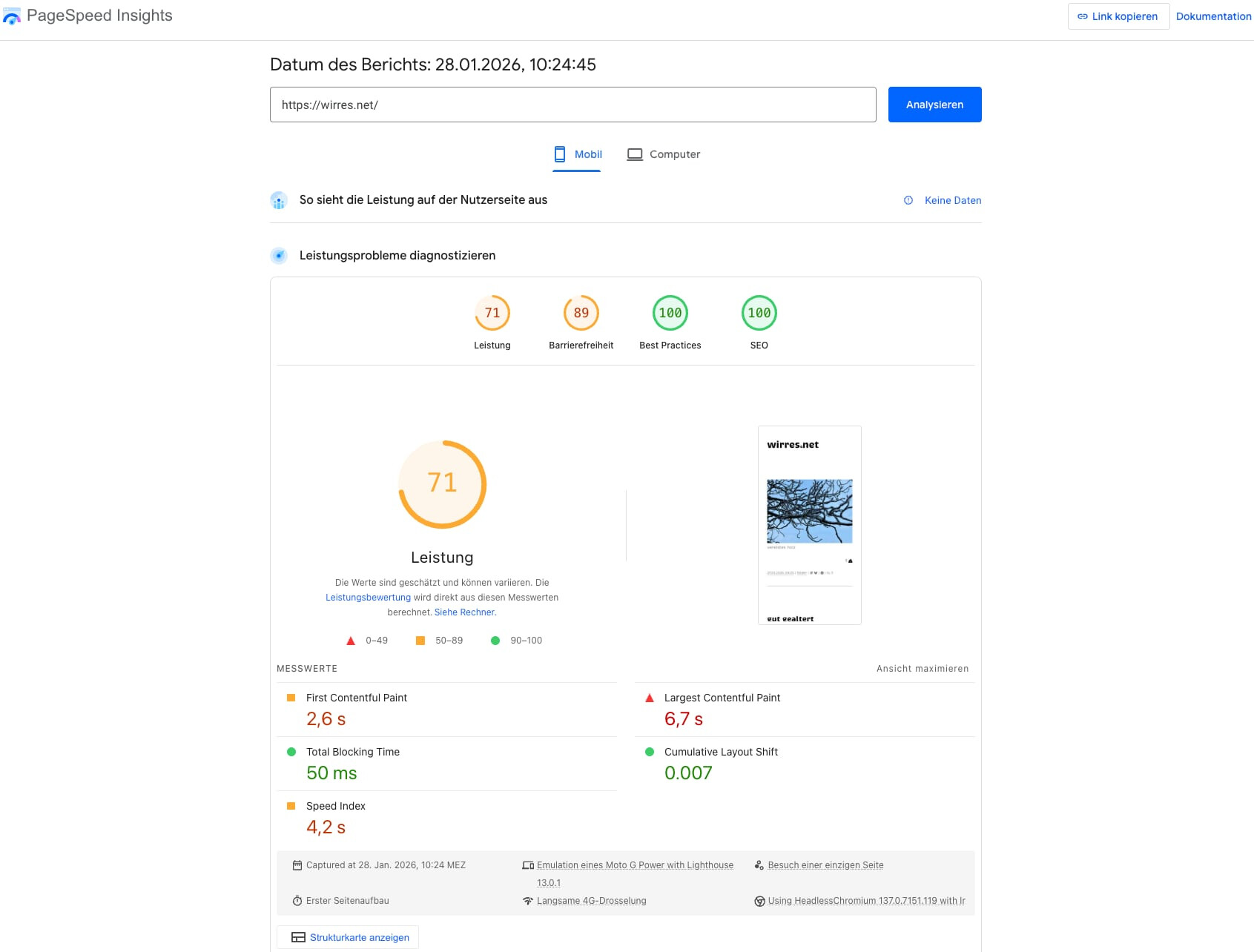
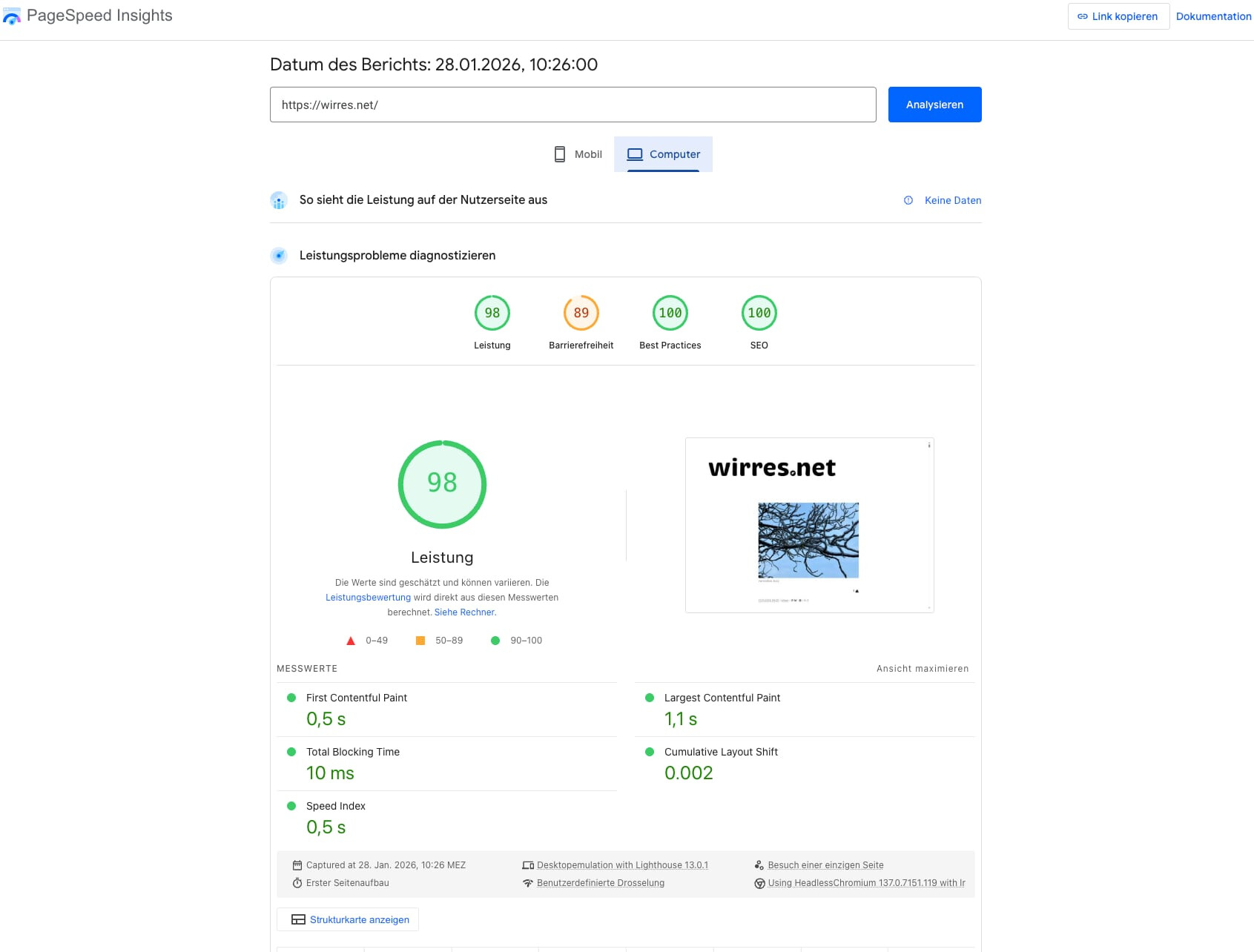
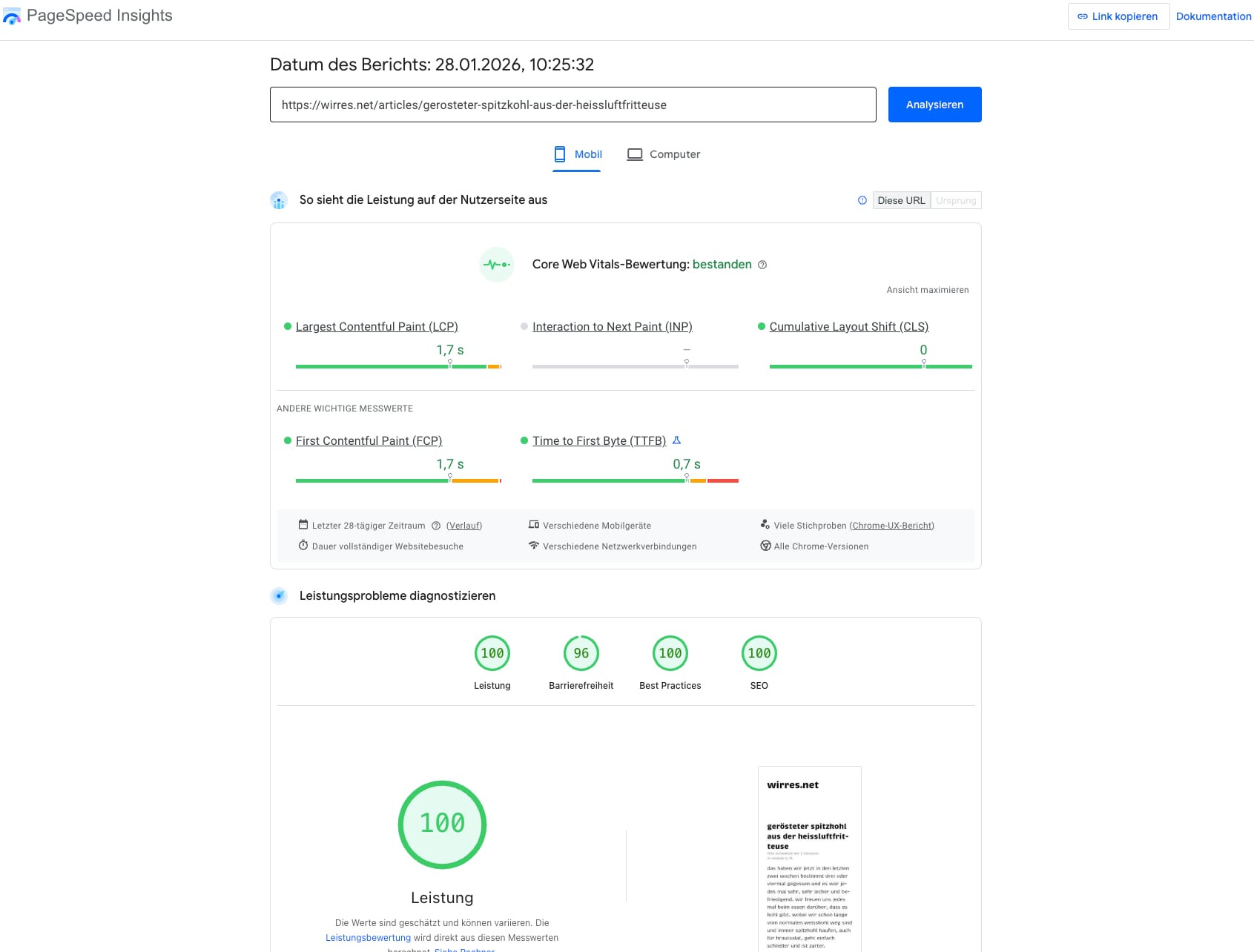
endmarken, fucking homepod, batterien, the agency und formel1
ich benutzte meinen homepod eigentlich nur für zwei dinge und alleine wegen dieser beiden dinge mag ich meinen homepod sehr, sehr gerne. bis heute.
die eine sache für die ich die siri im homepod gerne nutze ist zu fragen: „wie spät?“ die andere sache ginge wahrscheinlich auch mit jedem anderen der 5 vernetzten lautsprecher bei mir im zimmer, aber ich lasse es den homepod machen: bei einem formel-eins-rennen, fünf minuten vor start ein formel-eins-wrooooom-geräusch abspielen.
seit heute fängt siri selbständig an musik abzuspielen. leise, aber immer wieder. da sich homepods nicht wirklich debuggen oder befragen lassen was sie zur jeweiligen aktion gebracht hat, steh eich völlig auf dem schlauch. ich habe zwischenzeitlich alles abgeschaltet was ich in verdacht hatte, mein iphone, home assistant, mein laptop bluetooth, die klimaanlage — nichts hilft.
aber zum automatisieren habe ich ja home assistant. eine kleine automation schaltet die musik jetzt aus, sobald die musik startet.
alias: fucking homepod aus
description: ""
triggers:
- trigger: media_player.started_playing
target:
entity_id: media_player.homepod
options:
behavior: each
for: "00:00:00"
conditions:
- condition: state
entity_id: media_player.homepod
state:
- music
attribute: media_content_type
actions:
- action: media_player.media_stop
metadata: {}
target:
entity_id: media_player.homepod
data: {}
mode: single
das funktioniert, auch wenns keine lösung ist. wenn ich in den nächsten tagen nicht rausbekomme was oder wer das verursacht, muss der homepod temporär sterben (stromlos werden). immerhin habe ich ausgeschlossen, dass der homepod das rauschen der klimaanlage als sprachbefehle interpretiert.
apropos formel 1, das guck ich ja gelegentlich gerne und fahre dafür gerne mit einem virtuellen privaten netzwerk nach östereeich. das rennen heute in östereich konnte zwar nicht viel mehr als dreissig prozent meiner aufmerksamkeit binden, war aber trotzdem ganz spannend. aber wirklich toll waren die drohnenaufnahmen, nicht mit der üblichen drohnen-vogelperspektive, sondern eine drohne, die den autos mit bis zu 300 km/h im tiefflug hinterherflog. keine ahnung was man machen muss um für sowas bei einer veranstaltung mit publikum eine genehmigung zu bekommen, aber östereich hatte ja noch kein rammstein. die bilder waren aber tatsächlich beeindruckend.
beim spiegel habe ich das schon öfter gesehen: endmarken. wenn ein spiegel-artikel zuende ist, klascht der spiegel ein logo-„S“ an den letzten absatz.

das kann ich auch, dachte ich mir und klatsche jetzt einen haufen scheisse, meinen shit-vote, bzw. „ich mag diesen scheiss!“-button an den letzten absatz — oder je nachdem, wenn ein beitrag nicht mit einem absatz endet, auch dadrunter.
ausserdem habe ich den artikel-fuss („footer“), die kommentar-sektion und die beilage ein bisschen neu geordnet, in der hoffnung dass damit auch menschen die nicht ich sind die funktion und den sinn (ein bisschen) begreifen. wenn nicht, ist auch nicht so schlimm, solange meine texte (ein bisschen) verständlich sind.
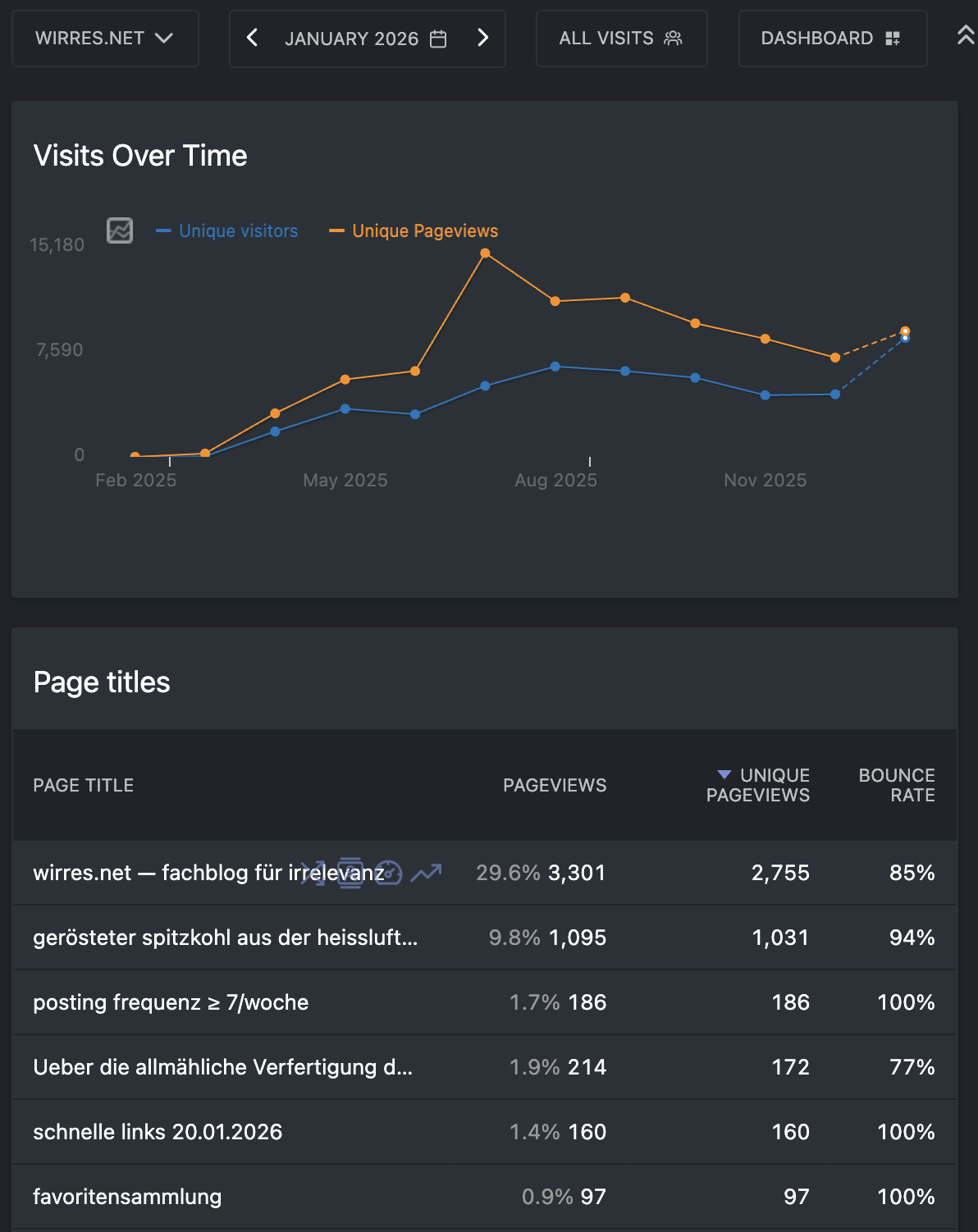
auch witzig (für mich) meine mutter, die jetzt ja ein welterste und -einzige wirres.net-beiträge per email bekommt, meinte sie hätte die letzten artikel nicht gelesen. dass habe ich ehrlichgesagt auch nicht anders erwartet, dass mein reigen an technischen deep-dives ins ATprotokoll, avtivitypub, bubbles und meine maschinenraum-geschichten an einem teil des publikums vorbeigehen und dass dieses publikum genau das tut, weiterblättern („scrollen“). das ist das schöne am internet: man kann den massengeschmack ignorieren und ganz viele nischeninteressen („long tail“) bedienen und das gezielte ignorieren funktioniert.
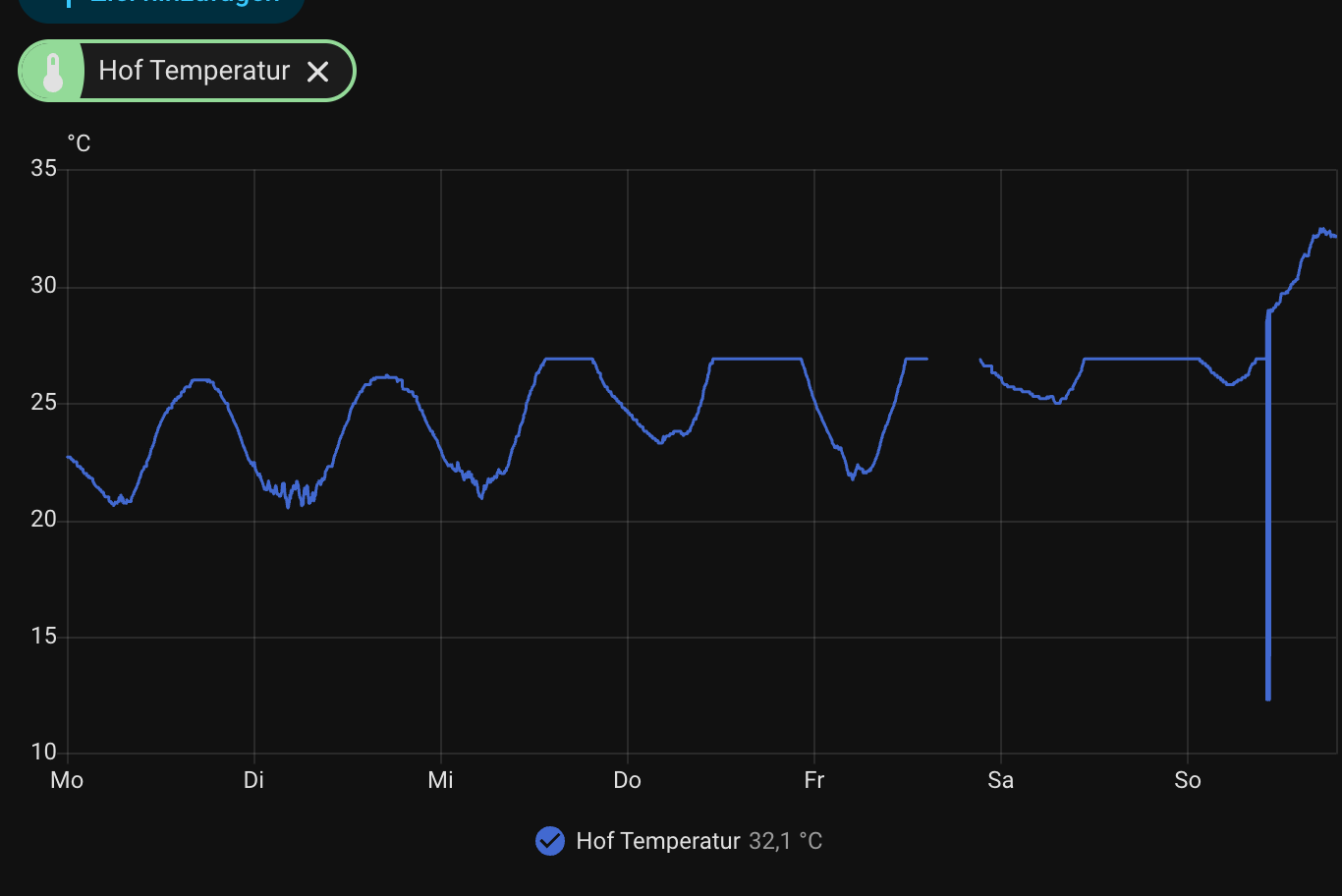
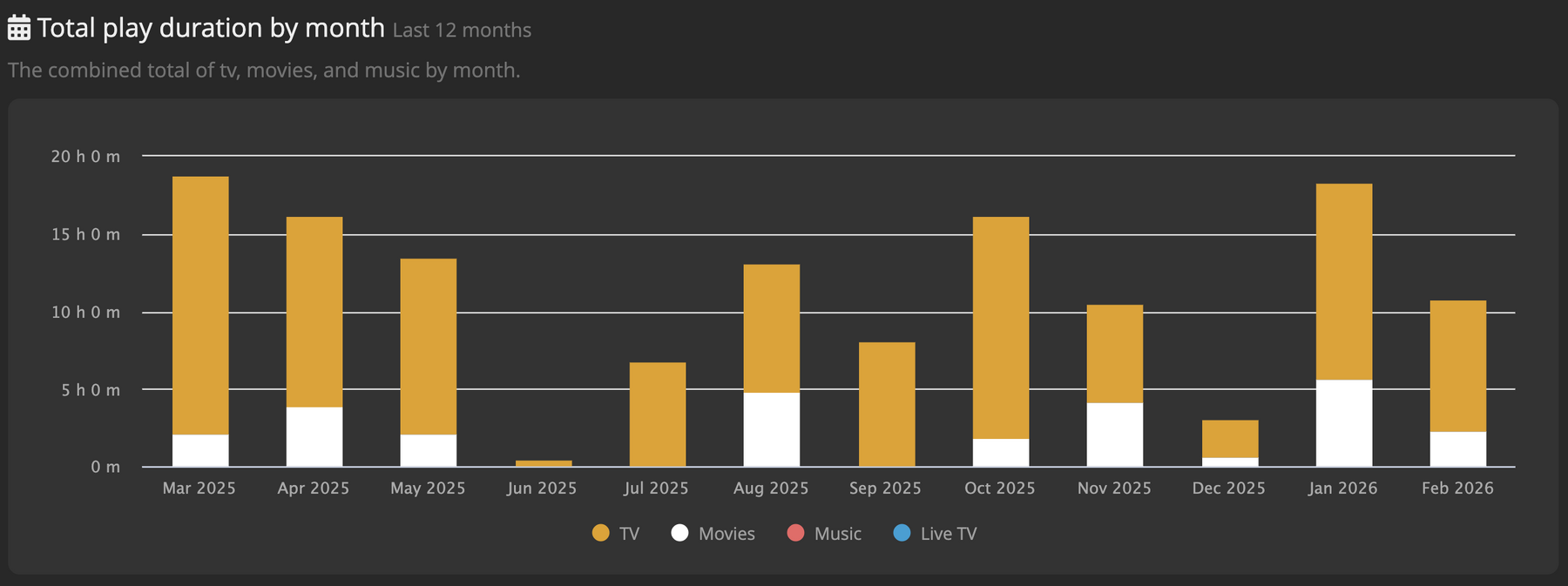
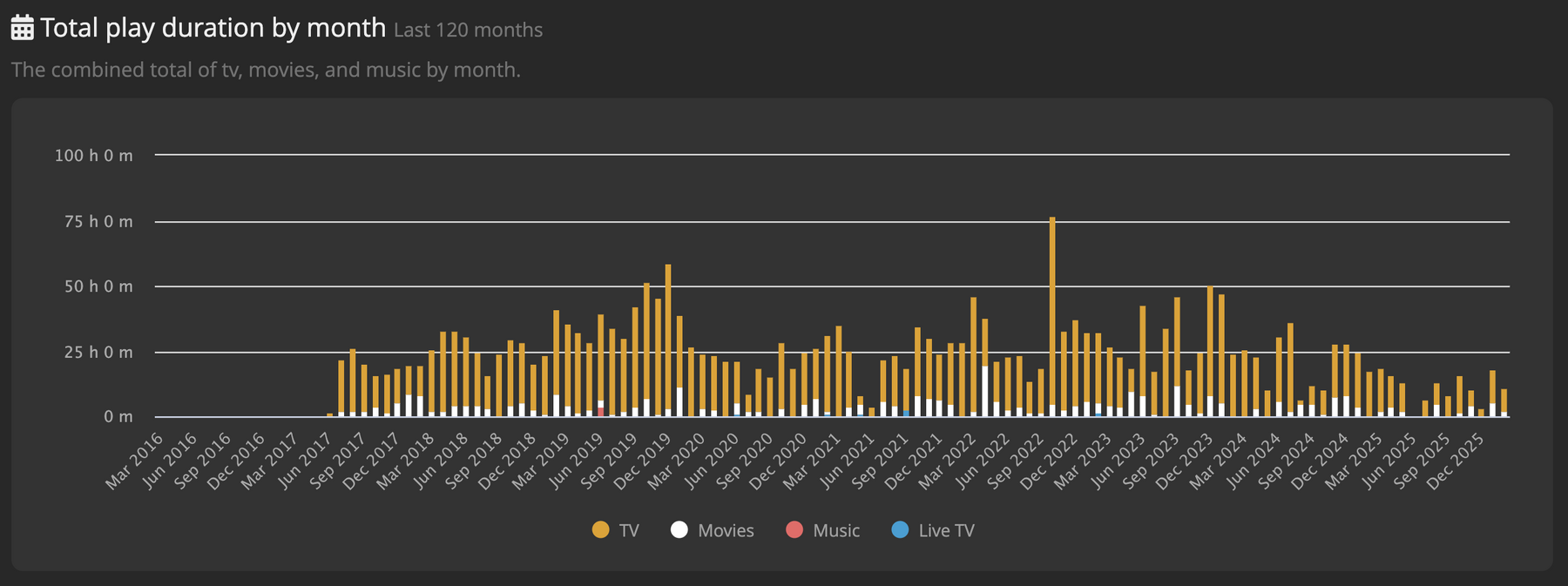
apropos home assistant und automatisierungen: phasenweise habe ich mich damit genauso manisch beschäftigt, wie ich mich derzeit manisch mit dieser website beschäftige. aber home assistant ist so freundlich, dass es auch ohne meine aufmerksamkeit monatelang zuverlässig funktioniert. selbst gelegentlich leerlaufende batterien bringen das system und die sensorik nicht zum erliegen, auch weil ich vieles redundant aufgesetzt habe. trotzdem habe ich der automatischen wohnung heute nochmal etwas aufmerksamkeit geschenkt, updates eingespielt, kaputtaktualisiertes („breaking changes“) gefixt, batterien getauscht und über-optimistische-sensor-wert-validierungen, bzw. glättung. als ich die aufgesetzt habe, konnte ich mir nicht vorstellen, dass am hoffenster temperaturen > 27°C auftreten (das ist immer im schatten). pustekuchen, in den letzten tagenm gings öfter drüber. deshalb hat meine sensor historie jetzt abgeflachte kurven und durch die filter-anpassung ein paar falschmessungen/ausreisser nach unten.
the agency staffel 2 hat mich in den ersten paar folgen mit 4 parallelen handlungssträngen total überfordert. aber mit jeder folge verstehe und finde ichs besser. die abgefucktheit von geheimdienstarbeit bringt die serie wirklich gut rüber, vor allem im gegenteil zu den 2000 anderen filmen und serien die geheimdienstarbeit gerne ästhetisieren, ridikülisieren oder glorifizieren. das macht the agency zwar auch, sonst wäre es ja nicht eine fiktionale unterhaltungssendung, sondern eine „true political crime“-serie auf netflix.
das klimaanlagen-/wärmepumpen-rabbithole, in das markus kürzlich gefallen ist, habe ich gerade noch vermieden. die beifahrerin hat vor ein paar jahren eine mobile, kleine klimaanlage für ihr atelier gekauft, die jetzt in meinem zimmer steht und es auf erträgliche 24,5°C kühlt. sie hat jetzt zwar auch interesse an einem weiteren gerät angemeldet, weil die temperaturen in ihrem zimmer jetzt auch auf über 25°C klettern. und meine eltern wollen auch eine. und da soll ich dann sowohl beraten als auch montieren. aber das konnte ich alles gut in den winter schieben weil man jetzt ohnehin nichts derartiges kaufen kann.
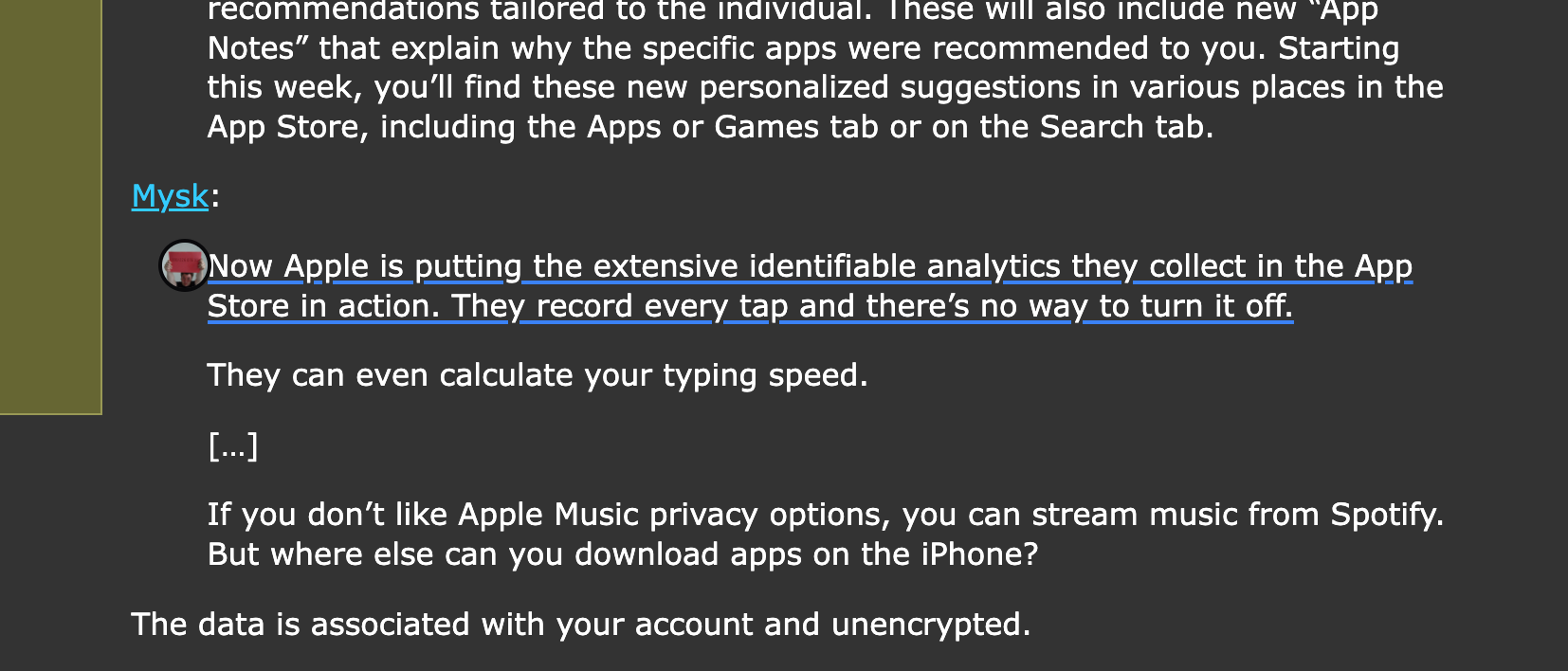













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}