gestern gelernt: manchmal ist es besser die doku selbst zu lesen, als sie sich von chatgpt erklären zu lassen. RTFM hat in zeiten von LLMs noch seine berechtigung.
lange version
instagram hab ich in letzter zeit kaum noch genutzt. aber eigentlich benutze ich instagram gerne.
vor ein paar jahren hab ich dort gepostet und meine beiträge mit einem script (ownyourgram) ins blog gezogen. das geht nicht mehr, seit instagram seine API verrammelt hat.
instagram scrapen ist schwierig, aber mit instaloader geht’s offenbar ganz gut.
mit chatgp hab ich es allerdings nicht zum laufen bringen können. was half: die doku selbst lesen und das dort gezeigte session script benutzen.
jetzt habe ich ein archiv all meiner instagram-posts seit dem oktober 2011. damit könnte ich mir mit kirby recht schnell einen instagram archiv-viewer bauen oder wieder anfangen bilder auf instagram zu posten, ins blog zu ziehen und auf mastodon und bluesky cross zu posten.
wenn ich wie jetzt zugriff auf die daten habe, kann ich also auch wieder anfangen instagram zu benutzen.
als ich wirres.net vor drei monaten wiederbelebt habe, wollte ich es ohne besucherzähler versuchen. ich glaube ich habe das gerade mal eine woche ausgehalten und dann matomo, was ohnehin noch lief, wieder eingebunden. weil man das auch ohne cookies machen kann, fühle ich mich trotz zählscript auf der datensparsamen seite.
meine rationalisierung der besucherstatistik ist, dass ich gerne sehe woher die leute kommen und dass ich gelegentlich interessantes aus den referern herausfische. interssant ist es auf jeden fall zu sehen, dass buddenbohm-und-soehne.de mir den ganzen monat über besucher herüberspült (128 „visits“ im juni), obwohl der letzte explizite link auch schon wieder zweieinhalb monate her ist (die blogrolle, ich weiss). oder ein ein link von herrpaul.me (99 visits im juni). 69 von rivva.
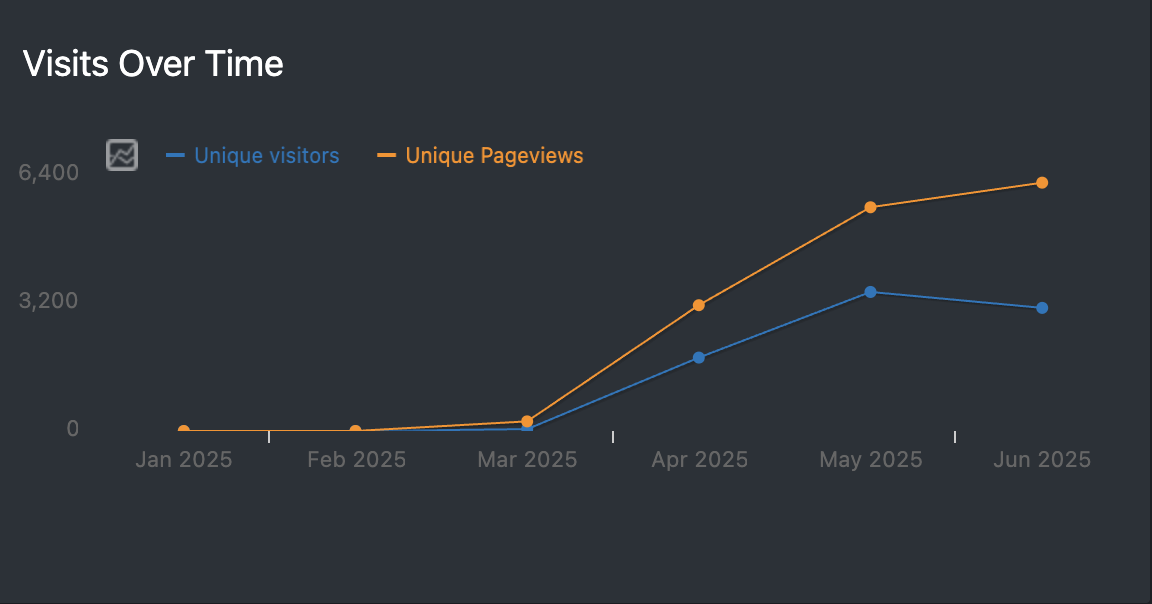
matomo grafik: besucher über die zeit
man sieht jedenfalls es geht aufwärts, die unique pageviews sind im juni dann auf ca. 6200 geklettert. damit befinde ich mich auf schockwellenreiter-niveau, der diesen monat auch ca. 6200 seitenaufrufe gemeldet hat. die top 5 artikel in sachen seitenaufrufe im juni waren:
suchmaschinen-verkehr ist sehr, sehr mau, weder von google noch anderen gab es viel linkliebe. das war vor 5 jahren noch anders und ich bin vorsichtig pessimistisch und glaube das bleibt jetzt erst mal ein paar jahre so.
ich fand es interessant, wie er eine permalink-url seines notiz.blogs kopierte und in einem mastodon-client ins suchfeld kopierte. damit fand er den beitrag, der dank seines wordpress acivity-pub-plugins dann als likable und sharable eintrag in seinem mastodon client auftauchte.
(hört sich kompliziert an und ist es irgendwie auch, wie alles im fediverse. ich lass mir das jetzt seit wochen von chatgpt und wohlgesonnenen lesen erklären und kapier nach wie vor nur die hälfte und behersch die terminolie nach wie vor nicht.)
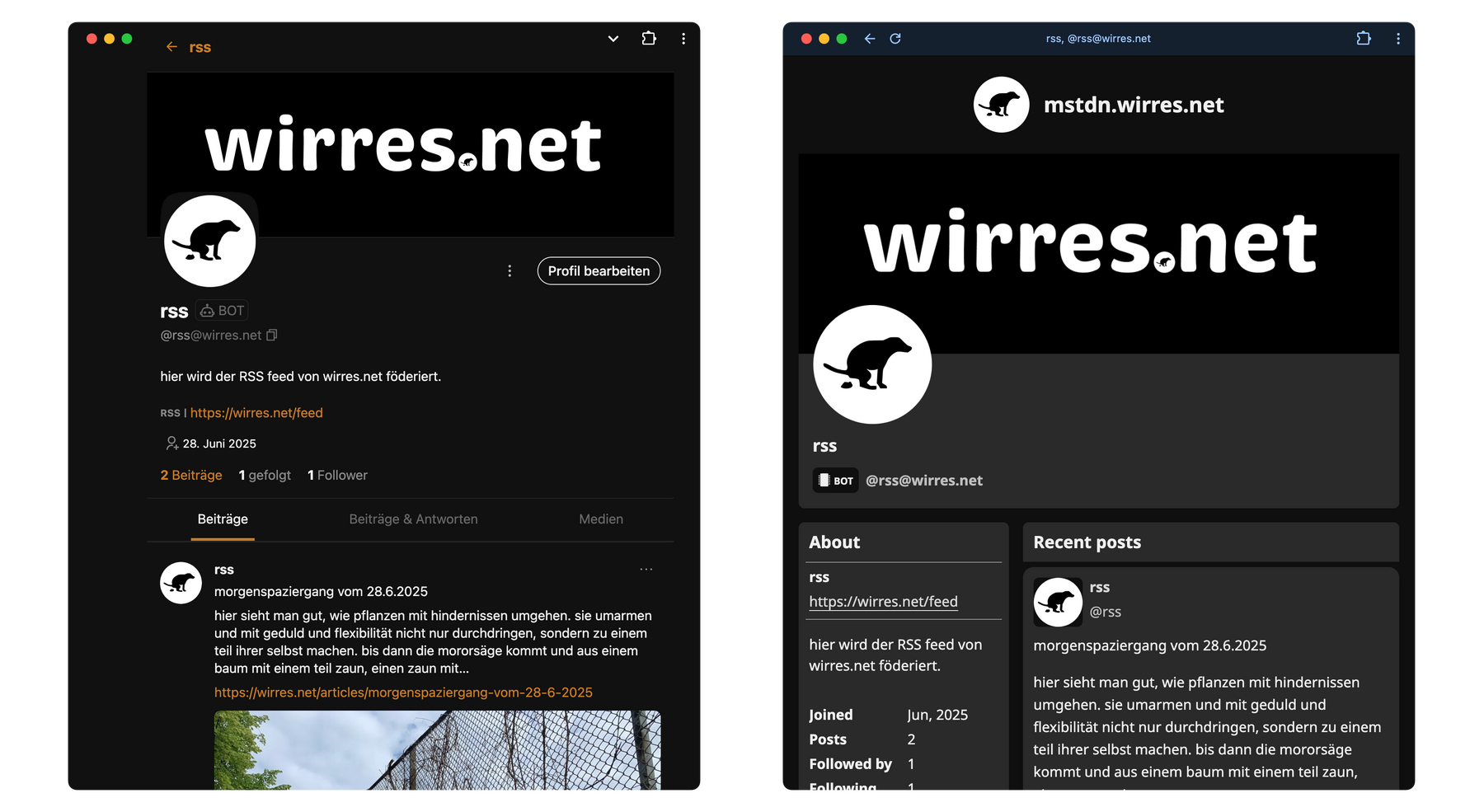
weil wirres.net kein teil des fediverse ist, klappt das bei mir natürlich nicht. aber ich dachte, wenn ich einen RSS-account auf meinem gotosocial-dings anlege auf dem einfach automatisch alle neuen einträge auftauchen, könnte das doch auch gehen. es zeigt sich (auf den ersten blick), dass das nicht geht, aber daüfr gibt’s jetzt einen bot der mein rss ins fediverse pumpt.
denkt man ja nicht, aber alles was ich in mein gotosocial/mastodon-konto @ix@wirres.net schreibe ist handgeschnitzt. aber @rss@wirres.net ist ein bot.
ansonsten war ich ein bisschen überrascht von matthias pfefferles demo. als er einen beitrag seines notiz.blogs in mastodon favte, meinte er, dass er damit seien worpress instanz „abschiessen“ würde. dieses fediverse geschnatter scheint eine menge last und verkehr zu erzeugen. ich habe mir dann kurz sorgen gemacht, ob dieses gotosocial so eine gute idee war oder ist, aber soweit ich sehe scheint das nicht all zu sehr ins schwitzen zu geraten.
das script, dass aus RSS-items einen eintrag auf gotosocial macht hat chatgpt geschrieben. es brauchte aber zwei stunden debugging zusammenarbeit mit mir, bis das fehlerfrei lief. ich will nicht klagen, aber heute hat es sich schon ziemlich doof angestellt.
ich wollte folgende features haben, die das script jetzt auch, soweit ich sehe, erfüllt.
prüfe alle 5 minuten meinen rss feed
wenn es einen neuen beitrag gibt baue einen beitrag aus der überschrift, kürze den text auf 280 zeichen, behalte aber ein paar formatierungen in markdown bei, füge einen link und das erste bild hinzu (wenn das bild grösser als 500px ist)
poste nur einen beitrag je aufruf des scripts
merke dir die geposteten einträge
ansonsten hab ich eigentlich nur ein bisschen am css des gotosocial themes gefummelt. so richtig toll finde ich das nach wie vor nicht, vor allem seitdem ich elk.zone als mastodon client nutze und da wirklich (im browser) alles sehr geschliffen aussieht.
screenshots der mastodon webclients elk.zone (links) und gotosocial (rechts)
erstaunlich einfach war die installation von gotosocial auf einem asteroiden (doku). besonders gefällt mir, dass gotosocial mein hauptproblem mit mastodon löst: das domain-gedöns.
schliesslich nutze ich als blogadresse eben gerade nicht wirres.wordpress.com oder wirres.blogger.de, sondern eben wirres.net. ich benutze emailadressen wie ix@wirres.net oder felix@schwenzel.de. was jeweils dahinter läuft, ist meine entscheidung, hinter wirres.net kann ezpublish stecken, kirby oder wenn mir irgendwann mal danach ist — wordpress. hinter ix@wirres.net steckt derzeit (noch) gmail, hinter felix@schwenzel.de ein uberspace mailserver.
und jetzt kann ich für föderiertes posten von mini-beiträgen eben @ix@wirres.net benutzen — und derzeit steckt da eben gotosocial hinter, das zwar auf einer subdonain läuft, aber fein.
und wie zu erwarten, waren die folge-arbeiten der umstellung auf gotosocial um ein mehrfaches umfangreicher als die installation. einerseits hab ich den umzug noch nicht abgeschlossen, beide handles @ix@mastdn.io und @ix@wirres.net laufen noch paralell, auch wenn ich mstdn.io nicht mehr zum posten (aber schon zum reposten) nutze. es besteht ja keine eile mit dem umzug (der follower und der anschliessenden umschaltung auf nur-lesezugriff von @ix@mstdn.io). (nachtrag 7:20: umzug abgeschlossen.)
ausserdem musste ich viel von den routinen mit denen wirres.net mit mastodon interagiert anpassen. einerseits hab ich mir etwas gebaut, um toots hier einbetten zu können.
und ich sende mit maurice renksindieconnector beiträge, fotos automatisch von wirres.net auf meine mastodon instanz und hole umgekehrt reaktionen wieder bei mastodon ab, um sie auf der artikel-beilage zu aufzulisten.
es zeigt sich, gotosocial verhält sich da doch ein klein wenig anders als mastodon. abfragen von beiträgen per api …
GET https://<deine-Instanz-Domain>/api/v1/statuses/:id
… rückt gotosocial nur mit authentifizierung raus, mastodon auch ohne.
beim bildupload ist gotosocial sehr streng und funktionierte nicht auf anhieb mit dem indieconnector. bei api-abfragen besteht gotosocial ausserdem auf einem mitgelieferten „user agent“. das musste alles in kirby angepast werden.
bridgy, das gelegentlich reaktionen aus sozialen netzwerken zuliefert, musste auch auf die neue mastodon-instanz kennenlernen und zickte zunächst ein bisschen mit dem authentifizierungs-workflow.
aber insgesamt fühlt sich das alles wie eine richtige und gute entscheidung an.
caching
zwischendurch gemerkt, dass auch die suche statisch gecached wurde. das funktioniert natürlich nicht. also eine ausnahme definiert:
seit ich wieder blogge kümmere ich mich kaum noch aktiv um die heimautomatisierung. mein hobby, die fummelei, widme ich zur zeit komplett kirby und dem web. es zeigt sich aber: die automatische wohnung läuft mittlerweile auch ohne aufsicht ganz gut vor sich hin. eine uptime (ohne restart) von > 30 tagen steckt das system gut weg, gelegentlich muss ich mal eine kleinigkeit anpassen, aber das steht meistens unter dem motto der regeln nummer eins und zwei der heimautomatisierung:
automatisiere alles was du mehr als dreimal wiederholst und dich nervt — um es dann zu vergessen.
wenn etwas öfter als dreimal nicht funktioniert, passe die automatisierung an — um es dann zu vergessen.
konkret waren das der gardinenschalter der die automatisierung doppelt auslöste und die hitze die mich wiederholt nervte. also schnell die automatiserung angepasst und den ventilator wieder aktiviert (was ein zwei arbeitsschritte im homeassistant dashboard erfordert). ach ja, die optimierung der lichtsituation von gästen die im wohnzimmer übernachten hab ich aufgeschoben und an zwei abenden einfach manuell übers dashboard gemacht, statt es zu automatisieren.
ich habe mich antschieden, entgegen der ersten anküpndigung gelegentlich changelogs auch im hauptfeed und auf der hauptseite zu veröffentlichen wenn mir danach ist. und mit diesem chagelog war mir danach.
[nachtrag] habe eben den umzugsbutton auf https://mstdn.io/@ix gedrückt und bin da jetzt weg.
alte beiträge (beispiel) liegen weiterhin dort, inklusive aller likes und reposts, aber auch hier (beispiel).
meine follwoerzahl dort war vorher so um die 1030, jetzt sind es nach dem umzug 980. das sind offenbar weniger tote konten, als ich dachte
am 4. april 2017 habe ich mir mein konto bei mstdn.io eingerichtet, wirklich genutzt hab ichs erst seit 2022
mit dieser einstellung werden jetzt kommentre von „verifizierten“ benutzern direkt freigeschaltet. mit anderen worten, jeder, der hier schon mal mt dem neuen system kommentiert hat (3 menschen, inklusive mir).
ausserdem habe ich kirby beigebracht mails zu versenden, push ist manchmal doch besser als pull, vor allem bekomme ich so benachrichtigungen über neue (zu moderierende) kommentare, was etwas praktischer ist als nach zu sehen.
gotosocial
nochmal die uberspace installationsanleitung für gotosocoal durchgelesen, die gotosocial-doku natürlich auch. insgesamt scheint mir das immer noch ein ordentlicher broken zu sein. ich rotiere ja schon kirby am lafen zu halten, bald steht ein grösseres kirby update an, das ich zumindest mal prüfen muss und dann gegebenenfalls 10 oder 20 jahre verzögern werde. oder eben nicht. jedenfalls scheint es mir gerade zu viel noch eine admin-aufgabe zu übernehmen, auch wenns nur für mich ist.
aber immerhin hab ich mir überlegt, welche domain ich nutze (irres.net oder w.irres.net) und weil ich vor kurzem meine uberspace-asteroiden in einem konto mit mail-anmeldung „konsolidiert“ habe, sollte es auch kein problem einen test-gotosocial-asteroiden hochzufahren und gegebenenfalls wieder zu löschen.
ich habe mich entschieden meine anpassungen hier ein wenig zu dokumentieren. ich liste diese changelogs nicht auf der hauptseite und im RSS feed, linke aber gelegentlich aus der hauptseite auf sie. ich vermute das interessiert nicht so viele leute, was ich hier im maschinenraum treibe. kategorie bleibt die gute alte über wirres kategorie und verschlagwortet werden die changelogs natürlich mit #changelog.
cache
der standardmässige file cache von kirby hat eigentlich ganz gut funktioniert. allerdings lief weiterhin alles über php und damit ein bisschen laggy. die uberspace hosts scheinen mir nicht irre performant zu sein, sowohl von der cpu-leistinmg als auch vom RAM. und wenn ich dann gelegentich den media-ordner mit den vorgenerierten thumnails lösche und die seiten neu gerendert und gecached werden, merkt man schon wie die VM ins schwitzen gerät und gelegentlich den PHP prozess killt.
jedenfalls bin ich drauf gekommen als ich merkte, dass die sitemap.xml nicht gecached ist. die generierung ist eher aufwändig und bots warten nicht gerne, bzw. sollten eigentlich keine überflüssige last erzeugen. die sitemap liess sich irgendwie nicht beim ersten versuch mit dem filecache sichern, weshalb ich bei der weiteren recherche auf staticcache stiess.
This plugin will give you the performance of a static site generator for your regular Kirby installations. Without a huge setup or complex deployment steps, you can run your Kirby site on any server – cheap shared hosting, VPS, you name it – and enable the static cache to get incredible speed on demand.
Rough benchmark comparison for our Starterkit home page:
Without page cache: ~70 ms With page cache: ~30 ms With static cache: ~10 ms
nach ersten tests konnte ich die werte grob bestätigen. mit dem static cache (in kombination mit dem browser-cache) sind die seiten extrem snappy. der trick ist, dass die gecachten seiten gar nicht mehr über php laufen, über die webserver-konfiguration werden cache-dateien direkt aufegrufen wenn sie generiert wurden.
das funktioniert für alle seiten ganz gut, auch die siztemap.xml oder die rückseite, aber weder mit dem alten file cache noch dem static cache ist es mir gelungen paginierte seiten zu cachen. das betrifft artikel-, tag-, kategorie- und archiv-seiten. da gibt’s noch ein bisschen arbeit.
andere caching anpassungen
beim caching der beilagen seiten hatte ich auch schonmal einen expliziten file-cache gebaut. der ging aber mit der umstellung auf static cache kaputt. aber immerhin kann man mehrere caches in der config.php parallel definieren:
so richtig zufrieden bin ich noch nicht mit dem beilagen-caching, die seiten sind ja quasi dynamisch und werden deshalb vom static cache ausgeschlossen. aber was mittlerweile wirklich spass macht: auf einer artikelseite j oder k auf der tastatur drücken und in windeseile zum vorherigen oder nächsten artikel gelangen. das geht auch deshalb snappy, weil ich auf den artikel seiten drei prefetches in den header gesetzt habe:
auf der beilagen-seite (beispiel) können jetzt kommentare abgegeben werden. alles mit maurice renkskomments-plugin umgesetzt. die konfiguration war initial etwas fummelig, unter anderem hätte ich auf mehrsprachigkeit umschalten sollen um die platzhalter und formular-bezeichnungen über die config.php anzupassen zu können. das hab ich auch mal kurz gemacht und gestaunt, was dabei alles kaputt geht. also snippet aus dem plugin in ein eigenes verzeichnis kopieren und dort anpassen. CSS war auch noch etwas fummelig, funktioniert aber soweit.
mit hilfe von chatgpt war danach der kommentaromat eine sache von 10 minuten. auch das css hat es auf nachfrage sehr gut hinbekommen.
wie man die freischaltung der kommenatre über eine moderationsschleife deaktiviert habe ich noch nicht herausgefunden, aber das kommt auch noch. bis dahin: moderieren.
ich freue mich sehr über css. das ist ein sehr merkwürdiger satz, der aber stimmt. jeden tag freue ich mich, dass ich eine der wenigen sachen die ich während meines architekturstudiums gelernt habe — oder eher, dass ich eine der wenigen sachen die mir wichtig genug erschienen um sie mir zu merken — hier im blog immer wieder anwenden kann:
sachen in würde kaputt gehen lassen. oder wie man auch in der IT sagt: to degrade gracefully.
mauerwerk ist so ein ding das würdevoll kaputtgehen kann. eine ziegelmauer sieht auch als ruine noch gut aus. vorhangfassaden, glasfassaden tun das nicht.
sowas hier
ist eigentlich nur ein <blockquote>, so sieht das dann ohne (oder mit weniger) css aus.
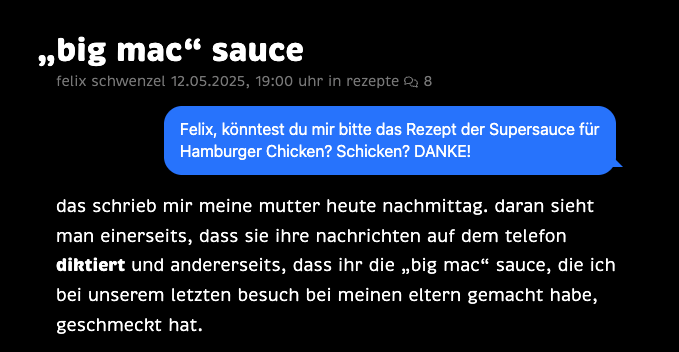
aber das man ein html-zitat mit ein bisschen css eben so wie oben aussehen lassen kann, das freut mich jeden tag aufs neue. oder gestern, als mir meine mutter eine nachricht schickte und ich dachte: screenshot posten und was dazu schreiben — bis mir einfiel: warum nicht css? dann sah das so aus:
auch die bubble ist ein einfaches blockquote, das ohne css, zum beispiel im rss-feed, würdevoll kaputt geht.
wen sowas nicht begeistert, der schreibt wahrscheinlich nicht selbst ins internet — oder nutzt wordpress.
aber das allerbeste, diese welt der css-magie steht auch mir als css-vollpfosten offen, dank LLMs. CSS-magie ist nämlich etwas, was die wirklich gut können.
jetzt bitte weiterblättern. danke für die kurze aufmerksamkeit.
ich weiss, ich schreibe in letzter zeit sehr häufig aus dem #maschinenraum. aber das liegt auch daran, dass ich dort gerade sehr viel zeit verbringe und dort auch sehr gerne bin. nachdem ich gestern innerhalb von 30 minuten mit hilfe meines neuen kollegen¹⁾ einen prototypen laufen hatte, hab ich den rest des tages damit verbracht rezepte (wieder) maschinenlesbar, strukturiert und ansehnlich hier veröffentlichen zu können.
ich werde ja nicht müde darauf hinzuweisen, dass man seine webseiten nicht für suchmaschinen optimieren soll, sondern für menschen, aber bei rezepten und vielen anderen webseiten-details gibt es markante schnittmengen. und inhalte strukturiert anzubieten dient der lesbarkeit und ermöglicht die nutzung von wekzeugen. rezept-scrapern zum beispiel. im alltag nutze ich sehr oft mela, dadrin sind alle meine wichtigsten rezepte. früher™ zu weihnachten haben wir die rezepte für die fleisch-fondue-sossen immer in einem grossen ordner gehabt. die sind jetzt alle in meiner icloud und ich kann vom handy oder ipad jederzeit drauf zugreifen. mela macht es einfach rezepte einzulesen, es lässt sich von kaum einer webseite abschrecken und auch rezeptbücher kann es sinnvoll per kamera einscannen und vertextlichen. eine wahre killer-app.
ich habe aber bemerkt, dass ich auch in den jahren vor meiner blogpause zwar regelmässig bis oft mein essen geteilt habe (gekocht), aber wenig richtige rezepte veröffentlicht habe habe. das will ich jetzt ändern, bzw. etwas strukturierter angehen.
eigene kategorie in der „echte“ rezepte stehen — und die ich regelmässig fülle und nachpflege
alle rezepte sind (grob) nach dem schema.org/Recipe schema strukturiert und werden (auch) als json-ld ausgegeben — microformate muss ich noch einbauen
weil mela auch rss-feeds lesen kann, ist meine zielvorstellung (ich mach das ja alles vor allem für mich selbst):
neue rezepte, die ich ausprobiert habe und die mir gefallen, verblogge ich
mela liest die rezepte aus dem RSS-feed ein und speichert sie dann persistent auf meinen geräten
eigenes rezepte-widget/übersichts-dings auf der rückseite (todo)
das heisst ich werde einen rss feed nur für die kategorie rezepte anbieten, den man dann in mela abonnieren kann. aber genau wie microformate ist das noch auf der todo liste.
vor 13 jahren hab ich das mit den strukturierten daten schon mal experimentell mit meinem alten CMS hingebastelt, für den gurkensalat nach tim mälzers oma²⁾ — das hat die migration zu kirby nicht überlebt, bzw. musste einfach neu gebaut werden. das hab ich jetzt nachgebaut und werde, wie gesagt, rezepte auch nachpflegen. weil das anlegen von strukturierten rezepten mit ezpublish damals etwas beschwerlich war, habe ich das nach dem gurkensalat auch nicht wieder gemacht, sondern rezepte, wenn überhaupt, auf der schriftspur veröffentlicht.
fussnoten: 1) chatGPT 2) die sahne kann man auch weglassen, bzw.mit öl ersetzen
eins der features das ich vom alten wirres.net aus pre-kirby-zeiten am meisten vermisst habe ist die navigation mit den j/k tasten. ich vermute zwar, dass ausser mir niemand daran interessiert ist oder sowas nutzt, aber wirres.net konnte das mehr oder weniger seit 15 jahren.
damals™ habe ich das mit einem jquery plugin gemacht, ob ich das hier benutzt habe oder was anderes weiss ich auch nicht mehr. ich weiss aber, dass ich das immer wahnsinnig nützlich fand und mich bis heute frage, warum das nicht viel weiter verbreitet ist. tatsächlich fallen mir aktuell nur zwei webseiten ein, auf denen das noch funktioniert: gmail und duckduckgo — und jetzt wieder wirres.net, zumindest auf übersichtseiten.
während dieses 15 jahre alte jquery-plugin auch nur 2 kb gross ist, wiegt jquery minifiziert auch nochmal 32 kb. als ich vor einem monat anfing wirres.net mit kirby wieder neu aufzubauen, war unter meinen ersten fragen an google …
die antworten auf die zweite frage waren mir damals zu kompliziert, bzw. verlangten zu viel javascript-know-how von mir, um das damals umzusetzen. gestern Nacht um 2 uhr fiel mir die frage wieder ein und ich fragte — chatGPT. die antwort war 1,6 kb lang und funktioniert einwandfrei und vanila, also ohne ein js-framework.
und wo ich gerade dabei war, hab ich chatGPT noch gefragt wie ich mit der x-taste die startseite, bzw. artikelübersichten kompakt anzeigen lassen kann, das geht mit neun zeilen code.
tl;dr: man kann auf der startseite und übersichtseiten jetzt mit j/k navigieren oder kurzzeitig alle artikel mit x gekürzt anzeigen.
p.s.
ich bin völlig baff, welche fortschritte javascript und css seit dem letzten mal, wo ich mich intensiver damit beschäftigt habe, gemacht haben. gestern nacht fiel mir auch ein zu fragen ob und wie man bilder per css schwarz weiss machen kann. geht!
img{filter:grayscale(100%);}
ich weiss nicht ob das normal ist, aber mich begeistert so etwas sehr. es gibt noch so viel auszuprobieren und zu basteln um dieses nest hier im web wohnlich zu machen.
p.p.s.
heute früh vorm spazieren gehen hab ich mich gefragt, ob man mit dem kirby struktur feldern nicht ziemlich einfach semantisch korrekte und maschinenlesbare rezepte (zum nachkochen) bauen kann. kann man, chatGPT spuckte mir wenige zeilen blueprint und template code aus, mit denen ich nach 10 muinuten einen funktionierenden prototypen hatte. beim thema rezepte im json-ld- oder in microformat treffen sich die beiden vektoren SEO-optimierung und nutzer-optimierung perfekt. weil rezept-schleudern wie chefkoch.de gerne vorne in den google-suchergebnissen stehen möchten, sind alle rezepte auf chefkoch.de per
ausgestattet. das hat zur folge, dass ich mehr oder weniger jedes rezept das ich jemals gegooglet und zu unserer befriedigung nachgekocht habe auch einfach und verlustfrei in mela importieren kann. warum mela so toll ist, hab ich hier mal vor zwei jahren erklärt.
in den letzten 23 jahren habe ich jeden einzelnen blog-geburtstag verpasst. natürlich habe ich gelegentlich über das (blog) alter gesprochen, aber jubuläums-artikel habe ich, glaube ich, nie geschrieben (und irgendwie auch albern gefunden). aber das lässt sich ja ändern …
voilà hier ist jetzt ein jubiläums-artikel, weil der erste unter der domain wirres.net verfasste artikel am 20.04.2002 veröffentlicht wurde. und das ist nach meiner berechnung — und der von carbon — jetzt 23 jahre her.
aber natürlich ist das im grunde total egal, weil ich schon viel früher das bedürfnis hatte ins internet zu schreiben, wie ich kürzlich in „30 jahre bloggen“ erwähnt habe. trotzdem: auf die nächsten jahre.
und in den nächsten jahren wird’s vielleicht auch interessant, denn in 29 jahren bin ich so alt, wie mein vater heute geworden ist. in acht oder neun jahren werde ich 25 jahre lang als arbeitskollege mit dasnuf gearbeitet haben. in elf jahren werde ich mein rentenalter erreicht haben — und so wie es aussieht, kann man auch im rentenalter noch lesenswertes ins internet schreiben. und in acht jahren werde ich 25 jahre mit der beifahrerin verheiratet sein. (den tag meines hochzeitstag kann ich mir gut merken, weil wir heiligabend in las vegas geheiratet haben, aber das jahr konnte ich mir nie merken. jetzt kann ich die site-suche benutzen um meinen hochzeitstag zu finden.)
ich hab meine rückseite schön gemacht. früher™ war ich wahrscheinlich der beste besucher der rückseite, weil ich sie mir als übersicht über die aktivitäten rund um mein blogdings gebaut habe. auch jetzt finden sich dort ein paar metadaten und zugänge ins archiv.
besonders interessant (für mich): offensichtlich habe ich im jahr 2015 am meisten veröffentlicht. keine ahnung warum, vielleicht war das die zeit in der ich fast täglich lange, kommentierte linklisten veröffentlich habe oder jeden pups von instagram und twitter in mein blog gezogen habe. und jetzt wo ich diese übersicht erstellt habe, sehe ich auch, dass meine blogpause effektiv fünf jahre lang war (2020 bis 2025). und das korrespondiert mit dem einzug von frida. offenbar hab ich da andere prioritäten gesetzt. insgesamt summieren sich die veröffentlichungen auf wirres.net auf ca. 10.800 „artikel“.
die tagcloud ist naturgemäss etwas chaotisch. ich hab sie aber auch reduziert auf die einträge der letzten 6 jahre und ein paar einträge extra. wenn ich jetzt anfange konsistent zu taggen, ist die tagcloud dann also in fünf, sechs jahren übersichtlich und klar. vielleicht.
ausserdem neu, der RSS-feed zeigt ab jetzt nur noch die sachen an, die auf der startseite sichtbar sind. so kann ich bilder oder notizen mittenrein oder auf die rückseite von wirres.net posten, ohne ein schlechtes RSS-gewissen zu bekommen. alles was mir relevant genug scheint, erscheint weiterhin auf der startseite.
in den letzten tagen haben kirby und ich uns besser kennengelernt. für mich ist der neubau meiner website wie weihnachten und geburtstag zusammen. ich freue mich schönes geschenkt zu bekommen und dann an die wand zu hängen oder in eine vitrine zu stellen. aber meine liebsten geschenke sind sachen aus denen ich selbst schönes bauen kann. so freue ich mich zum beispiel bis heute darüber weihnachten vor 14 jahren und weihnachten vor 12 jahren damit verbracht haben zu dürfen … eine küche aufzubauen.
so sollen gute geschenke sein: man bekommt einzelteile, oder besser gesagt ein system von bau- und gestaltungselementen, aus denen man selbst etwas eigenes bauen kann. dabei muss man nicht bei null anfangen, weil sich viele kluge menschen bereits gedanken über potenzielle probleme und lösungen gemacht haben und man sich einfach auf deren schultern stellen kann.
mit dieser idee lässt sich der erfolg von lego, minecraft und sicherlich zum teil auch von ikea erklären. ikeas genialster marketingtrick ist wahrscheinlich, dass man bei kunden eine art stockholm-syndrom auslöst. weil man durch die mühen und schmerzen des selbst-aufbaus durchsteht, schätzt man das ergebnis am ende positiver ein, als wenn man es fertig gekauft hätte.
natürlich ist auch der weg ein ziel. in meinen auseinandersetzungen mit kirby lerne ich wieder dinge über das programmieren. sehr hilfreich in sachen kirby, aber auch als einführung in die moderne php-programierung, sind zum beispiel die screencasts in der kirby guide von bastian allgeier. wenn ich mir die ansehe, muss ich ständig pausieren um schnell mal was auszuprobieren und staunend bei mir im zimmer rum zu stehen.
anders als ein leeres blatt papier, sind systeme wie kirby, aber auch home assistant, prall gefüllte werkzeugkisten, die einem zurufen: mit uns kannst du genau das bauen, was du schon lange bauen wolltest. und unterwegs lernst du viel über dich selbst, darüber wie teile der welt funktionieren und am ende hast du eine schön anzusehende baustelle, an der du — wenn du lust hast — die nächsten 10 jahren weiterbauen kannst.
jedenfalls habe ich in den letzten tagen viel im maschinenraum gearbeitet. wie bastian allgeier in den screencasts immer sagt, code getrocknet, eleganter gemacht und unterwegs viele abbiegungen entdeckt, die ich noch erkunden möchte. das alte wirres.net war sensationell gut suchmaschinen-optimiert. teilweise haben sich einträge minuten nach der veröffentlichung schon im google index gefunden. das ist durch die längere inaktivität und vor allem das einjährige von der bildfläche verschwinden, natürlich alles hin. und alles was den code angeht, die kleinen helfer für suchmaschinen und crawler, müssen neu her. dafür gibt’s viele helfer, aber es ist auch viel handarbeit und feinschliff nötig.
aber mit dem zwischenstand bin ich ganz zufrieden. so sieht das mittlerweile wieder in den suchergebnissen aus.
die sitemap spiegelt jetzt auch die robots-regeln, also alles was älter als 5 jahre (oder 3, bin noch unentschieden, aber derzeit sind’s 5) ist ausgeblendet. übersichtseiten will ich nicht im index haben, weil die sich so oft ändern und ohnehin nicht zum finden geeignet sind.
und beim suchwort mediathekwebview bin ich derzeit sogar auf der ersten suchergebnisseite.
die seite vom heutigen morgenspaziergang zeigt exemplarisch, warum ich einerseits so begeistert von kirby bin und andererseits, auf wie viel arbeit ich mich noch freuen kann.
so habe ich das erste bild während einer kleinen pause beim spaziergang gepostet. es wurde automatisch zu bluesky und mastodon syndiziert, allerdings hat irgendwas bei der aufbereitung für den RSS-feed geklemmt, da kam der artikel zunächst ohne bild an. später hab ich einfach 6 weitere bilder vom telefon in den artikel geladen und die dem kirby starterkit mitgelieferte galerie hat out of the box funktioniert. ich musste später nur noch ein bisschen am code schrauben, damit das auch mit responsive images funktioniert.
bildserien vom telefon aus ins internet posten und teilen, vor ein paar jahren war das noch ein feuchter traum, bzw. der grund warum apps wie instagram so erfolgreich waren. ich würde gerne weiter auf instagram posten, am liebsten automatisch von hier, aber das will facebook nicht, bzw. nur für „business“ kunden. also pausier ich das jetzt erstmal und freu mich, dass ich das jetzt „zuhause“ machen kann, mit dem gleichen komfort, aber unter meiner kontrolle. einziger nachteil von sowas: der ordner mit dem artikel und den bild-rohdaten die das telefon dahin geladen hat ist 30 MB gross. zum glück kann man bei uberspace mittlerweile festplattenplatz dazukaufen, oder, wenn alle stricke reissen sollten, kann ich kirby auch ganz schnell woanders hinschieben.
ausserdem bin ich jeztzt auch in den genuss des ersten, gar nicht mal so angenehmen kirby bugs gekommen. aus mir noch nicht ganz nachvollziehbaren gründen legt kirby eine temporäre datei an, vergisst die aber zu löschen, was unangenehme folgen hat (eindeutige IDs neuer artikel sind nicht mehr eindeutig, sondern gleich). aber da mein zweiter vorname „workaround“ ist, ist das auch kein so grosses problem.
die ideen, was ich hier noch so alles machen könnte, fliessen momentan ganz gut. mir gefällt das ruhige, minimalistische webschaufenster derzeit ganz gut, aber weil ich schon gerne (meta-) daten und sekundär-infos zu einzelnen artikel anzeigen möchte (vor allem für mich selbst natürlich), werde ich nicht nur meine alte rückseite reaktivieren, sondern auch eine packungsbeilage zu jeden artikel anlegen, quasi artikelrückseiten. da können dann auch kommentare und webmentions und so hin.
mit anderen worten, hier könnet es in den nächsten monaten immer wieder etwas ruckeln. wenn euch was auffällt oder nervt, sagt mir bescheid.
ich hab gestern angefangen meine rückseite, also die der webseite, wieder zu rekonstruieren — oder besser wieder zu beleben. ideen/todos hab ich einige, jetzt gibt’s erstmal ne blogrolle, angelehnt an die feeds, die ich in meinem feedreader verfolge.
die liste ist einerseits länger geworden als ich dachte und doch nicht komplett. aber jeder link hat einen kurzen kommentar oder einordnung spendiert bekommen.
das gabs seit bestimmt 15 jahren nicht auf wirres.net: eine funktionierende suche. jetzt schon.
ich staune selbst, was ich da alles finde. eigentlich will ich ja gar nicht dass man hier alles findet. nicht alle meine artikel sind gut gealtert oder auch nur im ansatz gut. aber auf ne art sind es eben auch zeitdokumente und ich stöber da gerne drin.
suchmaschinen verbiete ich schon seit langem das indexieren von übersichtseiten und artikeln die älter als 3 jahre sind. das hat damals enorm geholfen post von anwälten zu reduzieren. ausnahmen bestätigen die regel. tim mälzers gurkensalat rezept darf google gerne indexieren und verlinken. andere rezepte hab ich damals™ (wie heute) glaube ich auch entsprechend freigeschaltet.
und, den gag kollte ich mir nicht verkneifen, die such-funktion muss man natürlich auch erstmal suchen, bevor man sie verwenden kann.
eben etwas spät gemerkt, dass ich mir den RSS feed zerschossen habe. so ist das mit einem hackable cms. da hackt man auch mal was kaputt. sollte jetzt wieder funktionieren, sorry, ich lerne noch.
aber abgesehen davon heute auch gelernt:
kirby lässt sich updaten, indem man einfach den kirby ordner im webroot austauscht und dazu soll man den media ordner löschen (in dem automatisch generierte bilder und und so liegen)
den media ordner hab ich daraufhin gestern gelöscht, der war mittlerweile auf 6 GB angewachsen. es zeigt sich, am anfang hab ich wohl was falsch gemacht. die generierten bilder brauchen jetzt bei weitem nicht mehr so viel platz (nach 30 stunden 414 MB ) und die generierung geht verzögerungsfrei, ohne dass ich das gefühl habe, dass der server ächzt. das läuft aber alle unter dem motto: lass uns erst mal kennenlernen, liebes kirby.
das plugin gedöns bei kirby ist weniger „it just works“ als bei wordpress. das liegt wohl auch daran, dass die freiheitsgrade beim konfigurieren von kirby sehr viel grösser sind. aber so lernt man sich eben auch immer besser kennen, kirby und ich.
und kirby kann vieles was mich begeistert:
SVGs werden einfach wie bilder angezeigt, wenn man sie wie bilder hochlädt.
transparente PNGs bleiben transparent, wenn sie skaliert werden
wie man core oder pluginfunktionen, templates, snippets in kirby überschreiben, bzw. erweitern kann ist fantastisch. einfach plugin snippets in den regulären snippet ordner kopieren, dann werden die benutzt. almost always fails gracefully.
ich fühle mich tatsächlich ein bisschen wie in der frühphase meines bloggens. bloggen um die technik zu testen, sachen auszuprobieren, schauen was geht und wie man es besser machen kann.
chatgpt meint ich könne cloudflare nicht mit wetterleuchten übersetzen. wolkenflakern hört sich aber doof an. aber darum geht’s eigentlich auch gar nicht. ich wollte nur bescheid sagen, dass ich cloudflare auf wirres.net abgeschaltet habe. die datenschutzerklärung habe ich entsprechend geändert.
die probleme mit langen ladezeiten und langsamen laden von bildern, die ich in den letzten tagen immer wieder beobachtet habe, sind seitdem verschwunden. ich vermute ich hätte meine cloudflare einstellungen irgendwie anpassen müssen. mit dem alten wirres.net hat cloudflare viele jahre lang wunderbar funktioniert (mein ich zumindest), aber im zusammenspiel mit kirby hat es wohl gehakt.
jedenfalls meckert jetzt auch google pagespeed/lighthouse nicht mehr und alles fühlt sich erstmal schön snappy an.
das template, bzw. der template-ordner auf dem diese website bis vor ungefähr einem jahr lief hiess wirres3. nach diese logik ist der kirby-relaunch wohl wirres version 4.
version 2 dürfte das hier gewesen sein, 2010 war ich stolz darauf von einem tabellen-basierten layout auf ein CSS basiertes layout umgestellt zu haben.
version3, bei der ich auf „responsive design“ umstellte, lief dann 12 jahre lang.
und eben, zufällig im archiv gefunden, 2015 schrieb ich über die version 0 von 1996. die lief zwar noch nicht unter wirres.net oder irgendeinem content managmente system, sondern auf blanken html-metal. in dem artikel von 2015 behaupte und belege ich, dass ich eiegentlich schon seit 30 jahren (1995) ins internet schreibe, bzw. linke.
und ich erkläre anhand eines kottke zitats, warum ich so lange auf diesem obskuren CMS geblieben bin: läuft halt, funktioniert, ist berechenbar und kenn ich.
einer der technischen gründe warum ich mit einer software aus den 90er jahren so lange gut zurecht kam, waren die html-vorlagen, also die art wie ezpublisch html aus den inhalten produzierte. jedes formatierung, bilder, links, zitate hatten ihre eignen vorlagen. statt <a href="https://example.com>example.com</a> schrieb ich <link https://example.com example.com>> bilder lagen in einer bilddatenbank und nach der verknüpfung mit einem artikel refernzierte ich sie mit <image 1 left large> was sich kompliziert und mühsam anhört ist technisch ein segen. so wurden bilder in den neunziger jahren vorzugsweise über tabellen-konstrukte gelayoutet. <figure> oder <figcaption> waren damals noch nicht erfunden, adaptive bilder erst recht nicht. aber mit dem template system liess sich die ausgabe von bildern jeweils an den stand der technik anpassen. so konnte ich aus einem einfachen <image 1 left large> schnell komlexes, adaptives bild-markup bauen, das optimierte bilder für alle möglichen bildschirmauflösungen ausgab.
in den neunzigern durfte man noch <b> zum fetten von text verwenden. im ezpublish backend musste ich immer <bold> verwenden, aber konnte die html-ausgabe dann eben später an das modernere <strong> anpassen.
und natürlich liess sich das auch alles erweitern. für eingebettete youtube videos hab ich mir eine ezpublish vorlage <tube hGhrJru-PQ8&t> gebaut, die dann anfangs einfach den normalen youtube embed-code ausgab und später eine datenschutzfreundlichere variante, die nur das video-poster mit einem play-button zeigte und das video und das google-tracking erst nach einem klick lud. weil kirby mit seinen block-editor ein ähnliches konzept verfolgt, liess ich das für alle meine importierten inhalte und natürlich auch neuen inhalte ruck-zuck neu bauen. im block editor gebe ich nur die video-url an, die ausgabe des blocks passe ich per template an und heraus kommt das:
diese datenschutz-freundlicheren video-embeds sind das, womit ich gestern meinen tag verbracht habe. funktioniert für youtube und vimeo.
ich weiss zwar gar nicht ob das noch irgendwer verwendet, bzw. ob ich noch jemals ein vimeo-video hier neu einbetten werde, aber weil ich in meinem archiv noch das eine oder andere vimeo-video liegen habe, soll das natürlich auch weiter so funktionieren.
ausserdem habe ich gestern noch am rss-feed geschraubt. wenn ich im kirby editor einen relativen link eingab, kam der auch im rss-feed relativ raus. which is doof. aber vielleicht isses auch doof relative links zu verwenden, wenn ich mich recht erinnere hab ich in ezpublish auch immer volle urls verwendet um auf wirres.net zu linken. ausserdem hab ich mir überlegt im feed den normalen youtube-embed code auszugeben, so dann man sich das video in seinem rss-reader eingebettet ansehen kann. ganauso gebe ich die bilder im feed nicht mehr adaptiv aus, sondern einfach, ohne gedöns auf 900px breite skaliert.
jedenfalls sehe ich jetzt wieder was mich über die letzten 30 jahre dazu gebracht hat ins internet zu schreiben: mein drang neue dinge auszuprobieren, zu schauen, mit welchen technischen tools man was erreichen kann um das älteste gewerbe der welt auszuüben: mit anderen kommunizieren.
in den letzten 5 jahren lag mein fokus eher auf der interspezifischen kommunikation: wie kann ich verstehen was frida will und intendiert, wie stelle ich sicher, dass frida mich versteht? das hat ganz gut geklappt und unterwegs habe ich das eine oder andere gelernt und leider eher wenig mit meiner spezi geteilt. ausser einmal letztes jahr auf der republica.
in der web-technik hat sich in den letzten jahren, so wie bei den hunde-erziehungsmethoden viel getan. lazyloading geht mittlerweile ohne jedes javascript, css kann variablen und rechnen (!), fast alle browser sind auf dem gleichen technischen stand. uberspace, wo diese seiten gehostet sind, kann http/2 und ich bin sicher an den caching-policies, cache-control headers lässt sich noch so einiges optimieren und lernen.
apropos caching und performance. nach der installation von kirby auf uberspace (piece of cake, einfach den 2,5 GB grossen kirby ordner rüberkopieren, eine kleine anpassung an der .htaccess, läuft) …
# In some environments it's necessary to# set the RewriteBase to:RewriteBase /
… habe ich massive performance probleme beobachtet und musste in der php.ini php mehr RAM gönnen. der grund, so erkläre ich es mir nachträglich, war cache-warming. kirby erzeugte hunderte, tausende bildvarianten für die adaptive auslieferung von bild-dateien, und das kostet RAM und CPU (sorry uberspace!). gestern habe ich die parameter der adaptiven bildauslieferung nochmal angepasst, was erneut zu merklichen performance-engpässen führte. ein blick in den media ordner, wo kirby die bildvarianten cached/ablegt, zeigt derzeit 5.8 GB. vor drei tagen waren das nur 2.4 GB, gestern 4 GB. der kirby content ordner ist 2,4 GB gross.
nach ein paar stunden bild-generierung schien die performance der seite wieder OK zu sein. wenn ihr, liebe leser, einen anderen eindruck habt, lasst es mich gerne wissen.
tl;dr: ins internet schreiben und eine eigene website zu betrieben ist immer noch furchtbar viel arbeit, aber allein um den stand der technik zu verfolgen, (be-)lohnt sich das. und es gibt noch viel zu tun und lernen.
(entschuldigung für die clickbait-überschrift, korrekt müsste es natürlich heissen: „30 jahre ins internet schreiben“)
vor 22 jahren hab ich auf wirres.net den ersten „artikel“ veröffentlicht. auf einem CMS namens ezpublish, damals in der version 2.2.x. später hab ich ezpublish mal auf 2.3.0 aktualisiert, danach im prinzip nicht mehr.
vor ziemlich genau vier jahren hatte ich ezpublish noch einmal geflickt, damit es es mit php 7.4 läuft. vor einem jahr war dann bei uberspace schluss mit php 7.4. wie ein alter weisser mann, kam mein CMS mit den erfordernissen der modernen zeiten (php 8.x) nicht mehr zurecht. deshalb hab ich im letzten jahr kurzfristig erstmal auf tumblr ersatz geschaffen.
ezpublish hat mir zwei jahrzehnte treu gedient. es liess sich anpassen und offensichtlich auch von jemandem mit lückenhaften programmierwissen patchen und am laufen halten, sogar mit okayer performance.
jetzt, ein jahr später wollte ich es noch einmal wissen, ob ich mit etwas geduld und vielleicht hilfe von chatgpt, dem alten CMS nochmal die moderne welt erklären kann. es zeigte sich, dass das eher schwer und uberkomplex ist. seit der php version 4.x hat sich dann doch einiges getan.
was relativ einfach ging war wirres.net lokal, bei mir zuhause, auf meinem heimserver in einem php7.4 container zum laufen zu bringen (und so im prinzip für die ewigkeit zu konservieren). mit einem eintrag in die /etc/hosts lässt sich auf meinem rechner wirres.net aufrufen, als wäre nie etwas gewesen.
beim googlen nach alternativen gefiel mir kirby von anfang an. ich mochte das konzept, dass artikel in ordnern organisiert sind und alle zugehörigen dateien mit in diesem ordner liegen. die doku gefiel mir auch und das starter kit, hatte, wie damals ezpublish, sinnvolle beispiele wie man das ding zum laufen bringt und was man damit anstellen kann. mir kamen auch schnell ideen, wie ich die inhalte aus ezpublish in kirby importieren könnte. nachdem ich mir in meiner lokalen wirres.net instanz ein export script zusammengebastelt hatte, war ich erstaunt wie schmerzfrei der import ging und wie gut kirby meine inhalte verstand. immerhin handelte es sich um über 10.000 artikel (im ø habe ich offensichtlich über die 22 jahre jeden tag etwas mehr als einen artikel geschrieben).
jedenfalls sind jetzt die artikel wieder da. auch die meisten alten urls sollten wieder funktionieren. der letzte auf der alten seite veröffentlichte artikel hätte in alter notation die url /article/articleview/11437/1/6/ und das funktioniert. die alte haupt-rss-feed-adresse sollte noch gehen, aber es dürfte auch einiges kaputt sein — also noch viel zu reparieren sein.
mal schauen wie es hier weitergeht. kirby ist toll, flexibel und auf eine angenehme weise unterkomplex, aber eben doch hochflexibel.
der import der inhalte hat natürlich auch dazu geführt, dass ich nochmal alte sachen die ich im laufe der zeit veröffentlicht habe gelesen oder angesehen habe. mich hat das daran erinnert, warum ich jahrelang ins internet schrieb: um sachen festzuhalten, die sonst im schaum der zeit verpuffen. es ist zwar schön im eigenen instagramm-konto ganz runter zu scrollen, aber #instagram auf der eigenen webseite ist noch schöner. und zum teil auch ein bisschen strukturierter. #schottland zum beispiel. oder die urlaubsvertretung damals (2005).
irgendwann im letzten jahr wollte ich jemandem ein bild vom pöhler zeigen, aber wirres.net war offline, auf meinem telefon finde ich eh nix und ausdrucke hab ich schon seit 40 jahren nicht mehr dabei. in der eignen unordnung lässt sich sowas ganz schnell finden.
jedenfalls bin ich froh wieder online zu sein.
wirres.net läuft ja leider auf einem etwas älteren und obskuren CMS und weil ich derzeit keine lust habe den PHP code des CMS auf die neuesten PHP versionen hoch zu hacken, funktionierte wirres.net bis heute nur so halb und seit heute gar nicht mehr. deshalb hab ich etwas brutal mal eben alles auf diese ersatz-seite umgeleitet.
wenn ich wieder ein bisschen zeit und lust habe, mach ich die alte seite wieder gängig. dass zwischendurch links brechen und feeds ins leere laufen, tut mir sehr leid, immerhin hatten die jetzt schon über 20 jahre gehalten. aber ich versuche mein bestes zu geben, das wieder zu richten.
aktuelle verlautbarungen also erst mal hier.
hier auch gleich die erste verlautbarung: am 29.05.2024 spreche ich auf der republica in berlin.
dieser beitrag und einige andere wurden zuerst auf dem tumblr-ersatz-blog veröffentlicht. mittlerweile habe ich die beiträge wieder hierhin exportiert.
diese website läuft jetzt auf php7.4. das wurde erforderlich, weil uberspace, mein hoster, die alte plattform einstellt, auf der wirres.net viele jahre auf php5 lief. das CMS hier hinter ist bekanntlich sehr alt und lief nicht auf anhieb auf php7. nach zwei abenden fummeln und googlen lief dann aber doch alles auf der neuen plattform.
vorher hatte ich ziemlichen bammel auf irgend so einen modernen quatsch wie wordpress umsteigen zu müssen und meinem archiv „gute nacht“ sagen zu müssen. zumal ich das selbst wohl am meisten bedauert hätte, ich such ständig nach alten rezepten hier.
die nächsten 10 jahre wirres.net dürften hiermit aber erstmal (zumindest technisch) gesichert sein, php-rückwärtskompatibilität, stackoverflow, uberspace und geschicktem googeln sei dank. jetzt muss ich nur noch motivation finden mal wieder öfter was hier festzuhalten.
wer noch fehler findet, was ziemlich wahrscheinlich ist, kann mir gerne bescheid sagen.
seit diesem artikel ist die artikel-id meiner ez-publish installation auf 10.000 geklettert. das heisst nicht, dass ich 10.000 artikel auf wirres.net geschrieben habe, genaugenommen sinds 9429 veröffentlichte artikel. dazu kommen noch ein paar artikel von gastautoren. die fehlenden 513 artikel sind entweder gelöschte artikel, nie veröffentlichte entwürfe oder fehler.
seitdem ich für jedes instagram eine kopie als artikel aus der kategorie bilder anlege, ebenso für swarm-checkins, instagram-, twitter- oder youtube-favoriten — und tweets (meist) zuerst hier schreibe, bevor ich sie zu twitter oder facebook kopiere, ist die zahl der auf wirres.net veröffentlichten artikel stark gestiegen. deshalb ist auch die artikel-id im letzten jahr relativ schnell (nach 14 jahren) auf zehntausend gestiegen.



















{kind=link}