazugekommenm; einer zum kopieren der artikel-url (die man sich auch aus der adressleiste oder dem datumslink holen kann) und einmal ein „.md kopieren“ button. wenn man den klickt, bekommt man den quelltext der seite im markdown format. ich habe gelesen LLMs mögen das und von mir aus können sie gerne meine artikel in markdown, statt html lesen. aber ich glaube der button kann auch für menschen nützlich sein. wenn ich andere zitiere ist copy und paste des text kein problem. wenn der zitierte text aber links enthält, muss ich die immer händisch räuberkopieren. mit einem wysiwyg-editor ist das kein problem, aber ich mag kein wysiwyg. ich mag und schreibe in markdown. naja, jedenfalls kann man sich das mit dem button in die zwischenablage kopieren oder auch einfach an die artikel-adresse ein „.md“ hängen:
das geht für fast alle artikel und meistens klappt ganz gut. theoretisch kann ich mir jetzt ein kleines script schrieben (lassen), dass alle beliebten artikel als .md-dateien in ein verzeichnis kopiert und daraus eine pdf oder ein epub erzeugen. oder die bots, die hier ohnehin immer vorbeikommen, freuen sich.
ausserdem habe ich einen „kommentieren“ button hinzugefügt, der auf die kommenatr-sektion in der beilage verlinkt. auch das eingabe-formular habe ich etwas entzerrt, weil es mobil eine zumutung war. ausserdem sind die system-texte die das kommenatrmodul (danke maurice) versendet jetzt deutsch.
die „kurzurl“ ist nicht sonderlich kurz, aber eindeutig und in kirby schon bei jedem artikel dabei: es ist die artikel-ID. funktioniert, aber ich bin unsicher ob ich das jemals nutzen werde.
die „ask chatgpt“ und „ask claude“ buttons habe ich von hacks/hacker (via). wenn man die klickt und in einem der beiden chatbots eingeloggt ist, kann man sich das selbst-lesen meiner artikel sparen und chatGPT oder claude lesen lassen. ich weiss auch nicht ob das praktisch ist, aber auch das funktioniert und das allein reicht mir erstmal. kost ja nix.
obwohl, kostet schon was. zeit und auch geld. meine hosting-kosten sind im letzten monat von 0 auf ca. 40 euro hochgegangen. obwohl ich auch noch den android auf uberspace wo wirres.net früher lief nicht gelöscht habe und der auich nochwas kostet. mein programmierhelfer und debugger cursor kostet auch so um die 30 euro pro monat. werbung will ich hier nicht mehr machen und leser nach geld fragen auch nicht. obwohl das theoretisch und praktisch bereits möglich ist. aber wenn ich mir ansehe wie wenig unterstützung ein tolles projekt wie rivva bei steady bekommt, glaube ich nicht das ein projekt wie dieses hier irgendwen zur geldbörse greifen lassen würde.
ach ja. einige bereiche die hier in der vergangenheit etwas zäh liefen, sind jetzt durch strategisches caching merklich flotter geworden, insbesondere meine bilder-übersicht, oder die baum-bilder.
kirby und alle plugins sind jetzt auch auf dem neuesten stand. das updaten finde ich immer etwas nervenaufreibend, aber wie (bisher) immer, hat das reibungslos und unfallfrei geklappt.kirby ist toll ♥️
Ich habe in den letzten Wochen sehr viel KI genutzt. Ich glaube, das wird auch nicht mehr so schnell aufhören. Es wird ein Werkzeug werden und ich werde gleichzeitig als Nutzer, Konsument, Bürger oder Angestellter immer öfter mit KI konfrontiert sein. […] Ich versuche ab jetzt hier im Blog immer mal wieder aufzuschreiben, was mir mit KI passiert ist, was ich damit gemacht habe, wo es fürchterlich war. Höchstwahrscheinlich werden viele Sachen sehr schnell, sehr schlecht altern.
ich finde das eine hervorragende idee festzuhalten wie ich KI nutze und wie sich das über die zeit gegebenenfalls ändert. vor allem wenn ich bedenke, was sich in den 14 monaten seit meinem ersten mit kirby veröffentlichten artikel getan hat. wenn ich mich recht erinnere, habe ich damals, also vor etwas über einem jahr zwar gelegentlich schon chatGPT benutzt, aber zum beispiel das migrationsscript noch klassisch gebaut: selbst googlen, gefundene scripte umbauen, testen, mehr googlen, mehr testen, weiter umschreiben, debuggen und optimieren. sehr geholfen haben mir bei der planung und umsetzung der neuen wirres.net-version zuerst auch bastian allgeiers kirby tutorials. ich habe von bastian viel über kirby gelernt und vor allem über strukturierte und saubere php-programmierung. und ich habe damals sehr, sehr viel selbst am code gemacht.
gelegentlich habe ich dann auch chatGPT im chat-modus um code-snippets gebeten, aber das copy&pasten und die korrekturschleifen wurden dann sehr schnell lästig und ich habe mir von chatGPT erklären lassen wie ich VS-code als programmierumgebung, inklusive chatGPT unterstützung einrichten und nutzen kann.
VS-code war dann für mich ein game changer. ich habe immer schon direkt alles auf dem live-server „entwickelt“, per SFTP client und BBEdit. da VS-Code auch direkt auf dem server laufen kann (per SSH), habe ich dann mit VS-code zu zweit, also mit unterstützung von chatGPT direkt auf dem live-server am code gearbeitet. mit VS code ist das wirklich angenehm, transparent und aus meiner sicht auch sicherer als mein gefrickel vorher: alle codeänderungen werden im editor markiert und sind reversibel. zusätzlich habe ich angefangen änderungen mit git (auf dem server) lokal zu versionieren.
so habe ich monatelang an wirres.net rumgeschraubt bis mir irgendwann cursor über den weg lief. cursor nutzt im prinzip auch VS-code, aber dahinter sind sehr viele mögliche LLMs. ich bezahle cursor eine monatliche gebühr und kann dafür eine grosse auswahl an agents nutzen, nämlich die, die der cursor agent gerade für geeignet für die aufgabe hält.
Ich bin kein einzelnes Modell, sondern der Agent-Router in Cursor. Ich lese euer Setup, führe Befehle aus, ändere Dateien und denke mit.
in der regel lasse ich die agentenauswahl auf auto. aber gelegentlich, wenn die automatisch ausgewählten agents nicht so arbeiten wie ich das wünsche, stelle ich eine weile auf teurere und besser mitdenkende agents um, deren nutzung bei meinem abo-modell allerdings begrenzt ist.
seit der umstellung auf einen hetzner server, sind hier und da performance probleme sichtbar geworden die vorher nicht ins gewicht fielen. die standard (auto) agents haben da teilweise keine befriedigenden lösungen oder ansätze gefunden. eine explizite umstellung auf (claude) opus-4.8 hat dann sehr viel klügere und strukturiertere vorschläge geamacht, die so effektiv waren, dass die grundlast des servers von einem lauten rauschen zu einem leisen plätschern geworden ist.
das scheint mir das wirklich gute an cursor zu sein: ich muss nicht bei mehreren KI-firmen konten anlegen und geld zahlen — und kann sie trotzdem alle nutzen.
heiko deutet das auch an: es ist wichtig zu wissen was man will und wie das alles grundsätzlich funktionieren soll. dann kann man KI-agenten als sparringspartner mitdenken lassen und ideen umsetzen lassen. die KI denkt manchmal in absurde oder viel zu komplizierte richtungen. aber wenn ich die arbeit wie ein architekt angehen, also einen plan und das grosse und ganze im kopf habe, dann kann man die KI wie einen handwerker oder fachingenieur nutzen.
seit ein paar wochen nutze ich cotypist, das ist eine KI die lokale modelle nutzt um beim tippen wort- oder satzvervollständigungen zu machen. das hilft mir vor allem dabei mit weniger buchstabendrehern zu schreiben und gelegentlich einen ticken schneller zu schreiben. das ist ein bisschen so wie das tippen auf dem iphone, nur etwas besser und kontext-sensibler als das was apple in iOS bietet. kein game changer, aber sehr praktisch.
was meine texte hier auf wirres.net angeht oder meinen vortrag: ich schreibe alles selbst. aber ich habe gemerkt, dass ich LLMs als resonanzraum, einschätzer, zusammenfasser und plausibilitätschecker sehr gerne nutze. für längere texte oder meine republica sessions neige ich dazu mir wahnsinnig viele notizen zu machen und dann gelegentlich den überblick über meine notizen und quellen zu verlieren. da sind LLMs, oder cursor, teilweise sehr hilfreich um mich in meiner gedankenwelt zu orientieren und mir meine eigenen notizen kurz und knapp zu erklären.
gelegentlich habe ich LLMs gebeten meinen schreibstil zu imitieren, aber das hat bisher noch nie ein befriedigendes ergebnis gebracht. vor ein paar jahren habe ich übrigens etwas ähnliches gemacht, nur dass da nicht ein LLM meinen schreibstil imitieren sollte, sondern eine ghostwriterin. auch das hat damals nur so mittelprächtig funktioniert.
beim schreiben dieses artikels fiel mir ein zitat ein das ich in den letzten tagen aufgeschnappt hatte. nach etwas nachdenken fiel mir ein, dass das wohl in einem video gewesen sein musste. zuerst fragte ich chatGPT, der war zu doof, aber gemini verstand mich:
promt
in diesem video spricht einer der designer von nostalgie und dass nostalgie sich eigentlich auf etwas bezieht, was in der vergangenheit der neue heisse scheiss war. findest du das zitat so, oder soll ich mal das transcript hierrein copy & pasten?
antwort
Ja, ich habe die Stelle gefunden! Das ist ein zentraler Punkt des Gesprächs zwischen Flavio Manzoni (Ferrari Chief Designer) und Jony Ive.
Das Zitat bzw. der Gedankengang findet sich vor allem im Kapitel "The Future of Ferrari" (ab ca. 17:23). Flavio Manzoni zitiert dort den Komponisten Gustav Mahler, um Ferraris Philosophie zu erklären:
"Tradition is not the worship of ashes. Tradition is the preservation of fire." (Tradition ist nicht das Anbeten der Asche, sondern die Weitergabe des Feuers.)
Zuvor (ab ca. 09:00 und später ab 18:15) führt er diesen Gedanken weiter aus: Er erklärt, dass wir heute in einer Ära mit einem sehr starken "nostalgic approach" leben, in der die Leute oft nur zurückblicken. Er betont aber, dass Ikonen wie der Ferrari F40 (der heute Inbegriff der Ferrari-Nostalgie ist) zum Zeitpunkt ihres Erscheinens extrem kontrovers und radikal neu waren.
das hätte ich auch mit leichtigkeit in 20 minuten selbst rausfinden können, indem ich in dem video rumspringe oder das transscript copy & paste und mir passende suchbegriffe ausdenke. aber sowas eine KI machen zu lassen ist schon eine echte erleichterung.
wobei es mir bei der nutzung von KI weniger ums zeitsparen geht, mit KI kann ich dinge umsetzen, die ich vorher nicht hätte umsetzen können. zeit spart das meistens nicht, weil alles was ich KI machen lässt immer nochmal 2-3 (und manchmal sehr viel mehr) korrekturläufe und neuansätze braucht. aber das ist das wesen von werkzeugen: man kann mit ihnen tolle sachen bauen, wenn man weiss was man will und was man tut.
oder umgekehrt: werkzeuge erweitern die fähigkeiten ihrer nutzer, aber auch deren fehler und irrtümer. sie ersetzen weder geschmack noch urteilsvermögen. um aus einer spanplatte etwas schönes zu machen, braucht man mehr als eine kreissäge. und die letzten jahrzehnte haben gezeigt, dass bessere werkzeuge nicht automatisch zu besseren ergebnissen führen. dank kreissägen und modernen plattenbaumaterialien hat sich die welt mit billigen, austauschbaren möbelschrott gefüllt — oder wie man heute sagen würde: spanplatten-slop.
mit mühe und sorgfalt — und im besten fall etwas geschmack und erfahrung — kann man werkzeuge aber auch nutzen um zu besseren ergebnissen zu kommen. slop ist nicht die folge von werkzeugen, sondern ihrer uninspirierten nutzung.
ich mal wieder aus dem maschinenraum. ich habe heute früh die DNS-einträge für wirres.net auf eine hetzner IP umgestellt, nachdem ich innerhalb von wenigen stunden die ganze site auf eine neue hetzner VM migriert habe. die migration war wirklich einfach:
bei hetzner eine VM einrichten, etwas an der ssh-konfig drehen und docker installieren
rsync von 10 GB daten
docker container hochfahren
fertig
natürlich gabs danach noch ein paar kleinigkeiten geradezuziehen, aber das schöne ist, wirres.net ist damit einerseits prima und komlett mit einem rsync zu backuppen oder zu migrieren und die gesamte serverlogik (apache, php, opcache, etc.) steht (jetzt) in einer docker-konfiguration, die sich theoretisch überall deployen lässt.
soweit scheint mir, dass alles funktioniert. die performance schien am anfang ein paar mal kurz am anschlag, auch wenn die anzahl der CPU kerne und RAM auf dem papier die gleichen sind, scheint es mir, als sei die hetzner-VM etwas schwachbrüstiger. ich beobachte das weiter und falls euch etwas auffällt was nicht funktioniert oder klemmt, lasst es mich wissen. aber ich sehe auch hier mal wieder warum kirby so ♥️ ist.
ich liebe youtube. also nicht youtube an sich, aber videos auf youtube zu sehen. im monat zähle ich ungefähr 50 stunden, die ich vor der tube sitze. ich habe auch grossen respekt vor dem algorithmus der mir die videos zusammenstellt. die mischung der videos ist interessant genug um mich bei der stange oder tube zu halten, aber ich bekomme trotzdem keine schwurbler-videos vorgesetzt oder videos in die timeline gespült, nur weil sie gerade „trenden“ oder so. youtube ist meine guilty pleasure, mein gar nicht mal so heimliches laster1.
wer den videos die ich mag folgen will, alle videos, unter die ich einen positiven daumen setze, landen im favoriten stream (RSS).
als ich gestern ein video von der 2MR Konferenz sah, habe ich zunächst gar nicht gemerkt, dass es kein youtube-video war, saondern auf peertube lag. um es so auf wirres.net einzubetten wie ich es mag (ohne explizite freigabe kein fremdcode oder iframe oder javascript von drittservern), musste also ein neuer embed block her. cursor und claude konnten das schnell umsetzen und das funktioniert auch, wenn ich ein peertube-video fave (beispiel).
soweit das neue aus dem maschinenraum.
was mir dann aber noch auffiel: ich muss mich bei jeder peertube-instanz separat anmelden, wenn ich dort übeer den browser einen echten fav hinterlassen will. das ist ja eigentlich bei allen fediverse instanzen so, egal ob mastodon oder gotosocial oder pixelfed. im browser stehe ich immer dumm unangemeldet da. ich weiss, ich kann die url der peertube seite in meinem mastodon client im suchfeld eingeben und dann interagieren (faven, kommentieren), aber warum dieser umweg? im indieweb gibts indieauth was wirklich einfach zu nutzen ist und mit dem man sich über die eigene webseite anmelden kann. das ist so dezentral wie es nur sein kann und ich frage mich, warum können fediverse instanzen nicht auch identity-provider sein? wenn ich mich an beliebigen fediverse instanzen, die ich im browser besuche, einfach so anmelden könnte um dort zu interagieren, wäre das aus meiner sicht ein echter fortschritt in sachen bedienfreundlichkeit und konsistenz. oder übersehe ich etwas? gibts das schon? oder ist das komplizierter als ich gerade denke?
ich gucke youtube werbefrei in safari, ohne youtube dafür geld in den rachen zu werfen. der trick ist eine safari erweiterung namens vinegar. vinegar tauscht einfach den youtube-player mit dem nativen browser-player aus und umgeht damit die werbung. das funktioniert so gut, dass youtube in meiner anseh-historie sogar werbeclips anzeigt, die ich angeblich gesehen hätte, aber nie gesehen habe. das heisst im umkehrschluss, den youtube-kreatoren entgehen dadurch keine werbeeinnahmen und ich muss den scheiss nicht sehen. ↩︎
hier schreibt felix schwenzel seit 24 jahren gerne ins internet (eigentlich seit 30 jahren).
von 23 auf 24, bzw. 29 auf 30 umgesprungen, weil der erste artikel den ich hier veröffentlicht habe vom 20.04.2002 ist. mir sind diese jahrestage eigentlich nicht wichtig, aber statistiken mag ich gerne. deshalb betätige ich mich mal eben als statistik-chronist.
wahrscheinlich wäre es mittlerweile besser, unten hinzuschreiben, dass ich jetzt schon „sehr lange“ ins internet schreibe. bei solchen zeiträumen ist der genaue tag dann auch irgendwann egal, so wie mir die kalendarischen koordinaten meiner geburtstage nach fast 60 jahren mittlerweile auch egal sind.
kirby nutze ich jetzt auch bereits seit über einem jahr („hallo kirby“). ich bereue den umstieg nicht, im gegenteil, kirby ist mir jeden tag erneut eine grosse freude.
was ich jetzt auch seit fast einem jahr mache: jeden tag etwas veröffentlichen. der streak ist mittlerweile 359 tage lang. die anzahl-der-posts-übersichtgrafik auf der rückseite ist mittlerweile ohne schwarze punkte.
bemerkenswert an der grafik ist eigentlich nichts, ausser dass man kaum muster erkennen kann wie und wann ich wie viel veröffentliche. man erkennt allerdings ein cluster zwischen mai und juni: republica. so erkennt man: noch vier wochen bis zu #rp26. das minimalistische design dieses jahr gefällt mir sehr gut, hier meine „speaker-seite“ für dieses jahr. ende der durchsage.
als ich vor 23 jahren anfing mit einem content managment system ins internet zu schreiben, war ich in vielerlei hinsicht ein bisschen naiv. auch was die nutzung von bildern angeht. wenn schlechte witze (arnold schwarzegger hat schrankfarbene haare) die nutzung eines bildes erforderten, suchte ich mir ein bild und benutzte es. 2002 wurden urheberrechtsverstösse eher selten geahndet und google war gerade mal 4 jahre alt.
spätestens zu zeiten von marions kochbuch (die älteren werden sich erinnern) fing ich an mein archiv für suchmaschinen zu verrammeln. bei artikeln die älter waren als 5 jahre verbot ich die suchmaschinen indexierung. das hat soweit gut geklapt. in den > 20 jahren in denen ich ins internet schrieb habe ich zwar die eine oder andere abmahnung bekommen, aber nie wegen urheberrechtverstössen. bis heute. ein foto von arnold schwarzenegger das seit 20 jahren im web rumlag, ausgeschlossen von suchmaschinen-indexierung und ungesehen von jeder menschenseele, wurde doch von irgendeinem rechteinhaber gefunden. die seite, auf der das bild laut anwaltsschreiben zu sehen gewesen sei, war von der suchmaschinenindexierung ausgeschlossen und damit im prinzip unsichtbar. ich weiss zwar, dass ethisch fragwürdige crawler sich nicht an robots.txt anweisungen halten, aber dass möglicherweise für die durchsetzung von urheberrechten auch solche anweisungen ignoriert werden, scheint neu zu sein.
die 250 € habe ich überwiesen, das bild gelöscht und den artikel entfernt und gleichzeitig habe ich alle bilder von artikeln die älter als 2010 sind mit thumbhash bildern ersetzt. thumhashs sind „very compact representations of an image“, die gerade mal ein paar byte gross sind. die nutze ich schon länger fürs lazyloading, man bekommt die also zu sehen wenn man wirres.net mit einer sehr langsamen internetverbindung besucht. ansonsten sieht man die nur selten. hier eine beispielseite aus meinem archiv.
die riesenmaschine macht das schon lange so mit bildern, deren rechtelage ungeklärt ist: einfach weglassen.
aber nur wegen eines anwaltschreibens soll mein archiv nicht weniger bunt sein. deshalb finde ich meine lösung, bilder erstmal pauschal auf wenige bunte byte zu reduzieren sehr schön. und artikel mit bildern, über deren rechte ich mir im klaren bin (zum beispiel weil ich die bilder selbst aufgenommen habe), kann ich von der thumbhashisierung ausnehmen, aber das ist ein manueller vorgang.
so hat die abmahnung auch was gutes: ein schönes neues feature, von dem ich aus dem maschinenraum berichten kann.
es gibt auch sonst einiges neues aus dem maschinenraum. zum beispiel neue feeds für den river, die favoriten, bookmarks oder was ich gesehen habe (alle feeds sind autodiscoverable oder hier aufgelistet). unter /alles sieht man jetzt auch wieder wirklich alles, ebenso im alles-feed. auch im archiv sieht man beiträge, favs, bookmarks und gesehenes jetzt einzeln aufgeschlüsselt — oder eben als alles.
das logbuch meines medienkonsums, das ich dieses jahr führen möchte habe ich um die youtube sehzeiten erweitert. derzeit steht mein medienkonsum bei ca. 70 stunden pro monat die ich vor der glotze verbringe. ich bin mal gespannt wie sich das oder ob sich das über das jahr verändert.
und apropos gewohnheiten, die man offenbar mit zunehmensdem alter liebgewinnt, mal schauen ob mir entwicklung der gewohnheit gelingt, diesen baum ein jahr lang jeden tag zu fotografieren.
natürlich ist es eine schnapsidee, filme oder serien hier tracken zu wollen. wenn ich wollte, könnte ich das alles bei trakt machen. trakt arbeitet mit einem leicht obskuren dritt-dienst zusammen (younify.tv) um die historie des gesehenen von netflix auszulesen. tatsächlich kann man damit die historie aller grossen streaming-angebote abgreifen — wenn man younify.tv genug vertrauen entgegenbringt und (vollen) zugriff auf diese dienste gewährt. mein vertrauen hat vor ein paar jahren nur dafür gereicht, younify.tv zugriff auf mein netflix-konnto zu gewähren, weshalb ich jetzt einen teil meiner netflix-historie auch in trakt habe.
der vorteil ist, dass ich die von younify.tv abgegriffenen daten, jetzt auch wieder über die trakt-api selbst abgreifen kann, zum beispiel mit diesem script. mit ein zwei weiteren phyton scripten kann ich deshalb jetzt auch automatisch auf netflix gesehenes hier loggen.
schnapsidee hin oder her, sowohl trakt als auch ich wissen, dass die schnapsidee alles gesehene zu loggen, nur funktioniert, wenn es vorwiegend automatisch geht. wenn da nicht die vertrauensfrage wäre. ein datenleck bei trakt von 2014, das trakt erst 2019 offenlegte, zeigt, dass es nicht angebracht ist, trakt 100% vertrauen zu schenken. wenn ich mich recht erinnere hab ich die verbindung zwischen trakt und plex schon vor 2019 gekappt, weil mir das einen ticken zu unheimlich war, meine plex-historie ungefiltert in trakt zu leiten. bei netflix hielten sich meine bedenken in grenzen.
mit meinem selbstgebauten plex/tautulli-zu-kirby-exporter behalte ich die kontrolle und der import in die öffentliche liste klappt auch ohne drittanbieter ganz gut, fast vollautomatisch. ich muss nur noch eine wertung nachtragen.
und auch wenn ich bei der netflix → younify.tv → trakt.tv → wirres.net konstruktion weniger bis keine kontrolle habe, wollte ich diese automatisierungs-pipeline jetzt testen. dafür musste ich mir natürlich irgendeinen scheiss auf netflix ansehen.
also hab ich mir die erste folge being gordon ramsay angesehen. ich vermute das wird weder so erfolgreich wie netflixchefs table noch so ein hit wie drive to survive — auch wenn das strickmuster ähnlich ist. beim überfliegen der kritiken ist eine überschrift hängengeblieben, der ich direkt zustimmen möchte: gordon ramsay should not be so boring.
jedenfalls funktioniert der sync zwischen netflix, younify.tv, trakt.tv und wirres.net/kirby, wenn auch mit leichter verzögerung.
zum thema ex- und importe: ich habe auch ein script gefunden, mit dem sich die daten aus tautulli, also plex, mit letterboxd syncen lassen. damit habe ich jetzt lücken meiner film-timeline auf letterboxd geschlossen, auch wenn die timeline der filme die ich jemals sah auf letterboxd immer noch lücken in den letzten 10 jahren hat. schliesslich schau ich filme ja nicht nur auf plex, sondern auch auf amazon prime, im kino (gelegentlich) oder netflix. aber weils geht, weil ich daten jetzt aus plex und netflix rausbekomme, erscheint es mir logisch meine film-historie erstmal auf letterboxd zu vervollständigen. dann kann ich sie auch wieder hierher holen. aber bevor ich das mache sammel ich hier, bis auf ein paar ausnahmen — zu testzwecken — erstmal vornehmlich in 2026 gesehenes und gelesenes.
mit so einer „datenbank“ für gesehenenes und gelesenes setze ich mich übrigens auch geschickt selbst unter zugzwang. jetzt muss ich auch mal wieder ein buch lesen, damit ich es loggen kann. und damit schliesst sich der zirkel: ausgehen um drüber schreiben zu können, scheisse auf netflix schauen, ums zu prüfen ob es automatisch geloggt wird. morgens spazieren gehen um das wetter zu fotografieren und fotos und .gpx-tracks zu posten, kochen um rezepte maschinenlesbar zu veröffentlichen, schlafen, um zu sehen, wie gut der schlaftracker funktioniert. (b)loggen weil’s geht.
eben habe ich die graham norton show gesehen, um zu gucken ob sie danach automatisch hier im blog auftaucht. tat sie.
die idee hatte ich gestern: warum nicht alle sendungen die ich gucke hier mit einem kurzen eintrag festhalten? am besten automatisch. also mach ich das jetzt.
ich mag die idee von micro-einträgen. das erzeugt zwar eine menge rauschen, aber das lässt sich auch gut ausblenden. bei bedarf lassen sich diese einträge aber auch auswerten oder für was auch immer mir einfällt verwenden. vor allem aber mag ich die idee, dass alles hier passieren zu lassen, hier also sozusagen life-logging zu betreiben. das ist ja auch was weblog ursprünglich bedeutete: sachen öffentlich, im web loggen. jetzt wo ich likes und lesezeichen hier logge, kann ich doch auch loggen was ich (fern-) sehe.
die idee mochte ich schon lange, nur stand mir die technik nicht zur verfügung. deshalb habe ich jahrelang watched.li von philipp benutzt. ich fand es in erster linie spannend zu sehen, wie viel zeit ich vor der glotze verschwende, aber watched.li half auch dabei zu vorrauszusehen, womit ich in zukunft meine zeit verschwenden konnte, welche serien und folgen bevor standen.
seit 10 jahren nutze ich neben plex auch noch tautulli, eine freundliche plex-begleit-app. im prinzip macht tautulli nichts anderes als plex zu beobachten und alles zu loggen: wer schaut wann was, was macht der server, was gibt’s neues? wenn ich zurück zu 2017 gehe, sehe ich, dass ich am 14. august 2017 game of thrones s07e05 gesehen habe. um 22:43 war ich fertig mit der folge (ist game of thrones echt schon so lange her?).
mit tautulli hab ich als eigentlich alles was ich brauche: statistiken, details zu dem was ich (mit plex) gesehen habe.
andererseits nutze ich ja nicht nur plex. ich schau gelegentlich filme im kino, auf amazon prime, netflix oder RTL+. ich bin auch nicht der einzige, der den wunsch hat das alles zu tracken. heiko hat vor ner weile beschrieben, wie er seinen medienkonsum trackt: Medien-Tracking mit Github und YAML. thomas hat sich einen recorder gebaut, mit dem er alles was er sieht und liest festhält und bewertet. und jetzt hab ich mir in den letzten 24 stunden ein medienmenü zusammengehackt. ich hab mir vorgenommen das mal ein jahr lang auszuprobieren, also wirklich alles was ich sehe oder in buchform lese festzuhalten. was ich im netz lese halte ich ich ja bereits mit lesezeichen fest.
die technik dahinter finde ich betörend einfach: für jede serienfolge, film oder buch, lege ich einen beitrag mit den wichtigsten daten an: (von) wann, was, wie lange und wie wars? die beiträge kann ich ganz normal in kirby als content anlegen, aber auch per per webhook oder per micropub.
den webhook sendet tautulli sobald ich einen film oder serienfolge zuende gesehen habe und sieht so aus:
mit dem micropub-client sparkles kann ich gesehene filme anlegen.
die übersicht habe ich heute mit allem was ich 2026 gesehen habe gefüllt. die wenigen filme, die ich gesehen habe, mit sparkles, die serien manuell mit einem curl.
mit dem curl ging das ziemlich effizient, künftig sollte der grossteil der einträge dann automatisch aus plex/tautulli kommen, den rest pflege ich dann eben manuell nach, bis ich dafür auch eine automatisierung finde.
im prinzip ist die übersicht ein (h-) feed, den man theoretisch auch abonnieren könnte, aber da muss ich mir noch was überlegen, wie man das in einen sinnvoll rauschenden rss- oder atom-fluss umwandelt.
als nächstes werde ich versuchen ein paar tagesaktuelle statistiken zu erzeugen. ich finde man kann in der übersicht auch schon so einiges ablesen:
gelegentlich binge ich serien weg
starfleet academy hab ich nach folge 6 nicht mehr ertragen und aufgehört weiter zu sehen
ich finde A Knight of the Seven Kingdoms richtig gut
obwohl The North Water ziemlich gut ist, bin ich in folge 2 hängen geblieben
nachem ich mir gestern eine möglichkeit geschaffen spaziergänge als .gpx-dateien hochzuladen und darzustellen, habe ich mal geschaut, ob ich sowas schon früher versucht habe. dabei habe ich diesen alten artikel von 2015 gefunden, der zwar eine gpx-datei erwähnt, aber nicht beinhaltet. stattdessen fiel mir auf das der artikel ein paar fehler enthielt. die videos funktionieren nicht, asides werden mittig, statt am rand angezeigt und die fotos hatten noch keine expliziten lizenz-informationen. meine imports vom alten blog in kirby funktionierten eigentlich ganz gut, aber bei einzelen details klemmte es dann doch immer wieder, auch weil ich zum zeitpunkt des ex- und imports in kirby noch nicht alle features abgebildet hatte.
beim reparieren des artikels, fiel mir dann noch auf, dass die importierten fotos tatsächlich noch ihre exif-daten in sich trugen, also lud ich die auch nach. mit den exif-infos war es kirby dann möglich automatisch eine karte der foto-orte zu generieren, die sich dann erfreulicherweise fast so aussah wie die karte, die ich vor 10 jahren aus einer .gpx-datei generiert hatte, damals boch bei einem externen dienst, der längst das zeitliche gesegnet hat.
das freute mich sehr, denn so war der alte artikel nach der reparatur besser als vorher.
das dinge im netz kaputtgehen ist unumgänglich. auch die archive.org-version des alten artikels ist nicht mehr (oder war es nie) in ordnung. deshalb, lesson learned, ist es wirklich sinnvoll alle daten, originale bei sich zu behalten, man weiss ja nie wozu sie gut sein werden. und es ist immer sinnvoll dinge ohne harte externe abhängigkeiten zu bauen. das heisst nicht, dass man nicht auch mal externe dienste nutzen soll oder inhalte dorthin aggregieren oder syndizieren sollte, sondern eben, dass man es im ernstfall eben auch selbst machen kann, ohne abhängig von einem dritten zu sein.
deshalb freue ich mich auch so einen weg gefunden zu haben eine gpx-datei hier lokal darzustellen. mit komoot könnte ich sowas per iframe einbetten, aber dann habe ich einerseits eine abhängigkeit und andererseits tracking-codes eines dritten auf meinen seiten.
andererseits spricht nichts dagegegen touren, wie die wanderung um den „de meinweg“ weiterhin mit komoot aufzuzeichnen und dort zu teilen, so lange ich sie auch als gpx exportieren kann. genau diesen export hab ich jetzt im alten artikel über die wanderung nachgepflegt. wenn dann in 30 jahren komoot nicht mehr ist, hab ich immer noch alle wesentlichen daten bei mir.
seit ich angefangen habe bookmarks (und likes) bei mir zu sammeln (bookmarks, likes, replies, alles zusammen, wirklich alles), statt in pinboard, sende ich mit diesen lese- oder like-notizen auch webmentions an die betreffenden seiten. die meisten ignorieren das aus technischen gründen (weil sie keine webmentions unterstützen), aber manche nehmen die benachrichtigung entgegen. eay.cc zum beispiel, da wurden meine bookmark-webmentions dann aber komisch dargestellt, also hat er das repariert und spass dabei gehabt.
oder gestern habe ich crowdersoup.com einen kommentar geschickt. der wurde angenommen aber jetzt muss das layout offenbar repariert werden. bei beiden war ich offenbar der erste, der sowas geschickt hat und ehrlichgesagt bin ich hier auch nicht auf alle webmention-arten vorbereitet, die mir potenziell geschickt werden können.
aber das ist eben teil des spass: build & repair as you go, probleme dann lösen, wenn sie daherkommen. oder anders gesagt: eine webseite ist eine baustelle die wirklich kein ende hat — und das ist auch gut so.
ich weiss gar nicht mehr wie ich crowdersoup.com entdeckt habe, aber ich vermute über indiewebnews. den beiträgen dort folge ich seit kurzem wieder intensiver und komme dadurch vermehrt auf webseiten die sich mit den technologien des indiewebs auseinandersetzen — oder genauer: damit ringen. der gleichzeitige vor- und nachteil der indieweb-idee ist, dass es kaum fertige lösungen gibt und man sich eigentlich alles selbst zusammenbaut. das ist ein segen und ein fluch und ich verfluche die komplexität dieses indiwweb-gedöns auch regelmässig, um dann doch immer wieder einen neuen versuch zu starten.
diese definition von marty mcguire umschreibt die idee des indieweb ganz gut, vor allem was es ist und eben nicht ist:
indieweb.org is not a presciption or a cookbook or an exercise plan. It doesn’t tell you how to “be IndieWeb”. It’s a collective memory of experiments, some successful and some not, from a group of experimenters that has changed greatly over time.
was mir aber, abgesehen von den philosophischen fragen, heute auffiel: die idee des indiewebnews-aggregators kann man eigentlich weiterspinnen. indiewebnews ist ein aggregator in dem man sich selbst einträgt, einfach indem man indiewebnews verlinkt und dann ein webmention an indiewebnews sendet (anleitung auf deutsch bei news.indieweb.org/de). dieses vorgehen macht die seite nicht 100% spam-resistent, aber mit ein bisschen moderation könnte man daraus eigentlich sehr schöne aggregatoren zu allen möglichen themen bauen. wie gesagt, seit ich den englischen kanal der indiewebnews näher verfolge, habe ich viele neue, interessante webseiten/blogs gefunden die interessante sachen schreiben oder bauen oder zeigen. vielleicht könnte man so blog-themen-hubs bauen. mir fehlt leider die strukturierte phantasie um so ein konzept zu verfeinern, aber die discoverability und sichtbarkeit von blogs und webseiten zu verbessern ist ja ein erstrebenswertes ziel.
ich bin kein grosser fan von newslettern. mein newsletter ist RSS. ich habe sogar mal einen dienst benutzt, mit dem ich den tagesspiegel-checkpoint in einen RSS feed wandeln konnte. funktionierte dann allerdings irgendwann nicht mehr, wie fast alles um das man sich nicht selbst kümmert. um meine abonnierten RSS-feeds kümmere ich mich sehr intensiv. derzeit zählt mein miniflux 424 abonnierte feeds und 5298 ungelesene beiträge. ungelesene feed-items stressen mich nicht im geringsten. alle paar monate setz ich die einfach alle auf gelesen. RSS lese ich immer umgekehrt chronologisch. wichtiges schwimmt immer irgendwie nach oben oder erreicht mich auf anderen wegen.
andererseits glaube ich, dass nicht alle wie ich ticken. viele mögen podcasts, manche mögen newsletter. deshalb habe ich vor ein paar tagen angefangen mich nach diensten umzuschauen die RSS in e-mails umwandeln können. da gibt’s irgendwie nicht viele. ich dachte vielleicht kann steady sowas, aber leider pustekuchen. was selbstgehostetes wäre einerseits schön, andererseits ist email-versand etwas um das man sich doch sehr kümmern können muss und ein bisschen expertise mitbringen sollte. entgegen aller digitaler-unabhäng9gkeits-trends habe ich mich entschieden einen einfachen, automatisch generierten RSS-feed-newsletter mit hilfe des amerikanischen anbieters mailchimp zu bauen.
der werkzeugkasten von mailchimp erscheint mir auch in der kostenlosen version ziemlich gut. damit war es mir innerhalb von wenigen stunden möglich, eine ganz ok aussehnde version meines RSS feeds ins email-format umwandeln zu lassen. etwas besseres habe ich nicht gefunden, wem vergleichbare dienste bekannt sind: ich freue mich davon zu hören. jetzt geht erstmal mit mailchimp los.
täglich um 6 uhr morgens werden die, im vergleich zum vortag, neuen beiträge aus dem RSS feed dann per mail versendet. das tracking habe ich, soweit wie es in den einstellungen möglich war, deaktiviert, aber in den test-emails wurden weiterhin die links mit klick-trackern via us8.mailchimp.com verunstaltet.
eigentlich hatte ich als zielgruppe jemanden wie meine mutter für so einen newsletter im sinn. die liest seit einer weile wieder hier mit und eigentlich ist das auch die wurzel dieser seite. einerseits dient wirres.net mir dazu, dass ich mich an mein leben erinnere, andererseits habe ich damit angefangen ins internet zu schreiben, damit menschen die mir nahestehen die möglichkeit haben nachsehen zu können, was ich gerade so treibe oder denke.
irgendwann um die jahrtausendwende habe ich angefangen mit yahoo-groups regelmässig mails an freunde und bekannte zu versenden. dadrin stand schon damals eine wirre mischung aus blöden witzen, links und dingen die mir durch den kopf gingen. ein paar dieser mails habe ich archiviert. bitte nicht lesen!
irgendwann habe ich dann von push auf pull umgestellt. newsletter sind ja ein bischen pushy, wenn sie sich in die inbox drängen. RSS ist pull, man zieht sich das selbst in den leseapparat und kann das dann auch gut wegignorieren. aber wem’s gefällt, kann sich jetzt wieder einer push mechanik bedienen um wirres zu lesen: eepurl.com/jyHDZA
haha, sehe gerade: eigentlich sind nur 16 plätze frei. 500 emails darf ich mit dem kostenlosen mailchimp-tarif versenden. das sind ca. 16 × 31 mails. vielleicht mach ich nenn wöchentlichen newsletter draus? dreitägig? oder ich mach ne steady-seite auf um die 30 euro zu refinanzieren, die das nächst grösere paket bei mailchimp jostet? oder es interessiert sich ausser meiner mutter eh niemand für den newsletter?
ich weiss gar nicht genau warum, weil eigentlich ist es mir egal sachen richtig zu machen und wichtiger dinge so zu machen, wie sie mir gefallen. andererseits gibt es oft überschneidungen zwischen richtig und gefällt mir.
so gefällt es mir, wenn meine webseite in allen browsern und readern, die ich selbst gerne benutzte, gut aussieht. responsive design, also dass sich die webseite an die bildschirmgrösse anpasst, ist ja mittlerweile fast ein no-brainer. gelegentlich schaue ich mir meine website auch mit lynx an, einem textbasierten kommandozeilen-browser. damit sieht man dinge, die normale browser nicht zeigen, die aber trotzdem von manchen menschen oder maschinen, die die website besuchen, so gesehen werden kann. genauso gerne rufe ich meine webseite gelegentlich mit deaktiviertem css auf. beide, lynx und kein-css zeigen potenzielle probleme, die ich wegoptimieren oder aufschieben kann.
lynx browser zeigt wirres.net
chrome zeigt wirres.net ohne CSS
ansichten diese seite mit lynx und ohne css
weil ich selbst gerne und viele webseiten per RSS lese, prüfe ich auch regelmässig wie meine seite in RSS aussieht — und wenn mir was auffällt oder mich stört, optimiere ich es weg. neben diversen RSS-feeds, biete ich diese webseite auch sozusagen als html-feed an. das geht, weil ich das HTML mit microformaten (mf2) auszeichne. damit lässt sich diese seite als json parsen (beispiel) und sogar als html-feed abonnieren (vorschau)
mf2 feed preview von wirres.net
geparstes mf2 von wirres.net
ansichten dieser seite als html-feed und geparste microformate
all diese ansichten, in lynx, ohne css, als geparste oder gerenderte mf2-microformate oder als RSS-feed, sind ansichten dieser website, wie sie auch maschinen sehen, suchmaschinen- oder KI-crawler, der rivva-bot oder andere aggregatoren. auch screenreader sehen die website eher in diesen minimalversionen, weshalb ich auch ein interesse daran habe, dass wirres.net in diesen ansichten ganz okay aussieht, bzw. mir gefällt.
das schöne an den eingebauten mf2-microformaten ist auch, dass man mit geeigneten readern auch meinen favoriten- oder bookmarks-strom abonnieren könnte, obwohl ich dafür noch kein RSS gebaut habe.
ich bemühe mich natürlich auch um gute maschinenlesbarkeit damit sich meine webseite gut mit google versteht. nach meiner blogpause und ein paar monaten offline-zeit wegen technischer probleme, verlor ich alle sympathien die mir google vormals gewährt hatte. noch nicht mal eine suche nach meinem namen zeigte meine heimstätte im netz (wirres.net) mehr auf den ersten 10 suchergebnisseiten an. nachdem ich es hier wieder schön für google und andere maschinen gemacht habe, schickt mir google auch gelegentlich wieder besucher vorbei. derzeit zwar nur für eine seite (erfreulich und erschütternd), aber dafür im januar so um die 1000.
google search konsole „statistik“
matomo statistik der letzten 12 monate (pageviews und visitors)
google glaubt diese website hat ein gutes spitzkohl-rezept
irgendwann vor ein paar monaten gefiel mir die idee, dass ich bilder hier so unter einer cc lizenz veröffentlichen könnte, so dass suchmaschinen sie auch mit dieser lizenz erkennen. bei flickr klappt das super, wenn man dort für seine fotos eine cc-lizenz gewählt hat. weil ich das auch wollte, aber natürlich auch weil ich die idee der reibungslosen maschinenlesbarkeit gut finde, habe ich angefangen für alle artikel json-ld mit auszuliefern. damit liefere ich zwar auch nicht viel mehr metadaten als mit den microformaten aus, aber unter anderem kann man eben auch bilder explizit mit lizenzen versehen.
das klappt einerseit auch ganz gut, andererseits vergisst google einmal indexierten und erkannten lizenzen aber auch immer wieder. irgendwie schaffe ich es nicht, mit mehr als 50 bilder von dieser website mit cc lizenz in den suchergebnisseiten unterzubringen.
was mit json-ld allerdings super klappt ist die maschinenlesbatre auszeichnung von rezepten. so ausgezeichnete rezepte nimmt google mit kusshand und rezepte die im karussel oben in den suchergebnissen angezeigt werden sind auch der grund, warum google mir im moment so viele besucher schickt. zum ersten mal mit maschinenlesbaren rezeptdaten experimentiert hab ich vor 14 jahren. mittlerweile klappt das wirklich gut.
„spitzkohl airfryer“ suchergebnisseite
„schnelle gurkensticks“ suchergebnisseite
„gurkensalat tim mälzers oma“ suchergebnisseite
suchworte bei denen rezepte von dieser webseite ziemlich weit oben stehen
was ich aber eigentlich sagen will: diese ganzen optimierungen, die ich auch gerne als experimente ansehe um suchmaschinen- und technik-gedöns besser zu verstehen, haben vor allem den effekt, dass ich kleine, subtile, aber auch grobe fehler aud wirres.net finde, die ich sonst nie gefunden hätte oder die mir egal gewesen wären.
vor ein paar monaten habe ich sehr viel energie darein gesteckt in den PageSpeed Insights gute punktzahlen zu bekommen. dabei habe ich viele anpassungen am server vorgenommen, die html-struktur, lazy und eager-loading und die bildgrössen optimiert. mit der startseite ist google nicht immer 100% zufrieden, aber die einzelseiten schrammen in der regel an den 100%.
page speed test
page speed test
page speed test
gleichzeitig habe die speed-optimierungen wieder zu fehlern an anderen ecken geführt, die ich dann nach und nach wieder wegoptimiere. so ergibt sich im prinzip ein manischer kreislauf von immer neuen optimierungen. mach ich aber gerne, vor allem weil: ist ja alles meins hier.
tools die ich gerne zum rumoptimieren nutze:
ich lebe seit ewigkeiten sozusagen in meinem RSS-reader. neuigkeiten jeder art erfahre ich aus meinen > 419 abonnierten feeds. der einzige algorithmus dem ich in meinem RSS-reader begegne ist der, der nach datum sortiert.
es gibt wenige ausnahmen zu dieser regel: eine ist spiegel.de, dessen startseite ich täglich einmal aufrufe und „durcharbeite“ und eine andere ist youtube.com, dessen algorithmus mir meiner meinung nach eine gute und passende auswahl präsentiert. alle paar tage rufe ich heise.de auf. und neuerdings gehe ich ein- bis drei-täglich auf konstantins reader.konnexus.net. die feeds die dort angezeigt werden habe ich zwar auch zum grösstenteil abonniert, aber so komme ich dann bei der einen oder anderen quelle auch mal auf der webseite vorbei, statt nur die feedansicht zu sehen.
konstantins reader hilft mir auch kurzfristig eventuelle probleme mit meinem feed zu erkennen. wenn man die ganze zeit an seinem kirby rumspielt, geht ja auch mal was kaputt. natürlich habe ich meine feeds auch selbst abonniert um gegebenenfalls fehler oder probleme zu erkennen. ich hab jetzt auch mein feedly-konto reaktiviert (in der kostenlosen variante), um auch dort zu prüfen, ob alles in ordnung mit meinen feeds ist.
und da fiel mir gestern und heute leider auf, dass die neuen templates, die ich rund um mein neues favoriten und bookmark system gebaut habe, noch nicht für die RSS ausgabe optimiert waren.
kaputter youtube embed in feedly.com
eigentlich gebe ich youtube-embeds, bilder, videos, mastodon- und bluesky-embeds im RSS-feed mit vereinfachten templates aus. im screenshot sieht man, dass hier ein youtube-embed mit dem frontend-code ausgeliefert wurde. im frontend gibt’s den embed-code erst nach einem (javascript-) klick auf ein lokales vorschaubild. per RSS liefere ich den (youtube) nativen embed-code aus, weil javascript-gedöns im RSS-feed nicht zuverlässig funktioniert und von verantwortungsvollen feed-readern ausgefiltert wird.
jedenfalls sollte das jetzt wieder so funktionieren wie gedacht. die neuen templates beachten jetzt alle die vorgabe im RSS vereinfachten code auszugeben. entschuldigung für die suboptimalen RSS-lieferungen in den letzten tagen.
während ich da so bei feedly rumklickte, fiel mir auf, dass meine alte feed-adresse (wirres.net/index.xml), die weiterhin funktioniert, bzw. auf die neue feed-adresse (wirres.net/feed/) weiterleitet, laut feedly diese eigenschaften hat:
2K followers? das wollte ich einerseits nicht glauben und dachte andererseits, dass feedly dann ja wohl eine ziemlich grosse anzahl schlummernder, also ungenutzer konten haben muss. ich hatte mein feedly konto auch 3 bis 4 jahre nicht genutzt, bzw. eigentlich ohnehin nur für testzwecke angelegt. aber meine neugier war geweckt und weil gemini mir sagte, dass feedly die genaue anzahl der subscriber beim abholen des feeds nennt, aktivierte ich heute nacht meine apache access logs (die sind normalerweise deaktiviert) — und siehe da:
diese zahl widerspricht allerdings meinen eigenen messung. seit ca. 30 tagen habe ich meinen feeds einen matomo-image-tracker hinzugefügt (matomo anonymisiert die letzten zwei bytes der IP-adresse) und matomo zählt eher so um die 300 RSS-feed lesende (unique visitors pro tag).
da meine matomo-instanz (stats.wirres.net) auf einschlägigen werbeblocker-listen steht, gehe ich davon aus, dass mindestens ein drittel der aufrufe ungetrackt sind. das wären dann so um die 400 aktive rss-abos — und würde bedeuten dass feedly mindestens 2000 schlafende/ungenutzte wirres.net abos hat. (feedly reicht den image tracker durch, filtert den nicht aus.)
auffällig beim RSS-feed tracking war übrigens, dass der artikel darmspiegelung per RSS überdurchschnittlich oft gelesen wurde. oder umgekehrt dürfte das ein zeichen dafür sein, dass viele lesende die artikelvorschau meiner artikel gar nicht anklicken, ausser es interessiert sie. und darmspiegelung scheint ein guter interesse-trigger zu sein.
tl;dr: ich gebe mir mühe meine rss-feeds zu optimieren, das gelingt mir nicht immer. pro tag zähle ich derzeit laut matomo bis zu 250 einzelne besucher auf der webseite und 300-400 einzelne leser per RSS.

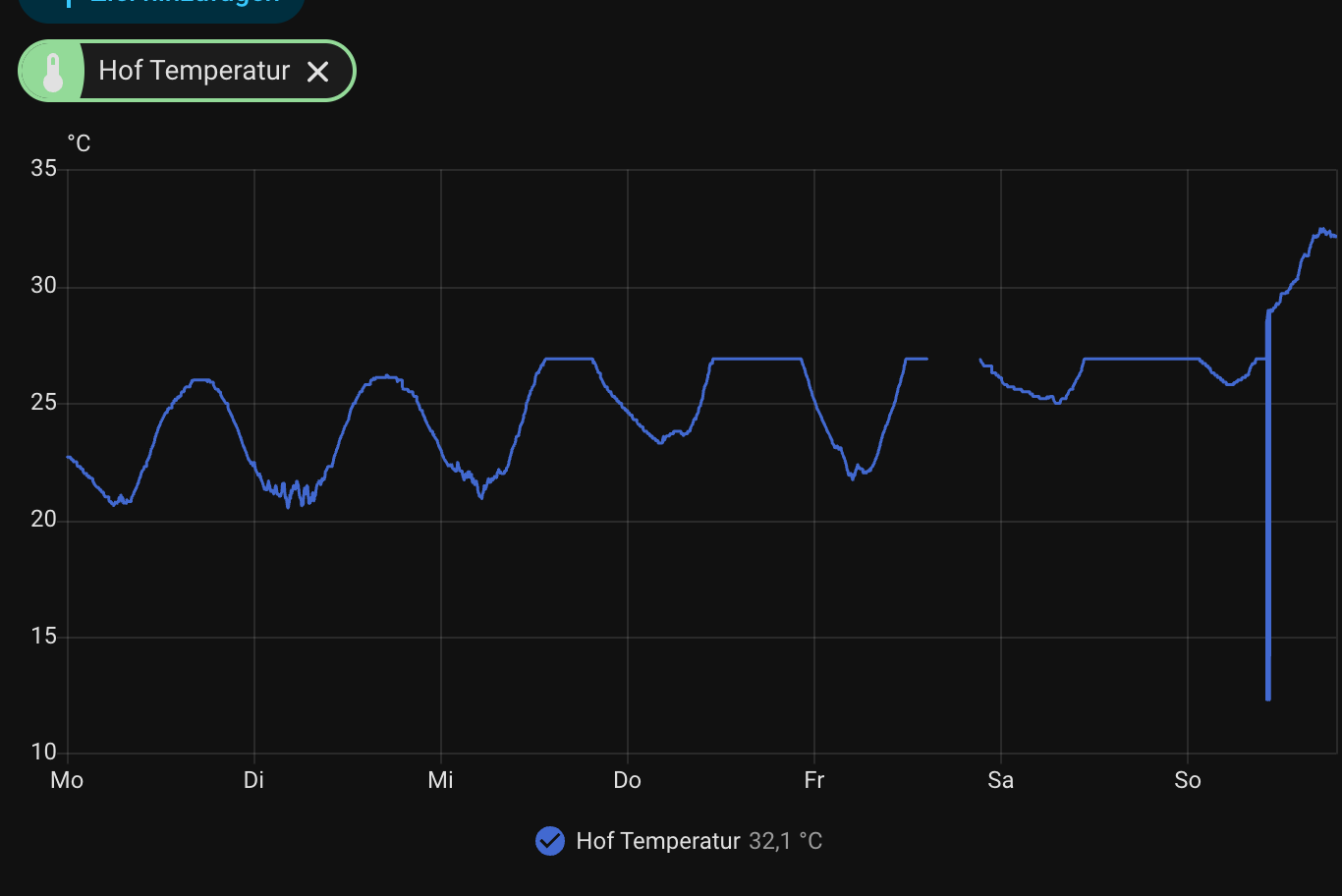





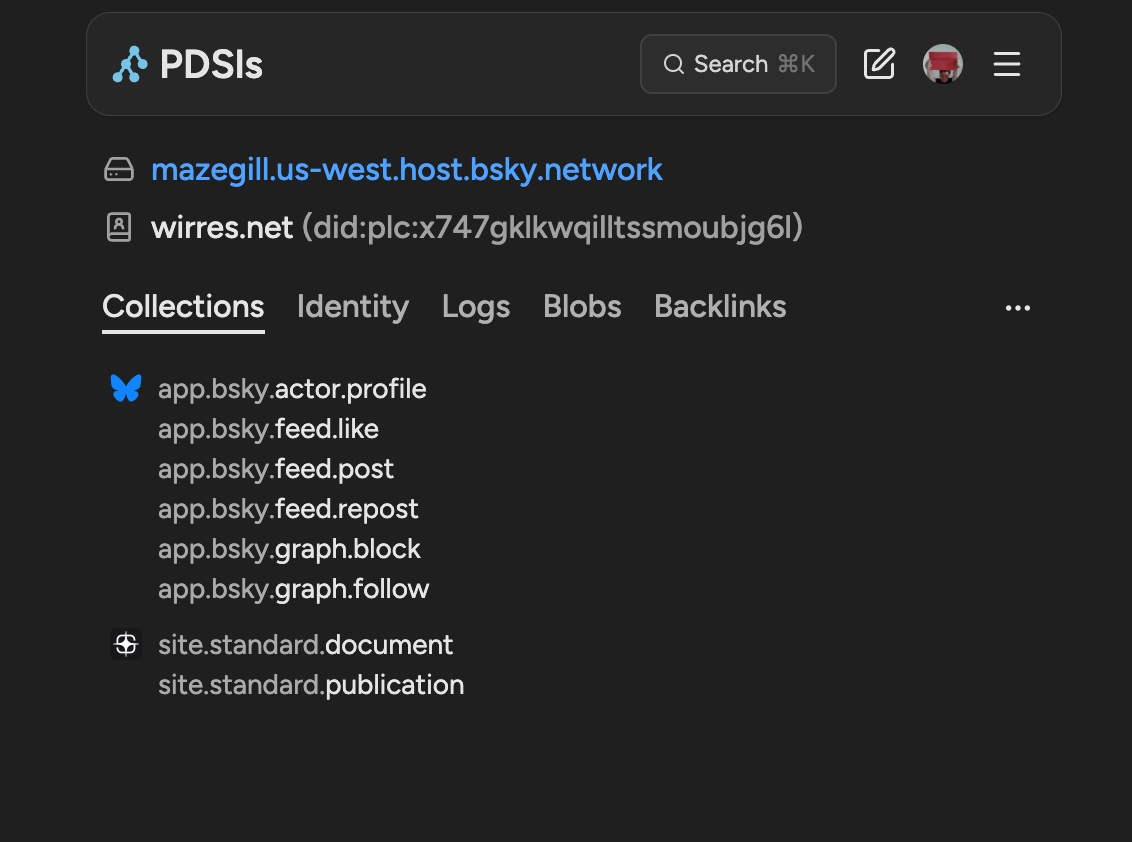



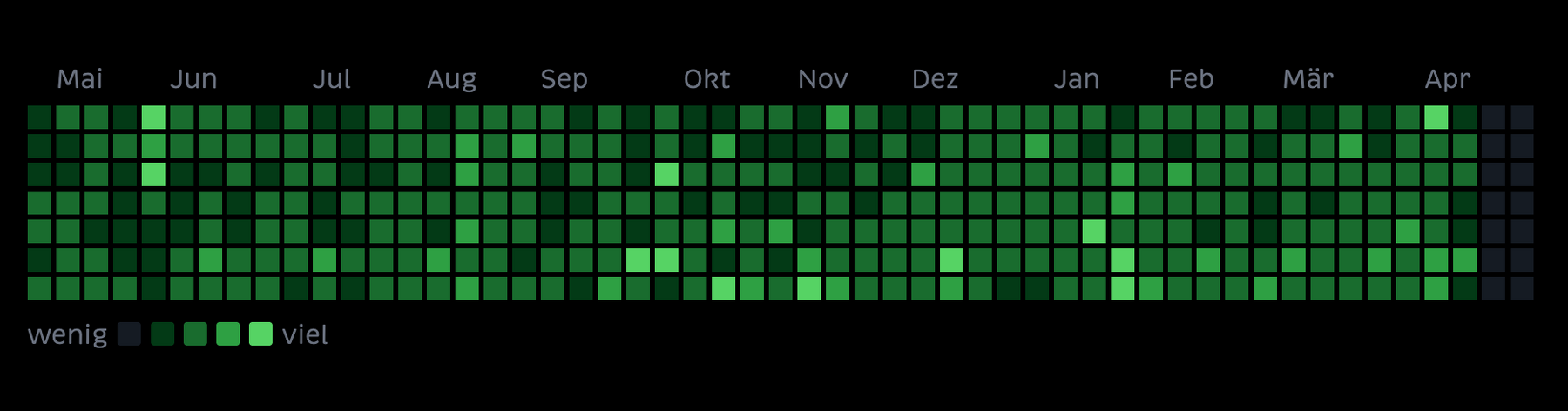



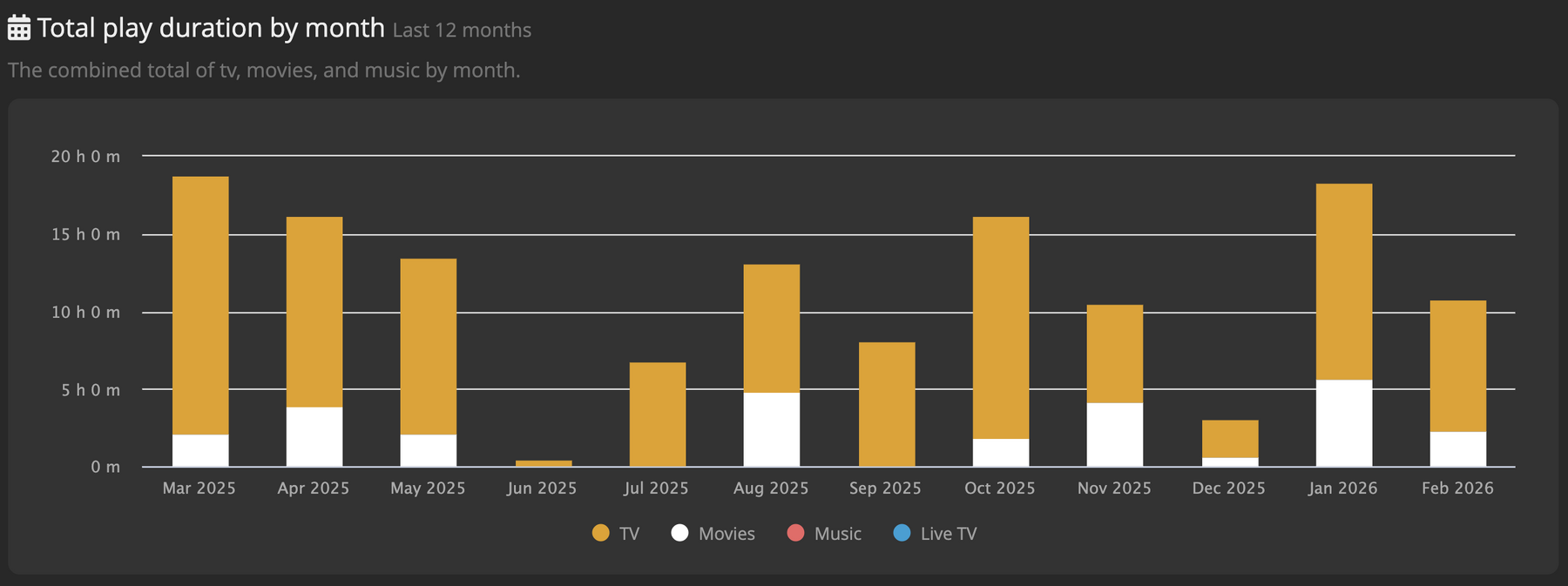
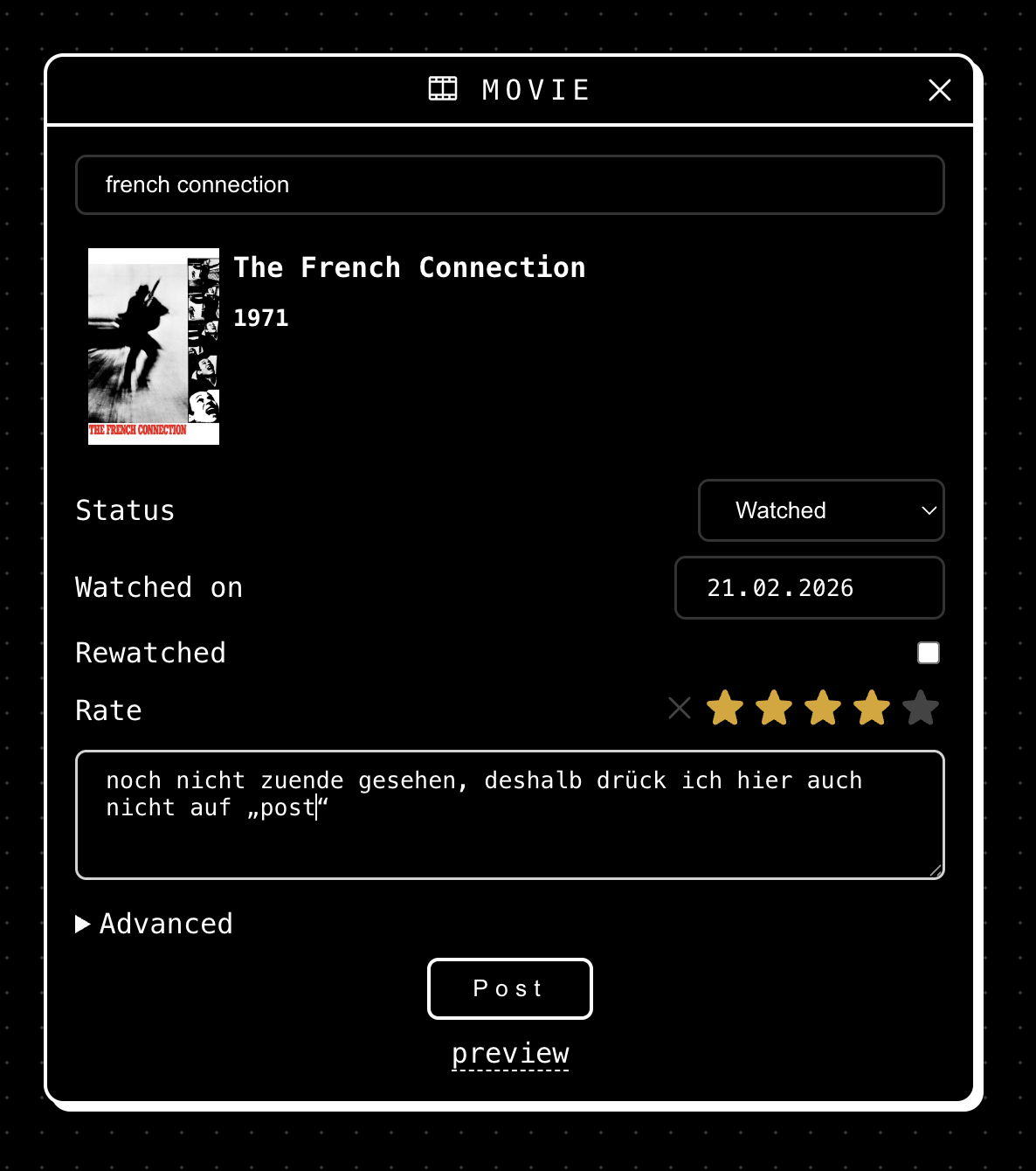
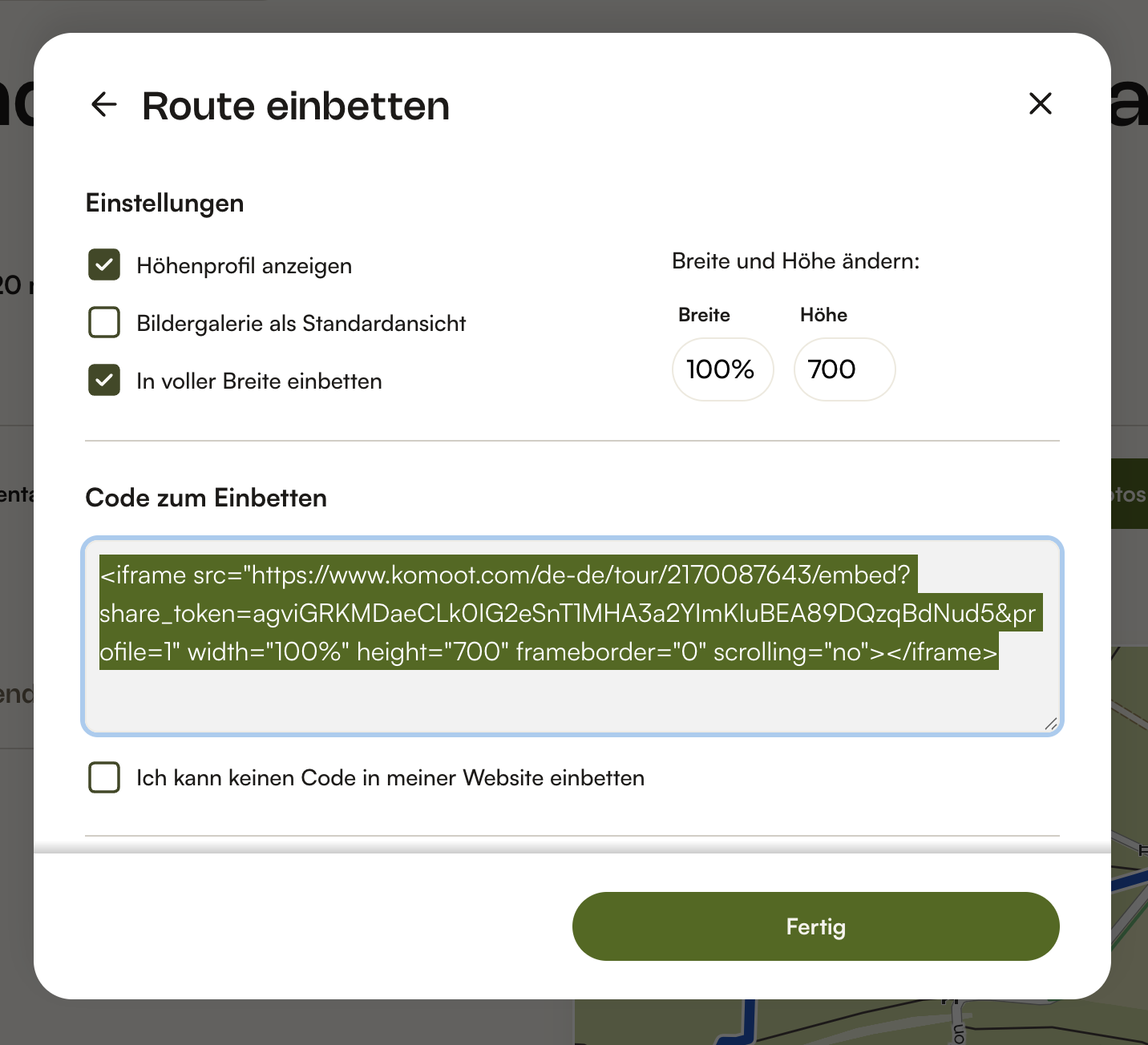


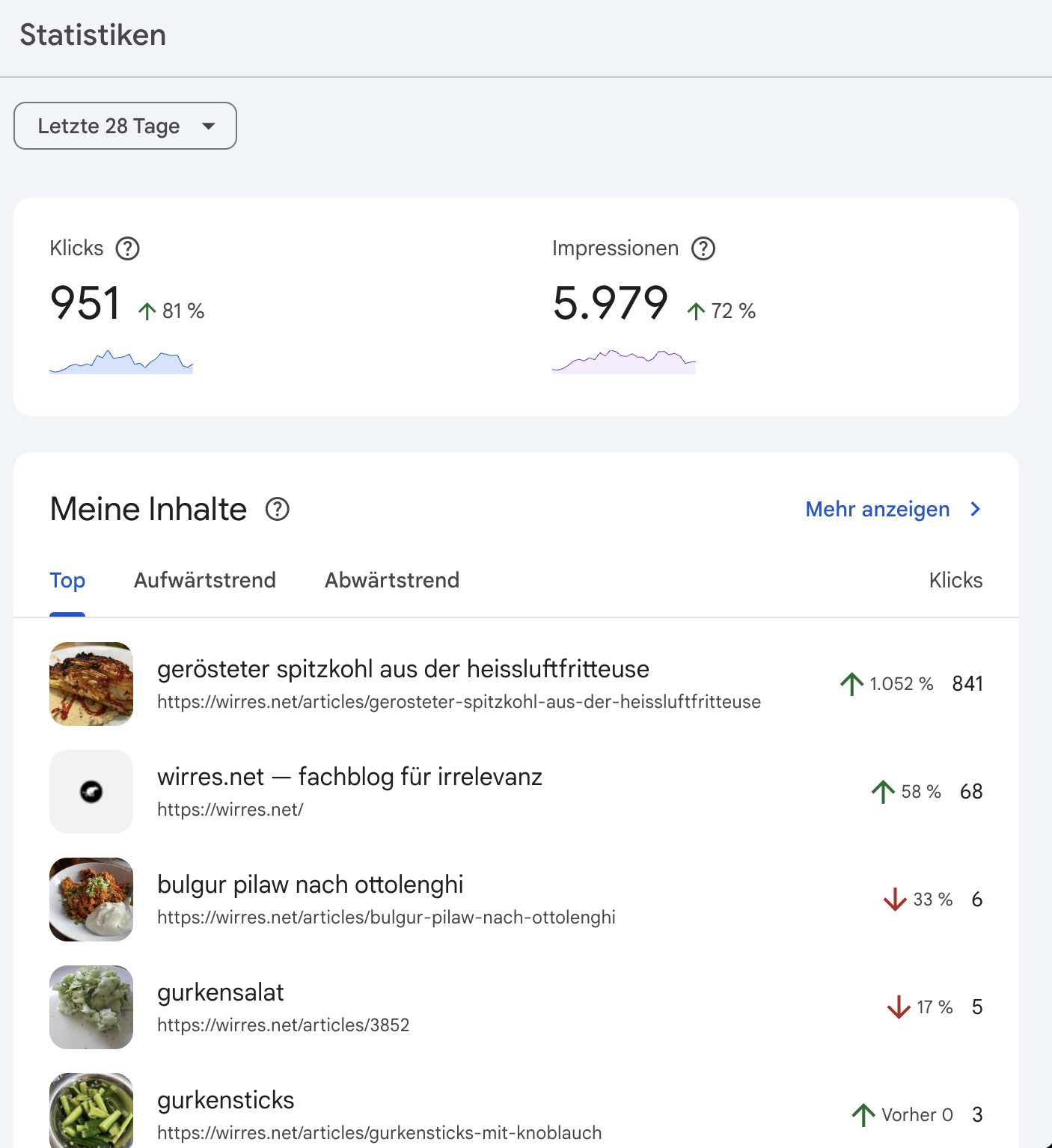
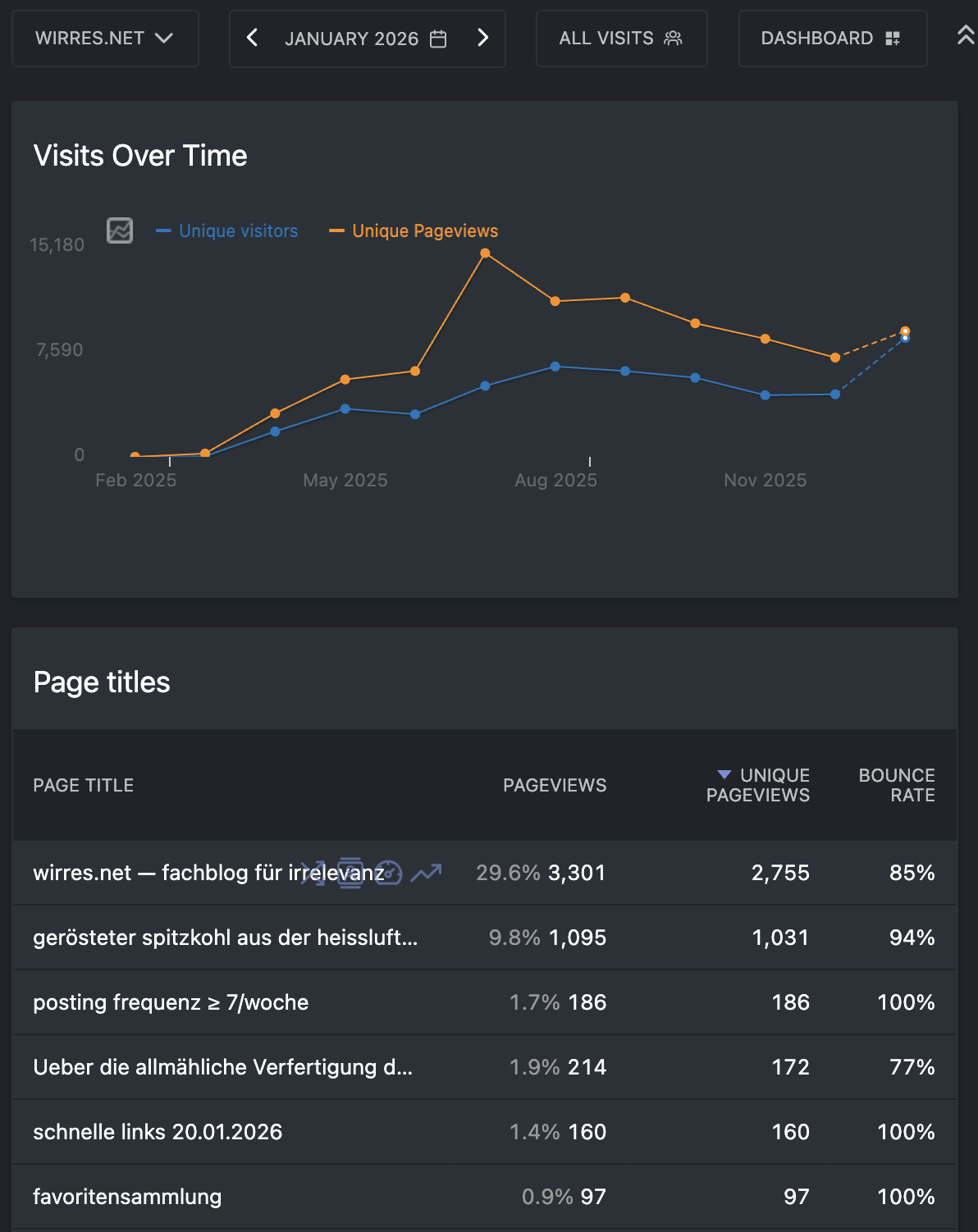
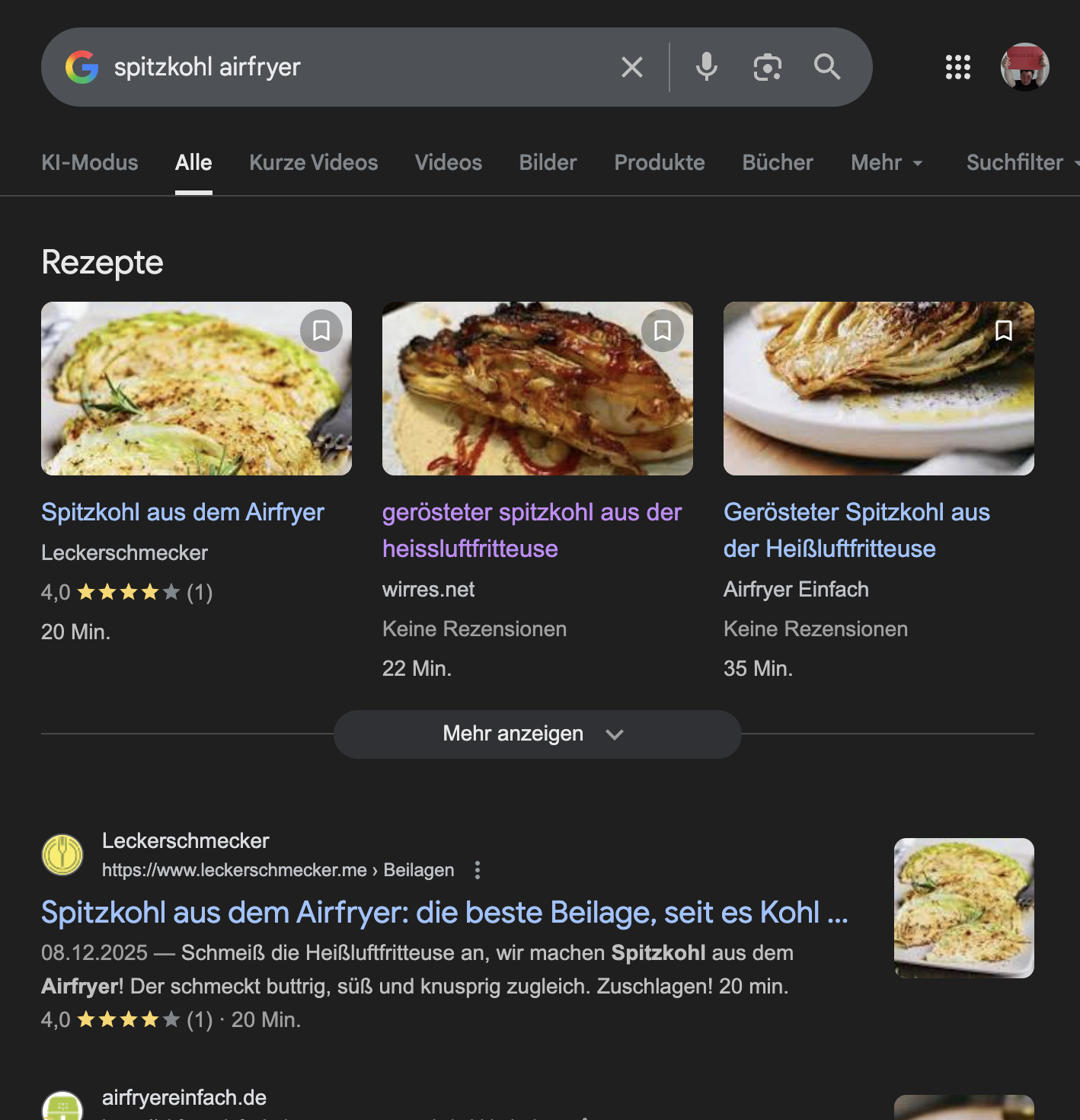
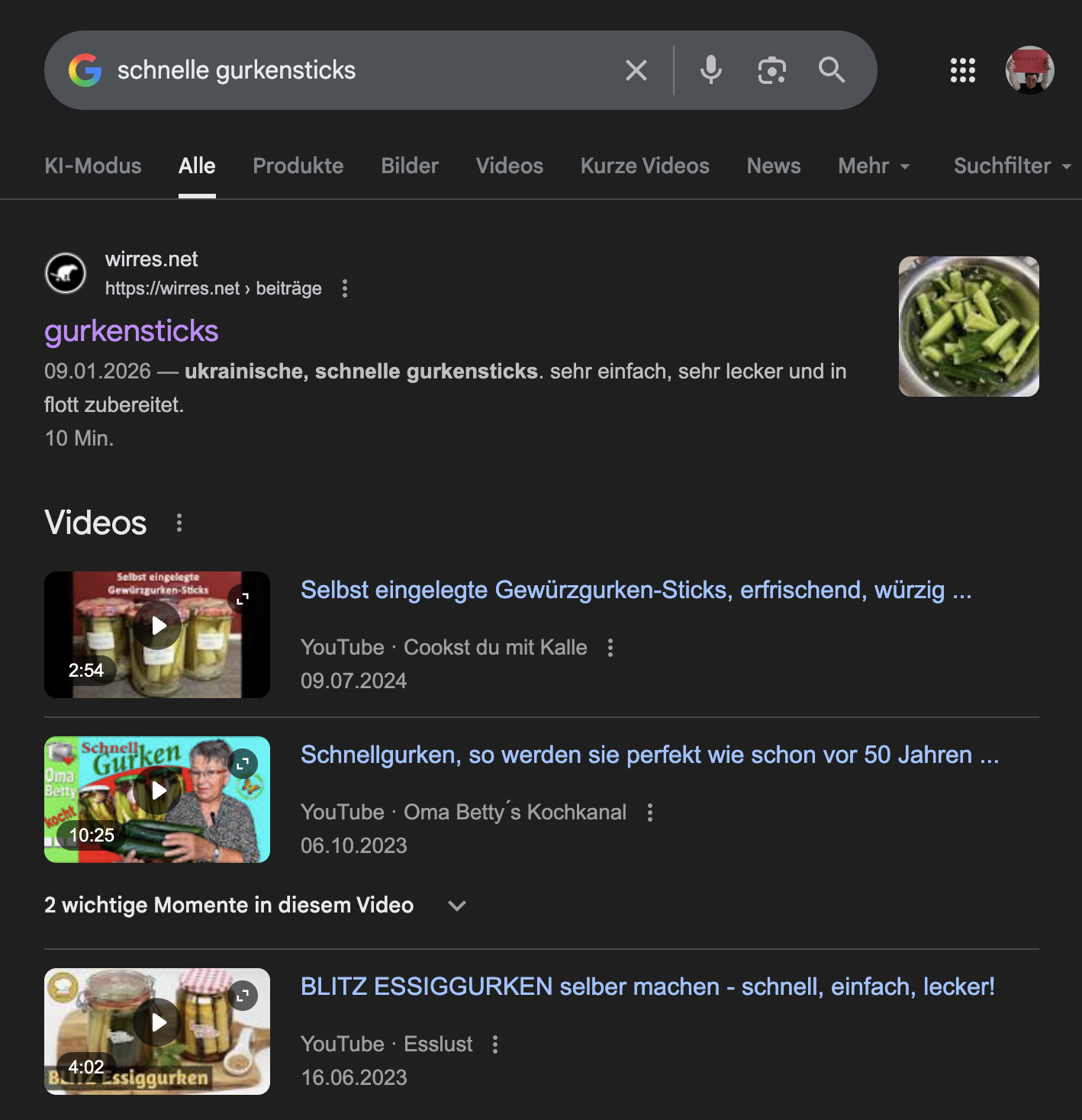
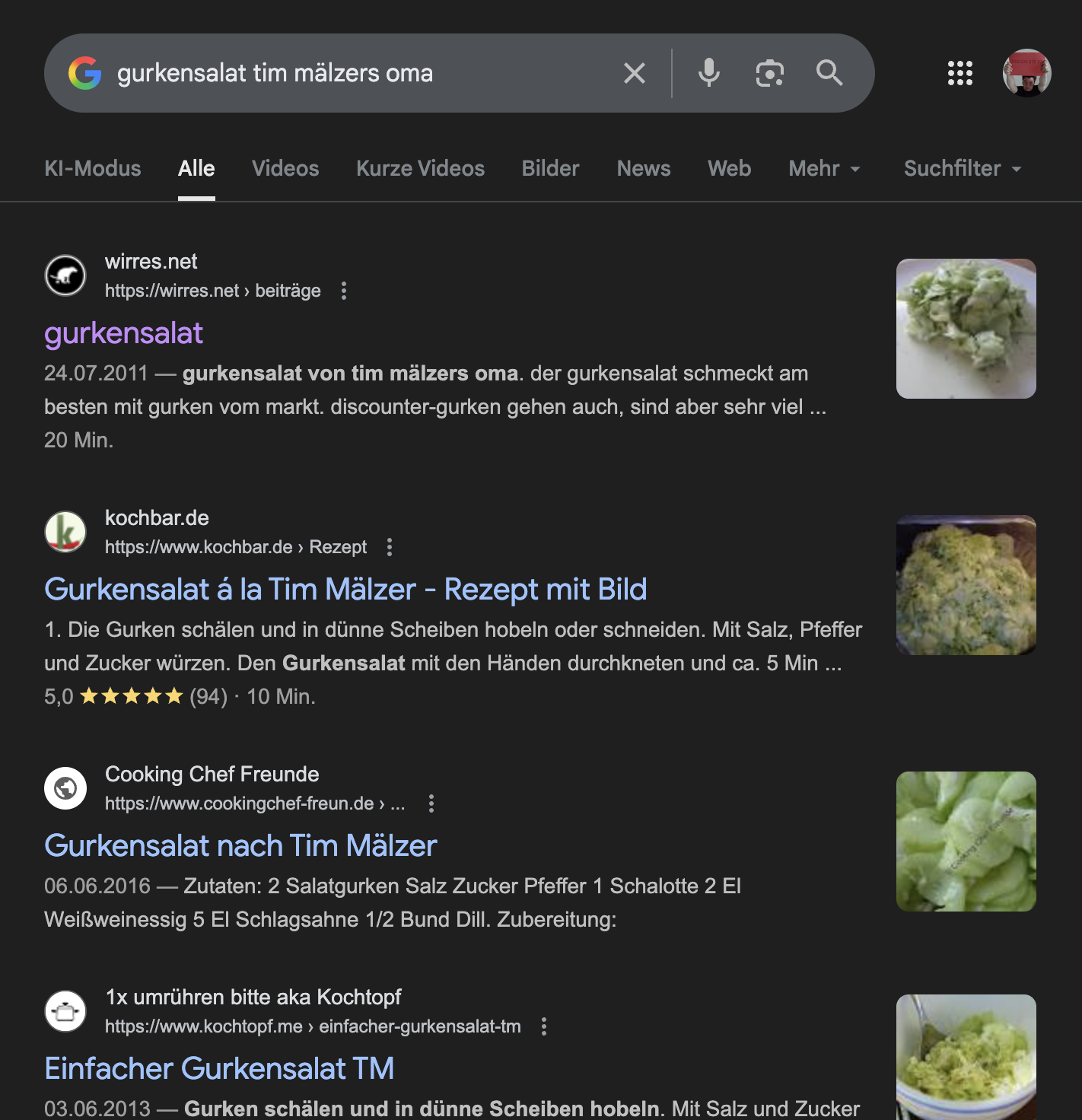
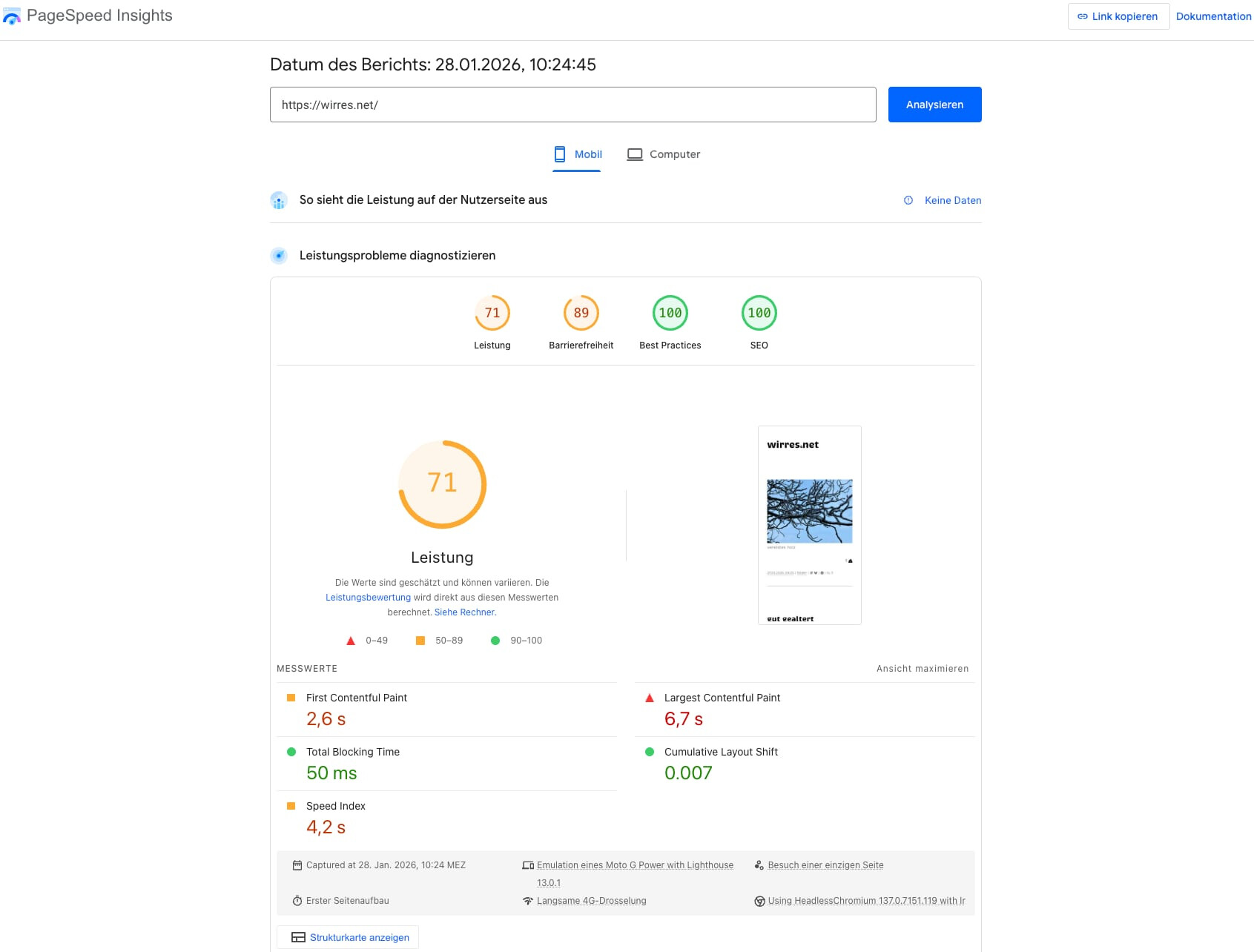
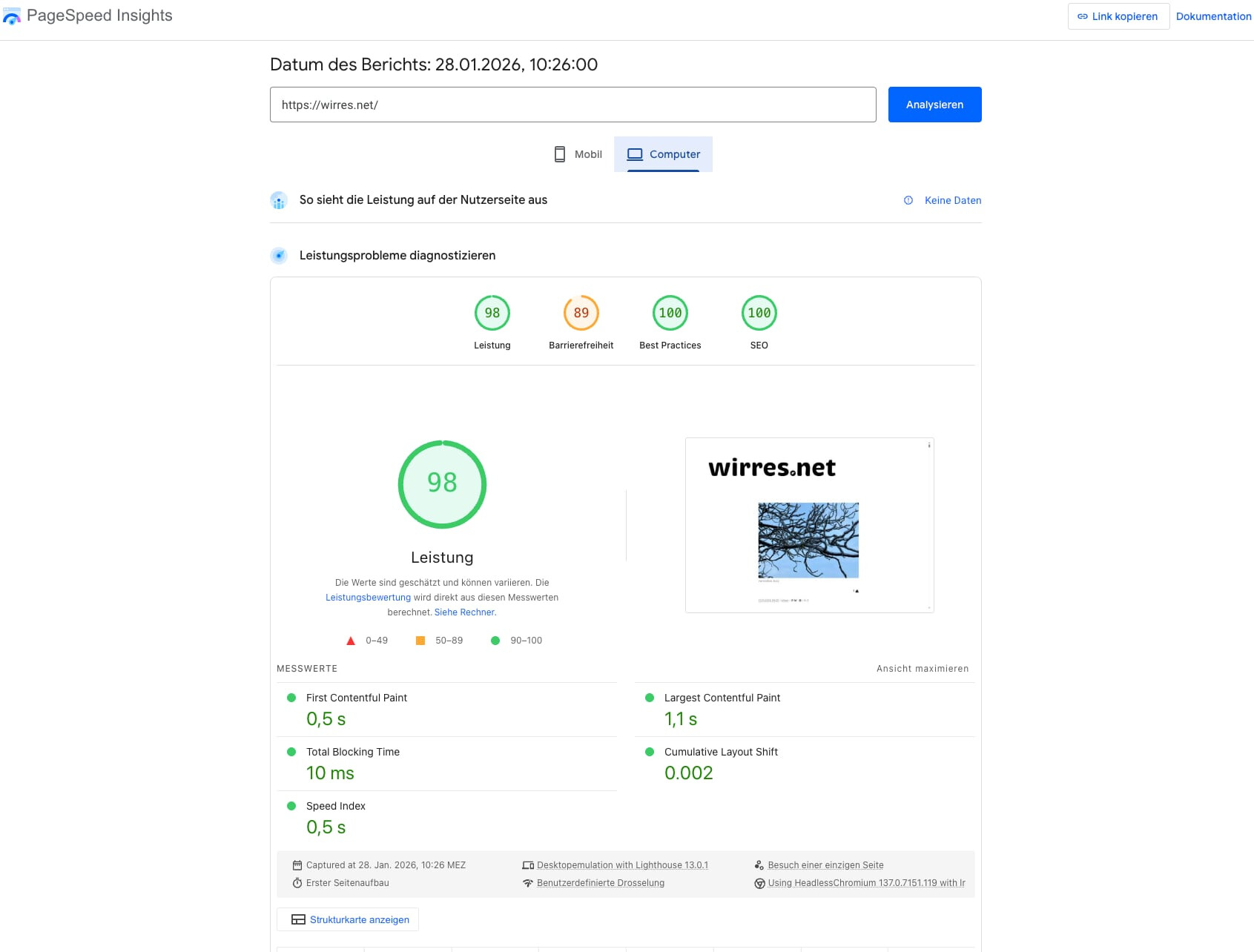
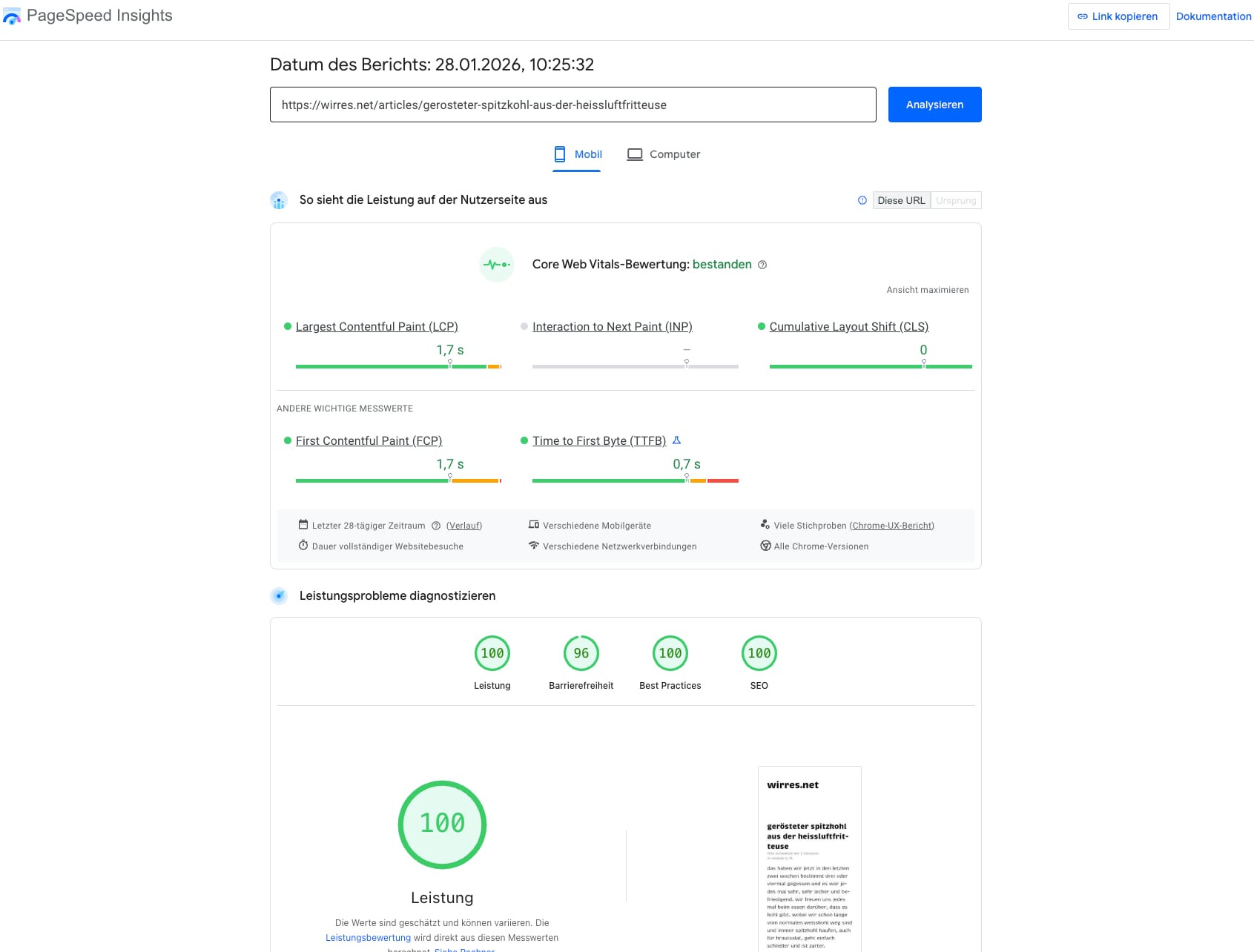
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}