tagebuch 30.08.2025
hier zu schreiben fällt mir ziemlich leicht. man sagt mir nach, dass ich texte hier hinrotze und da ist wahrscheinlich auch was dran. ich schreibe hier in gewissem sinne hemmungslos; wenn der eine oder andere gedanke noch nicht zuende gedacht ist, hält mich das nicht davon ab ihn aufzuschreiben. gelegentlich reifen die gedanken während des schreibens, manchmal danach oder ich greife sie später (oder nie) wieder auf.
texte die ich im auftrag schreibe oder gegen geld, muss ich mir hingegen aus der nase ziehen. ich spüre den druck alle gedanken am ende des textes zuende gedacht haben zu müssen, ich presse oft, statt es fliesen zu lassen. trotzdem habe ich es bis anfang letzten jahres fast 10 jahre durchgehalten eine kolumne für die (gedruckte) t3n zu schreiben.
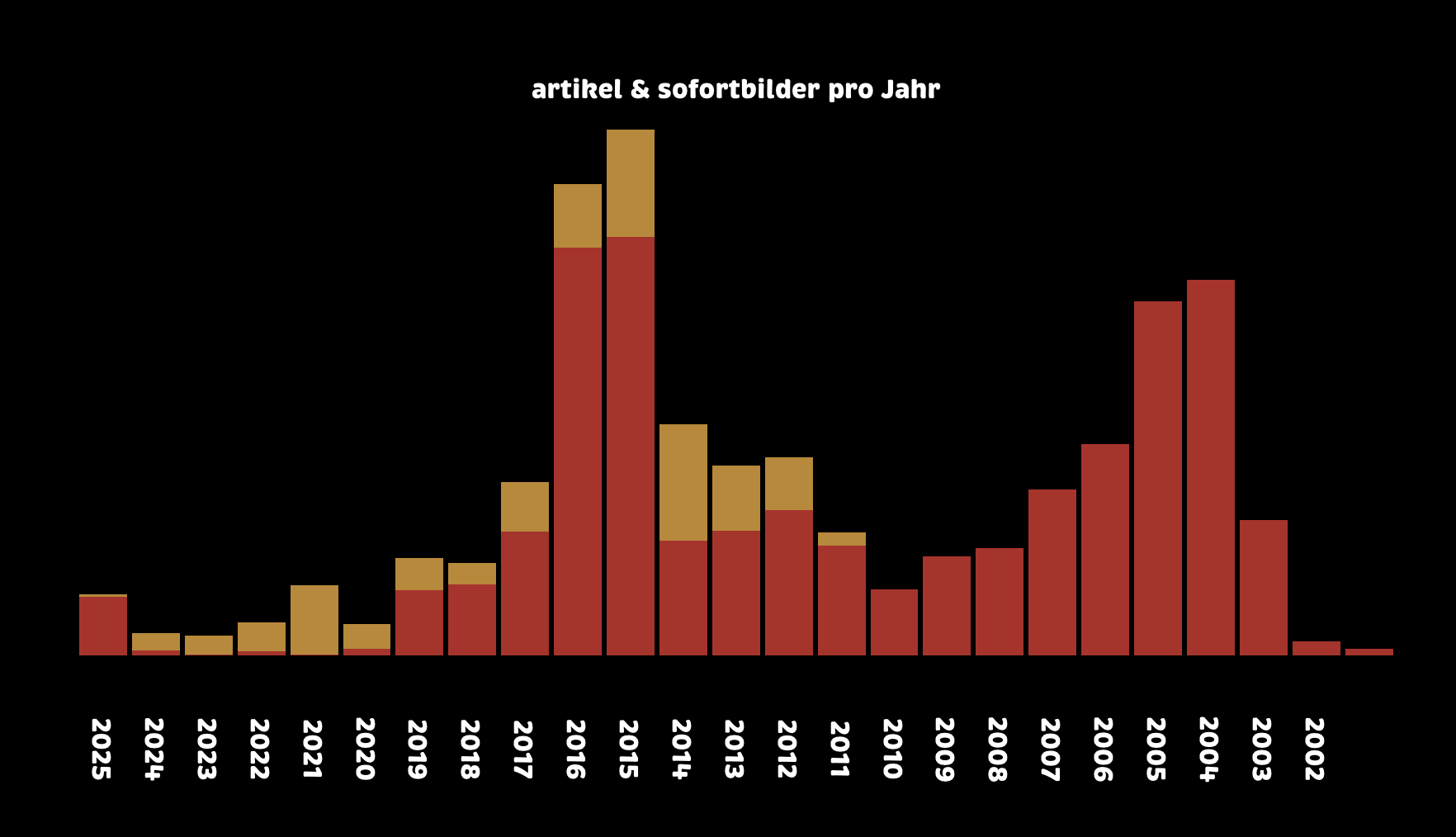
heute habe ich versucht die noch fehlenden artikel hier zur archivierung zu ergänzen und neu und konsistent zu kategorisieren (kategorie t3n).
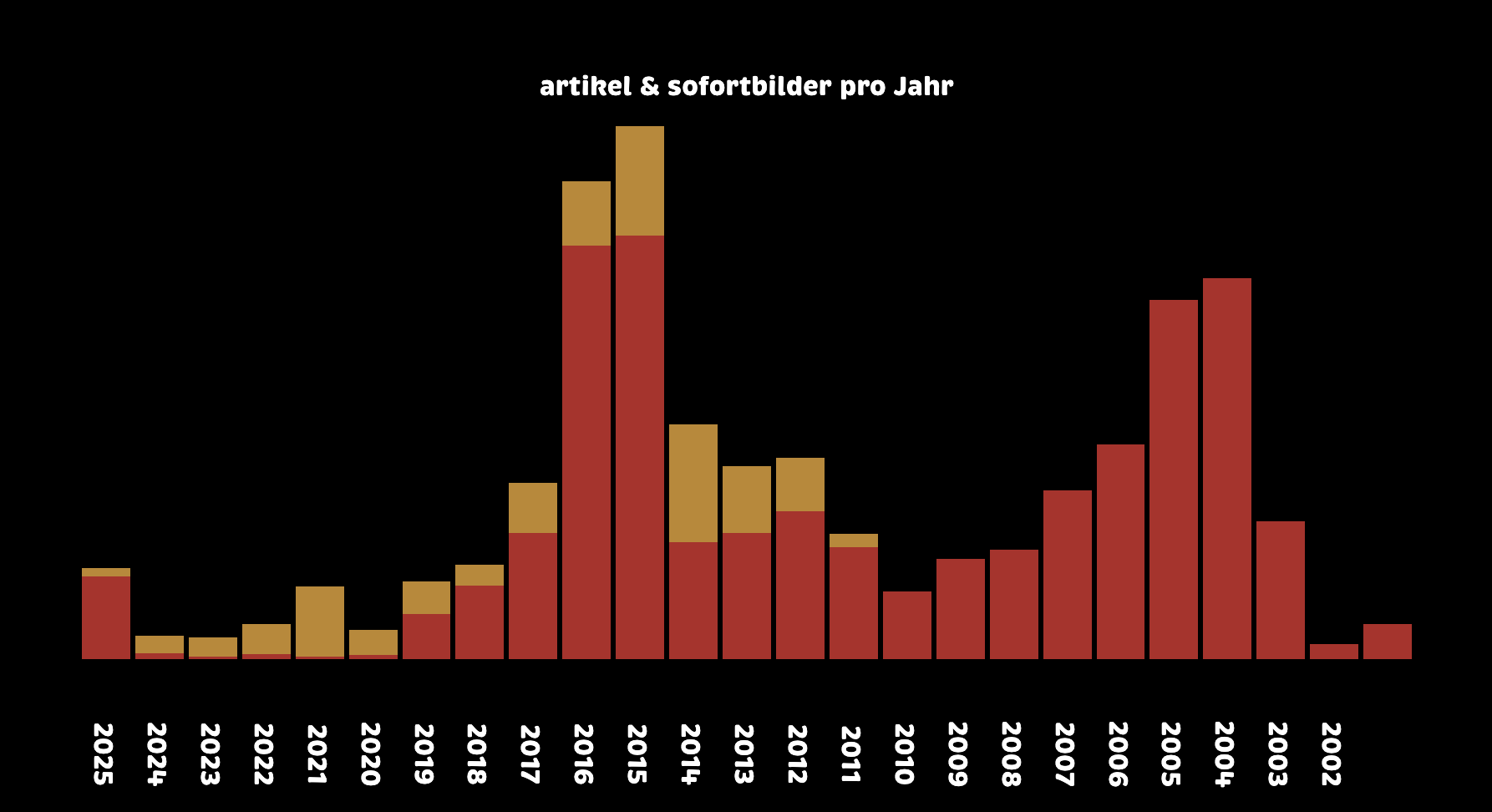
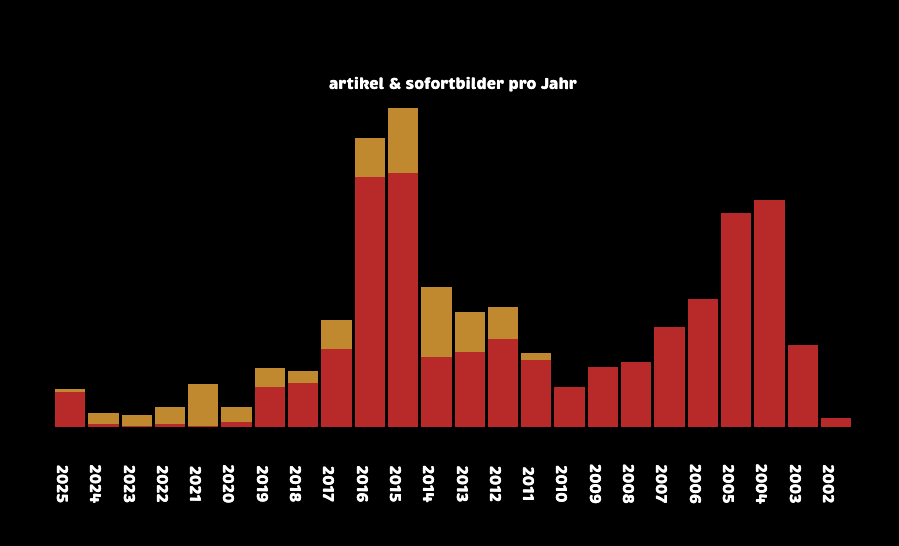
die ergänzung des archivs hat dazu geführt dass die dünnen, roten linien auf der artikel pro jahr grafik zwischen 2024 und 2020 pro jahr um jeweils vier artikel angewachsen sind. die gelben balken zeigen, dass ich in meiner blogpause von 2020 bis 2024 zwar einiges geinstagramt habe, aber eben kaum geschrieben.
beim oberflächlichen lesen der t3n kolumnen hab ich gemerkt, dass ich mich im lauf der jahre auch gelegentlich wiederholt habe, aber insgesamt hab ich den eindruck, dass die kolumnen relativ gut gealtert sind. diese kolumne („wuff, wuff“) ist noch nicht so alt, also auch noch nicht besonders gealtert, aber so würde ich sie wohl auch heute noch schreiben, man merkt ihr ein bisschen an, dass mir das ins internet schreiben ein bisschen fehlte.
auch in dieser kolumne („alles ist ein spiel“) liess mich die redaktion gedanklich mäandern, als schriebe ich hier ins blog. und trotzdem arbeite ich am ende eine idee heraus, die gar nicht mal so doof ist und die kolumne auf eine art zeitlos macht.
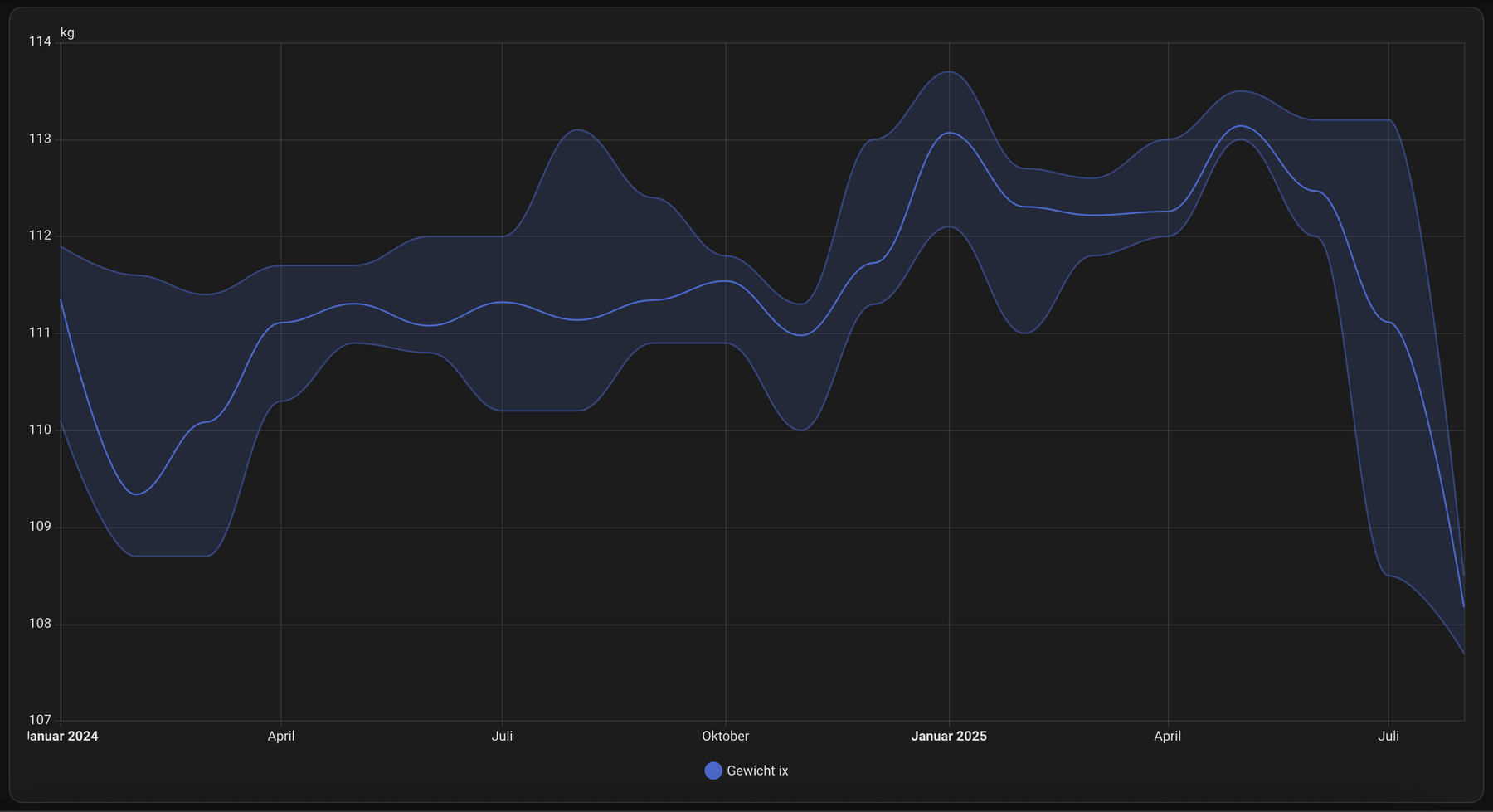
ansonsten hab ich jetzt eine woche, so wie ich mir das vorgenommen hatte, nicht weiter abgenommen, jetzt will ich sehen, ob ich das abnehmen wieder langsam in gang bringen kann.
frida hatte heute früh wieder, wie anfang der woche, eine blutblase am linken handgelenk, die püktlich beim tierazt aufplatzte. die tierärtzin steht diagnostisch genau wie wir auf dem schlauch, mal schauen ob gewebeproben im labor uns weiterbringen. frida trägt jetzt, zum schutz der wunde, wieder einen fussverband, aber es geht ihr gut und ich glaube, dass sie auch ohne schmerzmittel schmerzfrei wäre.













{kind=link}