beim medienbäcker kürzlich gesehen, dass seine überschriften angenehm animiert sind.
das wollte ich auch haben, also angefangen im quelltext zu graben. es zeigt sich, das sind nur ein paar zeilen code, um diesen effekt zu erzielen. im css:
damit werden die view transitions aktiviert, allerdings nur, wenn der benutzer in seinen systemeinstellungen nicht „reduzierte bewegung“ eingestellt hat.
elemente die man animieren möchte müssen über die seiten hinweg einfach den gleichen view-transition-name bekommen. in meinen kirby templates und snippets habe ich dafür gesorgt, dass alle <article> und <img> elemente den gleichen view-transition-name bekommen.
und das isses schon. funktioniert faszinierenderweise über seiten hinweg, chrome(ium) und safari können es, firefox noch nicht (über seiten hinweg) .
insgesamt laden alle seiten etwas weicher, weil ich meistens keine gekürzten artikel anzeige, ist die animation, finde ich, ziemlich subtil. lediglich im archiv, in suchergebnissen oder im bilder-grid auf der rückseite ist es etwas auffälliger.
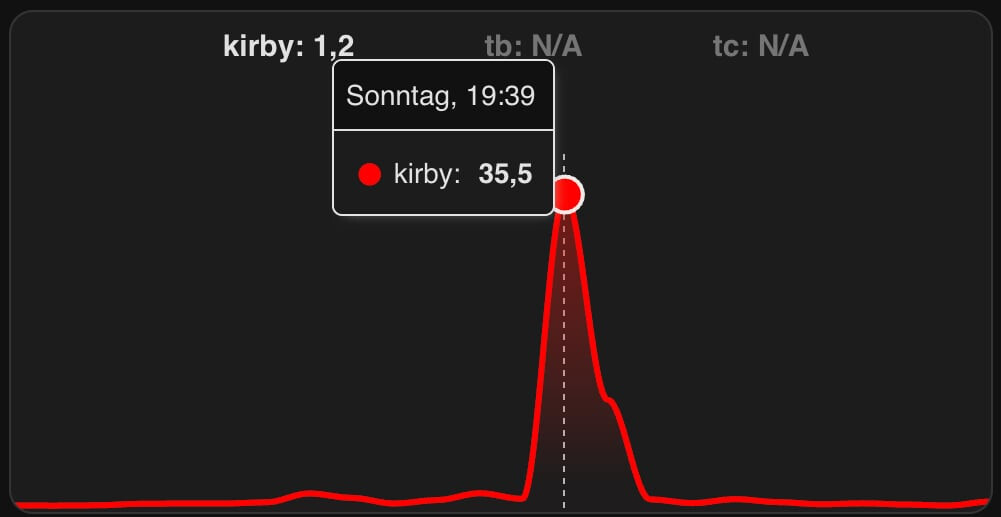
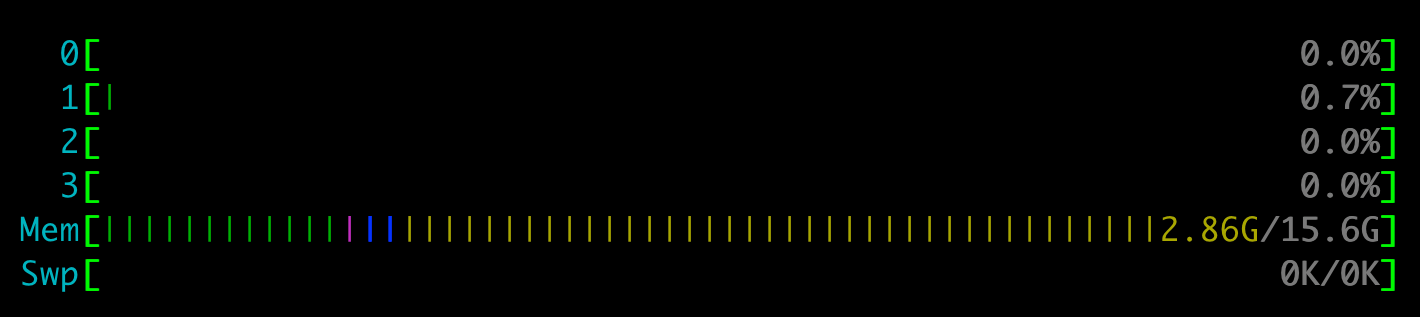
nur fürs protokoll; gestern abend, so gegen 20 uhr klemmte mein eigentlich (mittlerweile) super performantes blog (ja, dieses blog hier) und lud nicht mehr. ich sah eine prozessorauslastung (load average) in htop von > 30.00, die 4 CPU kerne waren dauerhaft auf 100%. im kirby fehlerlog sah ich sehr, sehr viele fehler (php timeouts). chat GPT diagnostizierte eine bot attacke mit asiatischen IP-adressen. einzelne IP adressen zu blocken brachte gar nichts.
was half: einmal kurz cloudflare einschalten. damit war der traffic sofort weg. nach 2 minuten habe ich es wieder deaktiviert und die bots blieben weg. offenbar hat cloudflare eine sehr abschreckende wirkung.
artikeltitel von uberspace geklaut (lesenswert und frustrierend, dass auch uberspace mit so einem schrott zu kämpfen hat und keine einfachen lösungen dazu hat).
volkers antwort auf meinen letzten beitrag, der ein KI generiertes symbolbild in „knete“ nutzte, lautete:
der „original“ felix reagierte auf kritik meist renitent oder spitzfindig. spitzfindig reagiert der aktuelle felix weiterhin. oder positiver ausgedrückt, ich reagiere auf kritik nachdenklich. und werde dann spitzfindig. in diesem fall, indem ich zunächst präzision bei der kritik einfordere. davon dass begriffe wie AI-slop von menschen „sloppy“ benutzt werden, war offenbar auch martin genervt und liess claude dazu argumente sammeln. das als antwort auf volker weiter zu verwenden wäre dann aber tatsächlich sloppy.
volker hat im kern natürlich recht. er ist genervt von der vermeintlich gedankenlosen verwendung von KI-werkzeugen zur bildgenerierung. ich bin teilweise auch genervt von der ästhetik dieser bilder und frage mich: warum, muss das sein? aber wirklich gedankenlos muss das nicht sein. der schockwellenreiter ist zum beispiel so freundlich die promts (und werkzeuge) zu nennen, die er zur KI-artikelbildgenerierung nutzt. hier zum beispiel:
Prompt: »Colored Franco-Belgian Comic Style. An elephant in a green dressing gown sits at a desk in front of an old-fashioned steampunk-style computer. The surrounding walls are lined with shelves filled with old books. In the background is a window overlooking a city. Through the window, a blimp can be seen in the sky. Sunlight floods the room.«. Modell: Nano-Banana.
der schockwellenreiter lässt sich bilder erstelllen, die seinen vorstellungen von passend, schön oder seinen assoziationen entsprechen (zur neuen version von libre office assoziert er aus unerfindlichen gründen „a sexy young woman with long red hair, green eyes and red lipstick“). ich gehe davon aus, er modifiziert die promts, wenn das ergebnis, das er geliefert bekommt, nicht seinen vorstellungen entspricht. nicht anders, als wenn er einen professionellen illustrator fragen würde, mit dem unterschied, dass hier kein honorar fliesst, sondern höchstens abo-gebühren.
der alte felix (das „original“?) hat früher symbolbilder gegoogelt (beispiel 1, beispiel 2). das birgt immer die gefahr in urheberrechtfallen zu tappen, öffnete aber gelegentlich die chance auf wirklich gute kalauer. manchmal habe ich gegoogelte bilder leicht modifiziert (beispiel 4), aber auch remixe bargen weiter die möglichkeit in urheberrechtliche fallen zu tappen. gelegentlich habe ich eigene fotos als symbolbild genutzt, manchmal führte das zu ganz guten text-bild-scheren (beispiel 5). weil meine illustrativen fähigkeiten nicht besonders weit reichen, sahen symbolbilder manchmal sehr, sehr simpel aus (beispiel 6). da half es dann auf vorgefertigtes zurückzugreifen, etwas, das man heute dann emoji-slop nennen könnte (beispiel 7). in diesem beispiel (8) bildete ich mir ein, urheberrechtliche probleme erfolgreich zu umgehen, indem ich statt eines prince CD-covers mit seinem foto, einfach die rückseite meiner lieblings CD nutzte. gaaanz selten gelang es mir die idee der symbolbilder auf eine metaebene zu heben, aber auf diese symbolbild-idee bin ich bis heute noch stolz: beispiel 9. gelegentlich verwies ich auf grandiose symboldbilder, die sich andere ausgedacht hatten: beispiel 10, beispiel 11.
waren meine symbolbilder früher besser? ich glaube nicht. nur die werkzeuge und quellen wandelten sich immer wieder. wahrscheinlich sind symbolbilder immer ein bisschen slop, also unnötiges beiwerk, deko. und dass die verwendung von KI-werkzeugen emotionen weckt verstehe ich auch in ansätzen, weil man diese bilder halt neuerdings überall sieht. aber andererseits verstehe ich es auch nicht.
ich habe heute mal einen schraubenschlüssel mit meiner neuen kamera fotografiert und freigestellt. hier der vergleich zwischen der foto-, emoji- (🔧) und ki-variante.
der witz ist natürlich, dass auch das foto mit KI-werkzeugen entstand. meine kamera benutzt KI zur erstellung, verarbeitung, verbesserung und die nachbearbeitung der bilder, der hersteller nennt die vorgänge und werkzeige hinter der fotoerstellung machine learning, neural engine oder „intelligence“. und auch das freistellen des schraubenschlüssels geschieht auf der kamera mit KI-werkzeugen.
so gesehen ist jedes einzelne foto das ich hier veröffentliche „AI-slop“. emoji werden auch nicht mehr per hand gezeichnet, da werkeln die designer mit ziemlicher sicherheit auch mit werkzeugen herum, die sie hier und da mit KI-funktionen unterstützen. so gesehen ist jede der oben gezeigten varianten meines symbolbilds irgendwie KI-durchseucht.
ich gebe zu: die schöpfungshöhe dieses und vieler anderer symbolbilder die ich hier benutze ist nicht sonderlich hoch. und die mühe, die ich zur illustration von texten aufwende ist im vergleich zum schreiben auch gering. insofern handelt es sich vielleicht um „slop“, im sinne von mangelnder sorgfalt. aber KI ist mittlerweile eben in fast allen lebensbereichen tief eingedrungen, in die fotografie, in film und fernsehen (vfx, spezialeffekte) und in die wissenschaften sowieso, mit enorm positiven folgen wie negativen folgen. der trick bei der fotographie und guten spezial effekten ist halt die KI-werkzeuge nicht schlampig (sloppy) zu verwenden, sondern so gekonnt, dass es niemand merkt, selbst KI-luditen nicht.
Hab von einem Kollegen über das PageSpeed Insights-Tool erfahren. Und konnexus.net darin ausprobiert.
interessant, dass konstantin das nicht kannte. ich bin seit über 20 jahren treuer kunde bei den PageSpeed Insights. ich bin ein grosser fan davon mir best practices anzusehen, also zu schauen wie man etwas richtig macht um dann das, was ich mache, entweder ein bisschen besser oder gar gut zu machen. deshalb schaue ich mir gerne videos von leuten an die sachen gut machen oder einfach ihre prozesse teilen.
das google tool testet ja nicht nur, um am ende zu einer bewertung zu kommen, sondern um auf potenzielle probleme und deren behebung hinzuweisen. und das finde ich nicht nur hilfreich, sondern befriedigt meinen drang dinge zu optimieren. ich scherze ja immer dass ich der prototypische dilettant bin, oder weniger selbstkritsch, dass ich alles ein bisschen und nichts richtig kann. perfektionismus meide ich, aber ich optimiere sehr gerne. ich mag es dinge relativ zu verbessern, nicht absolut. und die PageSpeed Insights-Tool helfen mir dabei enorm.
die ergebnisse von solchen benchmarks zu veröffentlichen, also zum beispiel die leistungs-, barrierefreiheits- oder seo-indexe des google tools, aber auch die ergebnisse von quizzes oder IQ tests nenne ich ab heute benchbarking. das ist kein schreibfehler, sondern ein wortspiel, das sich laut google offenbar noch niemand vor mir ausgedacht hat.
deshalb benchbarke ich jetzt auch mal eine momentaufnahme meiner PageSpeed Insights ergebnisse, auch weil ich in den letzten tagen wieder einiges optimiert habe:
bilder werden jetzt (fast) durchgehend in modernen formaten (avif, webp) und nochmal grössen-optimiert ausgeliefert.
ich liebe lazyloading, aber above the fold mag google das gar nicht, weshalb jetzt die ersten 3-4 bilder einer seite „eager“-laden.
Performance 95% — das variert allerdings, je nachdem was above the fold ist und manchmal reagiert der server doch noch mit ein paar ms verzögerung. die „desktop“-messung ergibt jedoch fast immer 100%.
Accessibility 86% — noch eine baustelle, aber dass ich an der 90 kratze zeigt, ich geb mir mühe.
Best Practices 82% — variert komischerweise auch immer wieder, ich glaube das tool ist da auch ein bisschen launsisch
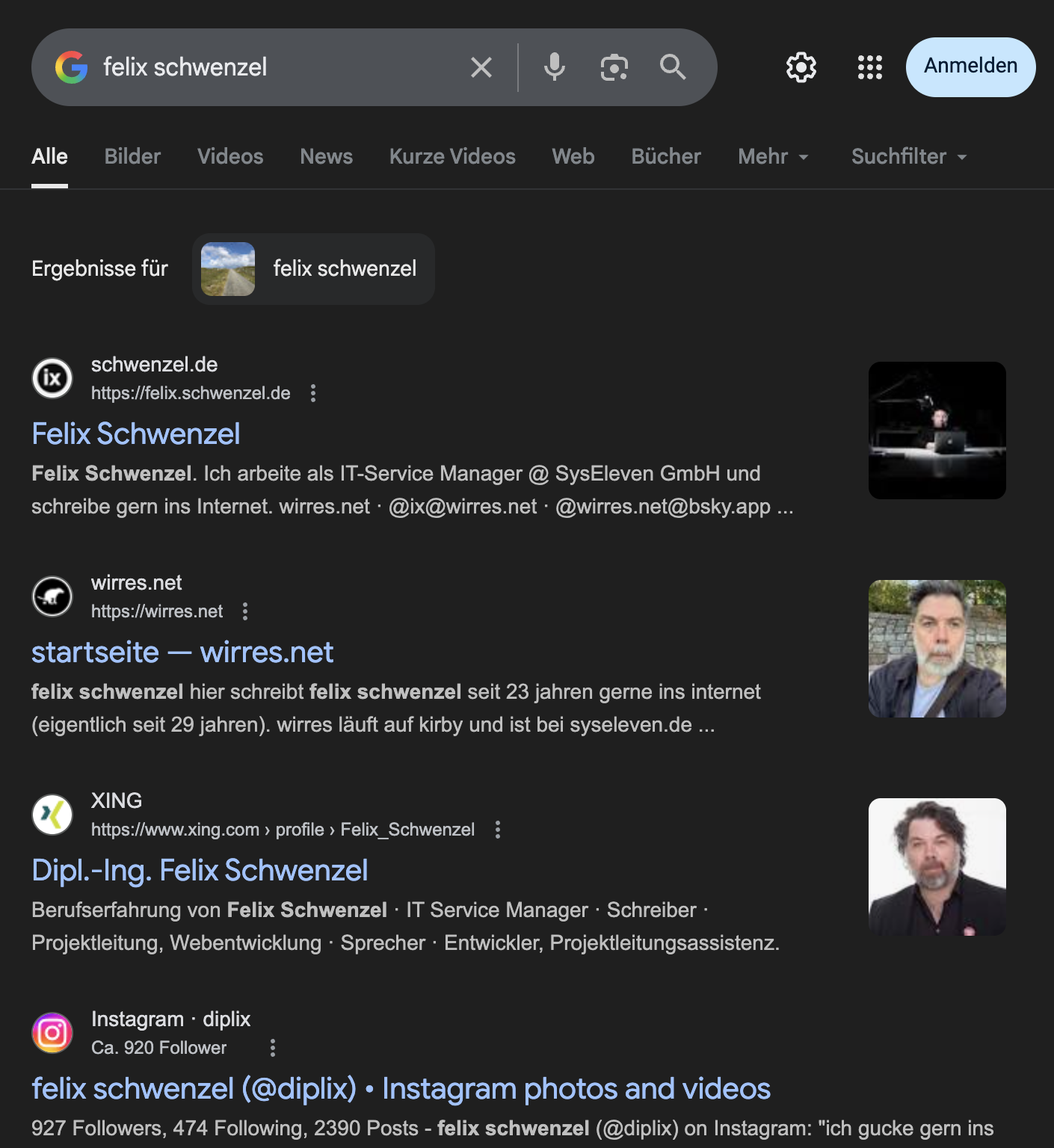
nach fünf jahren blogpause ergab eine suche nach „felix schwenzel“ ein katastrophales bild. an erster stelle mein stillgelegtes twitter-profil, dann in loser, wechslnder folge instagram, threads, xing oder linkedin. meine seiten, wirres.net und felix.schwenzel.de ganz weit hinten auf folgeseiten. es hat von april bis vor ungefähr mitte september gedauert, bis eine google (oder duckduckgo) suche nach „felix schwenzel“ wieder annehmbare ergebnisse ergab. jetzt ist wechselnd felix.schwenzel.de oder wirres.net (wieder) an erster stelle.
beim alten wirres.net hatte ich seiten die älter als 5 jahre sind und übersichtsseiten von der suche (oder genauer von der indexierung durch suchmaschinen) ausgeschlossen. beim neustart im april diesen jahres auf kirby habe ich sowohl die übersichtsseiten, als auch die startseite von der indexierung ausgeschlossen. beitragsseiten habe ich suchmaschinen per sitemap mitgeteilt — ausser beiträge die älter als fünf jahre sind (mit manuell gesetzten ausnahmen).
darauf hat google sehr allergisch reagiert. mein gedanke war: die übersichtsseite ändert sich so oft, dass google gar nicht hinterherkommt. aber google ist ja nicht von gestern und macht das, wie man auf dem screenshot sieht schon ganz gut. seitdem google ein paar übersichtsseiten tief in die website reinindexieren darf, ist es auch wieder nett zu mir. ab übersichtsseite 5 ist aber schluss und artikel die älter als 5 jahre sind, schliesse ich weiterhin aus.
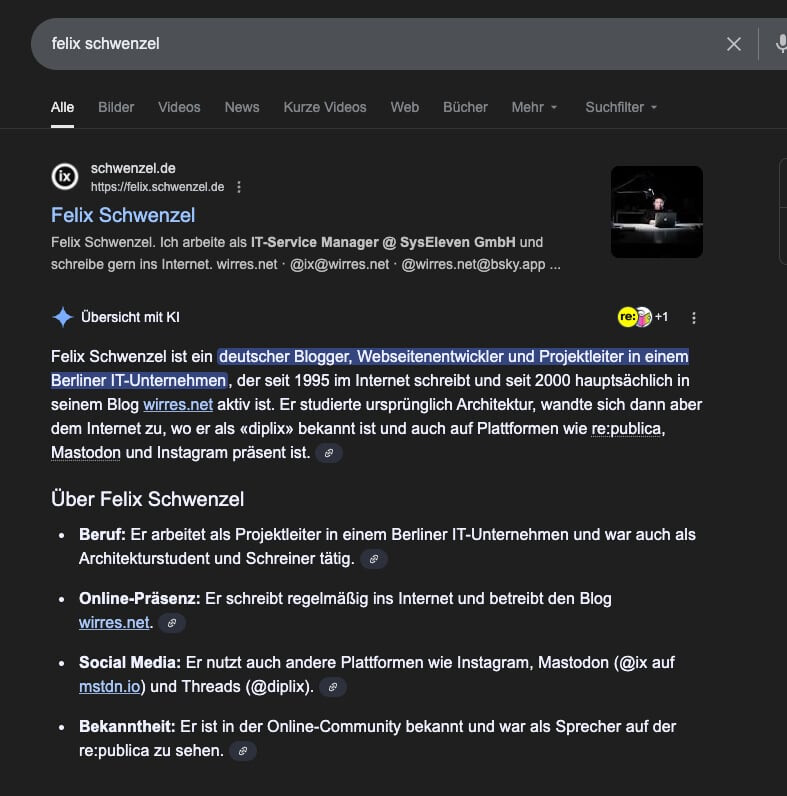
die KI zusammenfassungen die manchmal, aber manchmal auch nicht am anfang der suchergebnisseite stehen, sind teilweise ganz ok, teilweise totale missverständnisse.
die KI zusammenfassung über mich ist ganz OK, wenn auch nicht 100% akkurat.
die KI zusammenfassung über die bedeutung von „fachblog für irrelevanz“ ist totaler quatsch.
apropos irrelevanz, ich weiss, google suchergebnisse sind schon lange nicht mehr entscheidend, aber ich bin froh, dass man mit etwas mühe google und andere suchmaschinen dazu bringen kann die suchergebnisse ein bisschen um zu sortieren. warum twitter von google allerdings immer noch für relevant gehalten wird bleibt mir ein rätsel.
apropos suche. ich bin ja ganz zufrieden wie die interne suche hier funktioniert. dahinter steckt loupe, bzw. ein plugin der loupe im hintergrund nutzt. aber leider geht der such-index gelegentlich kaputt wie ich gestern merkte. der indexierungsprozess dauert so um die zwei stunden, vielleicht solle ich das alle paar wochen per cron job in der nacht triggern.
nachtrag:
kaum schreibe ich drüber, ist wirres.net wieder aus den suchergebnisseiten verschwunden (auf seite 4). sehr volatil alles. ich habe die startseite und die übersichtsseiten von wirres.net allerdings gestern umbenannt. vielleicht braucht es etwas zeit, bis sich der schock für google wieder einrenkt. ansonsten auch schön, dass ich jetzt zumindest screenshots habe, die zeigen: wirres.net war mal ganz weit vorne.
dass markus am 24. september keinen eintrag geschrieben hat, liess mich auch gestern nicht los und ich hab keinen beitrag bei mir noch etwas „verbessert“ mit „soundcite“. das kann dann so aussehen (funktioniert mit javascript, also nicht per RSS):
als vor einigen jahren eins von donald trumps vorbildern, walter ulbricht, sagte:
niemand hat die absicht eine mauer zu errichten.
… war das ein wichtiger moment in der geschichte des regierungsnahen lügen. (audioquelle)
ausserdem sind mir noch zwei sehr alte artikel untergekommen, die nicht mehr funktionierten und die ich reparieren musste. die artikel nutzen „juxtapose“, so eine art slider, mit dem man vorher nachher bilder ansehen kann. beispiele hier und hier. wird auch nicht per RSS funktionieren, aber mal schauen ob das auch als einbettung funktioniert:
die fake bauakademie ist ja schon lange wieder verschwunden. bei meinen bauarbeiten hilft mir jetzt claude sonnet 4, das schien anfangs beeindruckend fähig, hat mich aber heute wieder dazu gebracht, mir zwei bis drei stunden vollmundige versprechen anzuhören, die am ende zu nichts geführt haben, zu komplex, so dass ich ein feature wieder einstampfen musste. dafür ist claude, wie man hier sieht, mit noch mehr will to please ausgestattet, als chatGPT.
als ich vor zwei monaten das hosting von wirres.net von uberspace zu meinem arbeitgeber umgezogen habe, hatte ich auch wieder cloudflare aktiviert (vor 5 monaten hatte ich es abgeschaltet). der gedanke dahinter war, wirres.net auch per IPv6 auszuliefern, weil die VM auf der wirres.net läuft bisher nur IPv4 kann und cloudflare das überbrücken kann, bzw. IPv6 bedient.
seit zwei monaten beobachte ich aber zuhause immer wieder (sehr) langsamen seitenaufbau von wirres.net. das hat einerseits dazu geführt, dass die wahnsinnig viel am setup optimiert (und gelernt) habe, aber trotzdem weiterhin, insbesondere in den abendzeiten, wahnsinnig langsamen seitenaufbau und downloads beobachtet habe. wenn ich wirres.net per LTE aufrief, also aus dem O₂-netz, fluppte es ganz gut.
zwischenzeitlich hatte ich deshalb meinen DSl-anschuss und unser WLAN im verdacht. messungen zeigten aber, dass sowohl das WLAN, als auch das (telekom) DSL einwandfrei bis sehr gut funktionieren. DSL liefert sogar ein drittel mehr als die gebuchten 50 mbit/s. chatGPT hatte, wie viele menschen in diversen online-foren, den verdacht, dass das problem beim peering zwischen cloudflare und der telekom liegen könnte.
messungen mit mtr -rw -c 100 wirres.net zeigten, dass tatsächlichh zwischen dem telekom-netz und cloudflare massive paketverluste auftreten. die verschwanden, sobald ich cloudflare ausschaltete. jetzt ist also wieder alles wie es sein soll. wer wirres.net aufruft spricht direkt mit einer VM die allein ich kontrolliere, bei syseleven liegt und mittlerweile ganz gut optimiert ist und nicht gerade schwachbrüstig ist — aber dafür noch kein IPv6 kann.
IPv4 sollte aber kein problem sein und ich hoffe, dass wirres.net jetzt tatsächlich so schnell überall ankommt, wie es ankommen soll.
cookies und fremdtracker oder code von dritten sind hier auch weiterhin nirgendwo vorhanden.
es zeigt sich, dass die knapp 10.000 toten links die mein script zum auffinden von toten links gefunden hat noch lange nicht ausreichen (siehe mein vorheriger artikel zu toten link). ich habe heute ein bisschen im archiv von 2007 und 2008 rumgeschaut und so viele weitere tote links entdeckt, dass ich mit meinem programmierhelfer ein script zum leichten nachpflegengeschrieben habe.
links zu vielen zeitungen (faz vor allem) leiten auf die aktuelle startseite weiter und irgendwie hab ich weiterleitungen nicht als potenzielle tote links im suchscript berücksichtigt. das gleiche passiert mit domains die aufgegeben wurden und jetzt zum kauf angeboten werden, auch die flutschten unter dem detektor durch. flash ist auch so ein problem. archive.org nutzt zare einen flash emulator, aber viele oder gar die meisten flash-inhalte funktionieren dann trotzdem nicht. aber flash war schin immer eine schlimme krankheit des webs, insofern hat sich da nichts geändert in den letzten 20 jahren.
jedenfalls werden jetzt die kaputten links die ich gefunden habe alle zur laufzeit angepasst. ich habe das jetzt doch etwas subtiler markiert als zuerst geplant.
tote links mit einem ersatz-link auf archive.org sind jetzt subtil blau markiert, tote links ohne archivierten snapshot rot. beispiele:
wie immer faszinierend was ich so beim stöbern im archiv (wieder) entdecke. an diesen witz von 2007 (gedächtnistraining) erinnert sich weder die beifahrerin noch ich. und ja, es gab mal eine sehr kleine riesenmaschine (auch 2007).
solche witze habe ich früher sehr gerne gemacht: „auf deutsch hiesse alfred hitchcock übrigens alfred ruckpimmel“
oder wie minimalsitisch die twitter snapshots von archive.org sind: ix ist doof (aus following 3000) — wobei das wohl auch technische probleme beim snapshotten gewesen sein müssen.
so oder so, ein anfang ist gemacht. stand jetzt 6848 links sind mit archive.org-links repariert. ca. 3000 als nicht mehr verfügbar gekennzeichnet. und wahrscheinlich ein paar hundert weitere wollen (irgendwann) noch gefunden werden.
mein liebstes hobby ist mich intensiv mit komplexen technischen systemen zu beschäften, sie zu verstehen, an meine bedürfnisse anzupassen und dann bestmöglich am laufen zu halten und ständig zu verbessern oder zu überarbeiten. den vergleich mit dem leben, in dem man die ersten 20 jahre damit verbringt das ganze system zu verstehen und sich anzupassen oder seine bestmögliche funktion zu finden und das ganze dann möglichst lange am laufen zu halten durch stetige optimierung und anpassung, den vergleich spar ich mir jetzt oder verfolge ihn nicht weiter.
was ich mit dieser website, diesem sehr komplexen system, am meisten beschäftigt, ist sie am leben zu halten indem ich sie fülle, aber genauso sie ständig zu reparieren, fehler zu finden und sie für mich (und gegebenenfalls andere) optimal nutzbar zu machen. ein nicht endender, prozess, dessen zwischenergebnisse mich stets erfreuen.
Das letzte Lebenszeichen: 13 Jahre her. Das aktuelle Design: 19 Jahre alt. Diese Site war mal mein ganzer Stolz. Zeit, ihr neues Leben einzuhauchen …
Schritt 1: Entropie zurücksetzen!
um’s kurz zu machen: frank beschreibt konkret, wie er alte, über die zeit verwaiste links restauriert hat. das thema „broken links“ verfolgt mich auch schon länger und erst recht seitdem ich diese seite wiederbelebt habe und ziemlich verlustfrei aus einem veralteten system in ein neues system migriert habe. mein archiv, die seiten die schon ein paar jahre auf dem buckel haben, sind (natürlich) voll mit links die nicht mehr funktionieren.
bisher habe ich das einfach hingenommen und gelegentlich die url des „broken links“ in die wayback machine eingegeben und nach gefühlt 13 klicks die alte website bestaunt, auf die ich vor x jahren mal gelinkt habe.
auf die idee das systematisch zu tun bin ich noch nicht gekommen. aber was für eine grossartige idee:
Veraltete Links [sind] um Längen besser als Löschen oder Abschalten. Tote Links sind belegende Artefakte, kein Mangel – richtig gekennzeichnet, zeigen sie Quellenlage. So lassen sich Inhalte oft noch rekonstruieren – über die URL, über Archive, über Kontext.
ich hab mich gleich nach dem lesen an die arbeit gemacht. meine programmier-helfer (chatGTP) hatte zuerst etwas wilde ideen um das in kirby umzusetzen, aber nach ein bisschen hin und her haben wir uns auf eine strategie geeinigt, die mir gefällt.
erstmal alle toten links sammeln (in einer json datei)
für diese toten links dann anhand des artikel-datums einen zeitlich passenden archiv-snapshop imn archive.org finden (auch in json)
zur „laufzeit“ die kaputten links mit den reparierten links ersetzen und kennzeichnen
alle 13.475 beiträge zu prüfen (mit 51.735 externen links) hat ein script 12 stunden lang beschäftgt. vorläufiges ergebnis: von den ca. 50.000 links sind ungefähr 10.000 kaputt.
für diese 10.000 links die entsprechenden snapshots auf archive.org zu finden ging schon etwas schneller (8 stunden), bzw. das script läuft noch.
über das rendern der reparierten links muss ich mir noch gedanken machen, derzeit tendiere ich zu farblicher kennzeichnung, statt einer kennzeichnung mit dem archive.org-logo wie bei frank.
das problem von webseiten ist natürlich (u.a.), dass man ihnen das alter nicht ansieht. wenn webseitenbetreibende nicht unter einem stein schlafen, kann man der seite zwar meistens das alter entnehmen, aber man sieht, riecht oder fühlt es nicht, wie man es mit gealtertem papier beispielsweise tut. strenggenommen müsste man alte webseiten eigentlich so anzeigen, wie sie zum veröffentlichungszeitpunkt ausgesehen haben, aber das ist natürlich auch wieder quatsch, bzw. eine zumutung. ich hab mir immer vorgestellt, dass webseiten wie laub altern könnten, also richtung braun altern. bis jetzt bin ich damit zufrieden, alte seiten oben mit dem alter in jahren anzuzeigen.
aber da werde ich wohl noch ein bisschen denkarbeit investieren müssen.
was mir beim testen der archive.org api und link-konstruktion um alte snapshots zu finden jedenfalls auffiel ist die begeisterung die mich ergriff, als ich manche alten webseiten mit ihrer elektronischen patina (wieder) sah. elektronische patina sind broken images, schrottiges, kantiges design und mobiltelefon-feindlichkeit. oder bei frank westphal, der gute alte schlagschatten, den damals irgendwie fast jeder benutzte, weil es auf den grobpixeligen bildschirmen die wir zu dieser zeit nutzten „natürlicher“ aussah.
jedenfalls spannende neue denkaufgabe und ein weiterer toller baustein bei der ewigen reparatur von wirres.net. danke frank.
hier zu schreiben fällt mir ziemlich leicht. man sagt mir nach, dass ich texte hier hinrotze und da ist wahrscheinlich auch was dran. ich schreibe hier in gewissem sinne hemmungslos; wenn der eine oder andere gedanke noch nicht zuende gedacht ist, hält mich das nicht davon ab ihn aufzuschreiben. gelegentlich reifen die gedanken während des schreibens, manchmal danach oder ich greife sie später (oder nie) wieder auf.
texte die ich im auftrag schreibe oder gegen geld, muss ich mir hingegen aus der nase ziehen. ich spüre den druck alle gedanken am ende des textes zuende gedacht haben zu müssen, ich presse oft, statt es fliesen zu lassen. trotzdem habe ich es bis anfang letzten jahres fast 10 jahre durchgehalten eine kolumne für die (gedruckte) t3n zu schreiben.
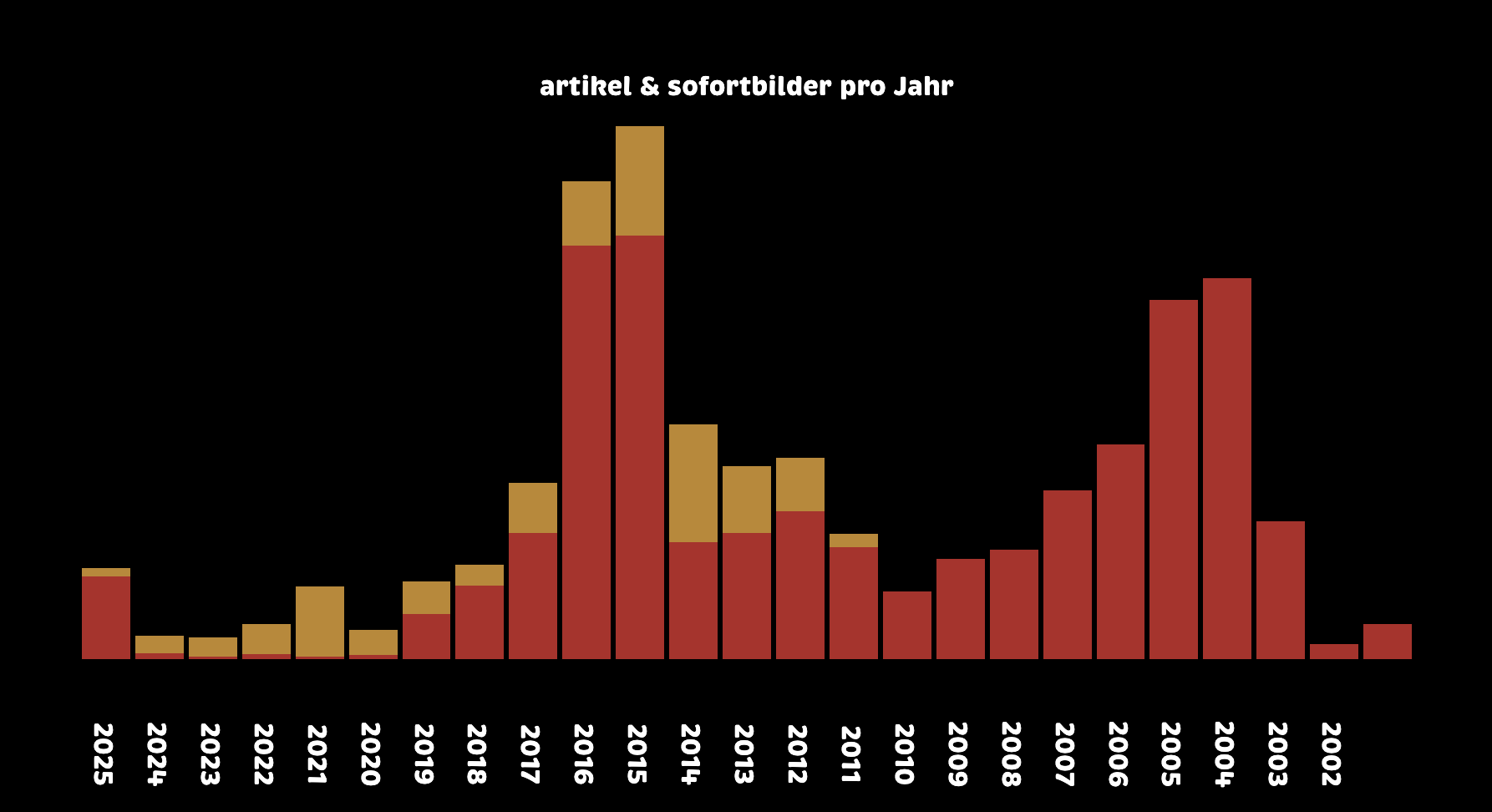
heute habe ich versucht die noch fehlenden artikel hier zur archivierung zu ergänzen und neu und konsistent zu kategorisieren (kategorie t3n).
(nachtrag: experimentelle raster-übersicht über die t3n kolumnen)
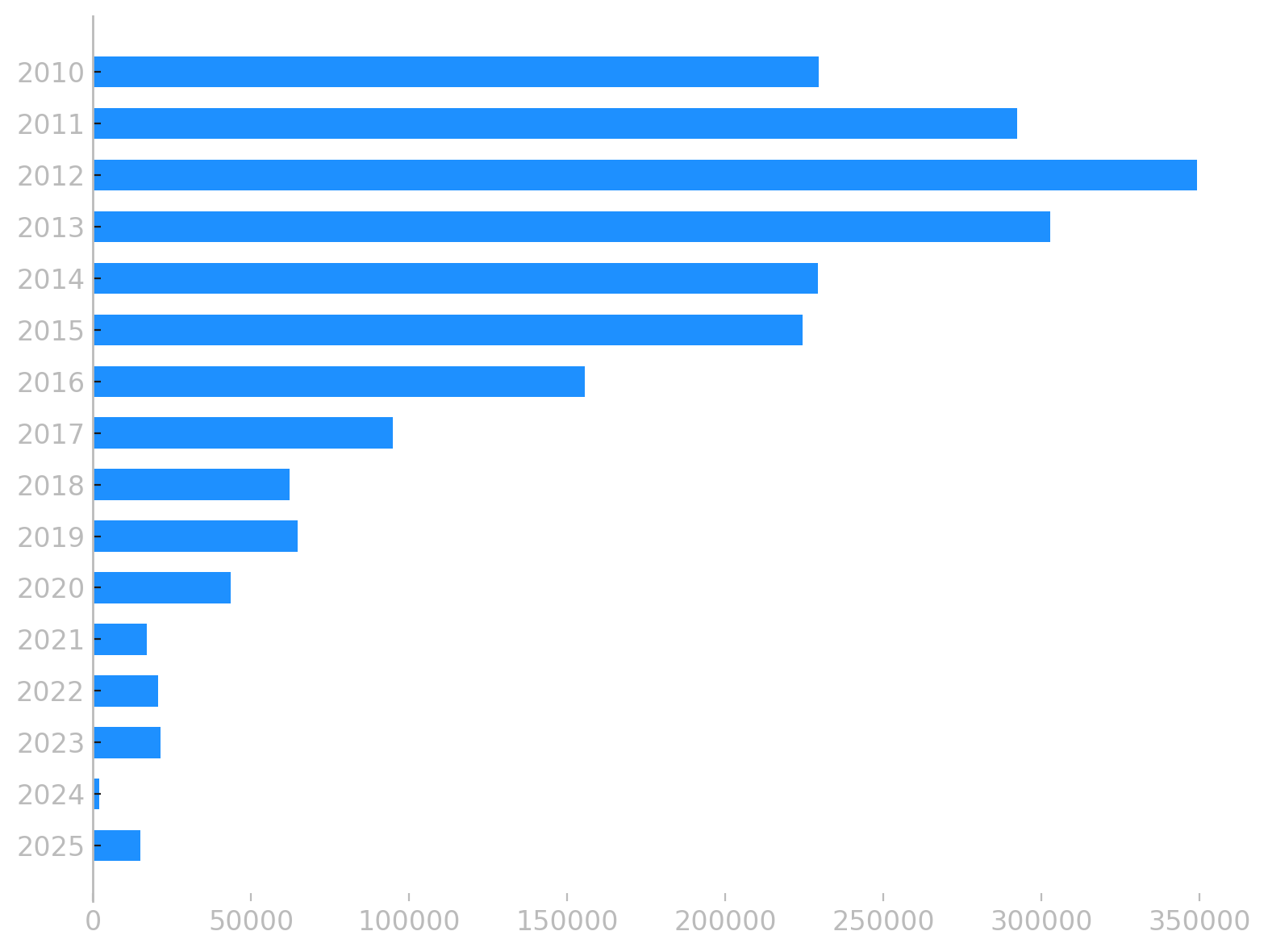
die ergänzung des archivs hat dazu geführt dass die dünnen, roten linien auf der artikel pro jahr grafik zwischen 2024 und 2020 pro jahr um jeweils vier artikel angewachsen sind. die gelben balken zeigen, dass ich in meiner blogpause von 2020 bis 2024 zwar einiges geinstagramt habe, aber eben kaum geschrieben.
beim oberflächlichen lesen der t3n kolumnen hab ich gemerkt, dass ich mich im lauf der jahre auch gelegentlich wiederholt habe, aber insgesamt hab ich den eindruck, dass die kolumnen relativ gut gealtert sind. diese kolumne („wuff, wuff“) ist noch nicht so alt, also auch noch nicht besonders gealtert, aber so würde ich sie wohl auch heute noch schreiben, man merkt ihr ein bisschen an, dass mir das ins internet schreiben ein bisschen fehlte.
auch in dieser kolumne („alles ist ein spiel“) liess mich die redaktion gedanklich mäandern, als schriebe ich hier ins blog. und trotzdem arbeite ich am ende eine idee heraus, die gar nicht mal so doof ist und die kolumne auf eine art zeitlos macht.
ansonsten hab ich jetzt eine woche, so wie ich mir das vorgenommen hatte, nicht weiter abgenommen, jetzt will ich sehen, ob ich das abnehmen wieder langsam in gang bringen kann.
frida hatte heute früh wieder, wie anfang der woche, eine blutblase am linken handgelenk, die püktlich beim tierazt aufplatzte. die tierärtzin steht diagnostisch genau wie wir auf dem schlauch, mal schauen ob gewebeproben im labor uns weiterbringen. frida trägt jetzt, zum schutz der wunde, wieder einen fussverband, aber es geht ihr gut und ich glaube, dass sie auch ohne schmerzmittel schmerzfrei wäre.
ich habe über jahre likes, retweets/reposts oder shares von beiträgen hier auf wirres.net gesammelt und lokal in json-dateien gespeichert. vor einer weile hatte ich die auch reaktiviert, bzw. deren anzeige unter den alten artikeln aktiviert. obwohl diese signale sozusagen einen historischen wert haben, hatte ich das gefühl dass sie nicht mehr nachvollziehbar oder angemessen sind. früher kamen diese signale vor allem von zwei plattformen, die ich schon länger nicht mehr nutze: twitter und facebook. ich fand die artikelranglisten, die ich mit diesen historischen signalen erstellte, auch nicht wirklich hilfreich und verzerrend. also hab ich diese historischen social media signale wieder deaktiviert.
die signale die ich noch einsammle sind die likes von instagram, sowie die likes, reposts und kommentare von mastodon und bluesky. das funktioniert natürlich nur, wenn ich die beiträge jeweils dort veröffentlicht oder angeteasert habe. ausserdem gibt’s (auf der artikel-beilage) eine kommentarfunktion und seit ein paar wochen auch einen shit vote („i like that shit“) deren idee ich mir von den toast votes der bear blogs abgeschaut habe.
über die nützlichkeit oder gar relevanz solcher signale kann man natürlich streiten. man könnte argumentieren, dass solche feedback loops dazu animieren gefälliger zu schreiben. dieses argument meine ich auch schon öfter in bezug auf page-counter oder besucher-statistiken gehört zu haben, halte es aber für quatsch. die entscheidung so zu schreiben, dass es möglichst vielen leuten gefällt, möglichst viele klicks oder likes generiert ist ja eher konzeptionell.
man entscheidet sich entweder etwas mit einer breiten zielgruppe zu machen, sich an ein massenpublikum zu richten oder eben gerade nicht.
statt ein logo mit einem kackenden hund zu benutzen, statt kleinschreibung und schlampiger orthographie und zeichensetzung, könnte ich meine webseite auch „das könnte dir nicht gefallen“ untertiteln. in diesem sinne habe ich diese seite auch lange zeit „fachblog für irrelevanz“ genannt. die abschreckung von lesern auf den ersten blick ist teil des konzepts dieser webseite. das ändert nichts daran, dass ich mich trotzdem dafür interessiere wie und gegebenenfalls warum das was ich hier schreibe und zeige rezipiert wird.
umgekehrt würde ich mich freuen, wenn ein reibungsfreier, barrierearmer toast, like oder whatever button überall in blogs vorhanden wäre, wo man einfach per klick, ohne anmeldung, ohne komplikationen ein „gefällt mir“ oder eine applaus-geste hinterlassen kann. ok, ich gebe zu, eine hürde hat auch meine shit/like-button implementierung: javascript muss aktiviert sein, damit es funktioniert.
die auswertung dieser signale ist aber höchstwahrscheinlich nicht nur für mich interessant, ich kann mir auch vorstellen das es für andere hilfreich sein kann zu sehen, was in den text- und bildwüsten die ich hier (wieder) täglich produziere von interessanz sein könnte.
deshalb habe ich meine /top seite gebaut, die alle beiträge listet die mehr als 10 likes bekommen haben.
wenn man die schwelle höher legt und nach beträgen mit > 25 likes filtert, bekommt man 11 seiten oder ungefährt 250 beiträge, die bis 2012 zurückreichen. 2025 habe ich 7 beiträge verfasst die diese aufmerksamkeitsschwelle überschritten haben. für die nach > 10 likes gefilterte version dieser webseite gibt’s natürlich auch einen rss feed, der beiträge dann zeitversetzt und gefiltert liefert. (mehr beitrags-statistiken findet man übrigens auf der rückseite)
ich bin mittlerweile in einem flow, in dem ich auch ohne jedes feedback oder besucherstatistik weitermachen würde und meine gedanken, bilder oder erlebnisse hier festhalten würde, so wie ich auch ohne frida weiter durch die stadt spazieren würde. aber mit hund, mit ein wenig applaus, macht es mehr spass und inspiriert und öffnet neue perspektiven.
auch wenn die zeichnung nach wie vor scheisse ist (scnr), finde ich die zeichnung der neuen variante einen ticken besser. aber leider funktioniert die neue variante in klein, im schriftzug, nicht. der alte kantige hund sieht in klein einfach besser aus. bleibt also alles beim alten. sollte ich wirres.net jemals ausdrucken, nehm ich dann aber das neue logo.
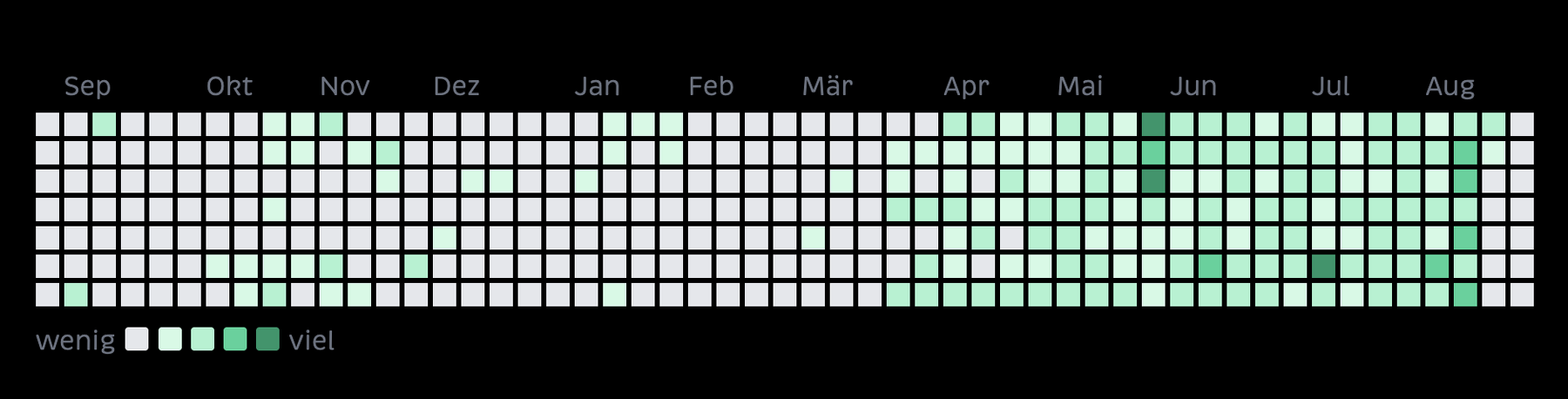
gestern habe ich hier einen „Post Graph“ gesehen, der eigentlich ein plugin für eleventy ist. ich wollte das auch haben und habe chatGPT gefragt ob wir das gemeinsam bauen könnten. es kam mit einer ganz guten lösung um die ecke, die ganz anders als das eleventy-plugin aussieht und funktioniert, nämlich mit täglichen feldern, farbverläufen, bzw. heatmap-funktionalität und verlinkung auf den jeweiigen tag. im original ist die äuflösung nur nach wochen, der graph einfarbig und die wochen nicht verlinkt. aber chatGPTs vorschlag gefiel mir, auch wenn wir noch ein bisschen dran feilen mussten, ging das ultra-schnell.
weil der post graph tage verlinkt, musste ich mein archiv noch ein bisschen aufbohren. dort ging bisher sowas:
den post graph habe ich auf der rückseite eingebaut. weil er nicht adaptiv ist (das original offenbar auch nicht), blende ich ihn für bildschirmgrössen > 1200 px aus.
/slashes sind eine idee von flamedfury.com um eine persönliche website und die person dahinter zu beschreiben. ja, ja, das ist keine wirklich neue idee, seit es webseiten gibt, gibt es seitenangaben in der url die mit einem slash beginnen und zu einer bestimmten seite führen: /kontakt, /impressum, /about, etc.
tatsächlich hatte ich das schon vor 15 jahren im kopf meiner website (versteckt hinter einem aufklapper, screenshot), wobei ich da den eindruck hatte, dass das ausser mir niemanden interessierte und auch niemand verstand.
jetzt sind slashes ein ding und ich glaube, dass eine übersicht über die slashes tatsächlich helfen kann eine webseite, ihren hintergrund und macher etwas besser zu verstehen. viele slash-seiten sind über aliase zu erreichen, bzw. eine bestimmte seite kann oft über mehrere wege erreicht werden.
heute beim duschen kam mir eine idee: warum nicht eine seite (und entsprechenden RSS feed) bauen, die nur beiträge anzeigt die eine bestimmte anzahl likes bekommen haben. wirres.net kuratiert von den lesern die das kleine 💩 am artikelende klicken oder auf mastodon oder bluesky oder instagram beiträge liken. ausserdem könnte ich so einen (weiteren) RSS feed anbieten der ruhiger und zeitversetzt ist.
beiträge würden im feed erst nach ein paar tagen erscheinen, das beittragsrauschen ist reduziert und im feed sind nur beiträge, die eben von ein paar leuten — und nicht nur mir — gut gefunden wurden.
die umsetzung, mit einer kirby collection und etwas filtermagie, hat 15 minuten gedauert, den feed zu bauen nochmal 10 minuten. die seite ist wirres.net/top und der feed wirres.net/feed/top
auf der seite kann man die anzahl der mindest-likes anpassen, der feed bleibt bei 10.
apropos rss, ich habe dazu eine unübersictliche übersichtsseite angelegt: wirres.net/folgen
ich habe in den letzten tagen ein paar änderungen eingebaut, über die ich mich sehr freue.
statt der nativen kirby suche nutze ich jetzt kirby loupe das auf loupe php basiert und sehr viel besser funktioniert als die native kirby-suche (stemming, sqlite index, geo-suche inkludiert, usw.)
weil php loupe eben auch geosuche mit such-radien kann, ist die eigene geosuche überflüssig. mich freut das, weil ich so schnell zum beispiel nach bildern unserer moskau-reise vor 9 jahren suchen kann. das geht zwar mit normalem suchtext auch, aber das findet noch duplikate, bis ich das aufgeräumt habe.
weil ich gelegentlich bemerkte dass bilder hier nicht so schnell laden wie ich mir das wünsche, habe ich mal kirby thumbhash ausprobiert. ich finde das sehr schün, wenn sich bilder progressiv aufbauen. und auch die grundsätzliche idee hinter thumbhash oder blurhash finde ich faszinierend: ein foto einfach mit ein paar byte vereinfacht darzustellen finde ich umwerfend. ich hoffe bei der umsetzung keine groben schnitzer eingebaut zu haben, aber theoretisch sollte alles auch ohne aktiviertes javascript funktionieren. auch im RSS feed sollte sich (hoffentlich) nix verändert haben.
ich habe die navigation etwas aufgeräumt, die geosuche konnte weg, bilder im grid und mit infinite scroll sind dort jetzt verlinkt. was noch nicht verlinkt sind die experimentellen chackins die ich dort mit ownyourswarm per micropub veröffnetliche. wenn das bald hoffentlich zuverlässig funktioniert, ist ein checkin mit swarm wahrscheinlich die einfachste möglichkeit bilder oder galerien auf wirres.net zu laden und zu veröffentlichen.
animation zwischen geblurrhashten oder gethumbhashten bild und dem normalen bild
eigentlich wollte ich beim neustart von wirres.net ja etwas minimalistischer bleiben, aber je länger ich mit minimalismus konfrontiert bin, desto grösser wird mein bedürfnis es weniger minimalistisch zu machen. ich achte zwar (relativ) peinlich drauf, dass alles auch mit deaktiviertem javascript und/oder css funktioniert und insgesamt nicht zu schwer wird, aber ich hoffe dass ich nicht ausversehen über die stränge schlage.
matomo (früher™ piwik) läuft hier mehr oder weniger seit 15 jahren. man sieht in der jährlichen zusammenfassung der besucher („unique visitors“), dass dieses blog seine beste zeit schon lange hinter sich hat. erstaunlich ist aber dass in der zeit von 2021 bis 2024 noch so viele besucher kamen, obwohl hier 5 jahre mehr oder weniger nichts passiert ist.
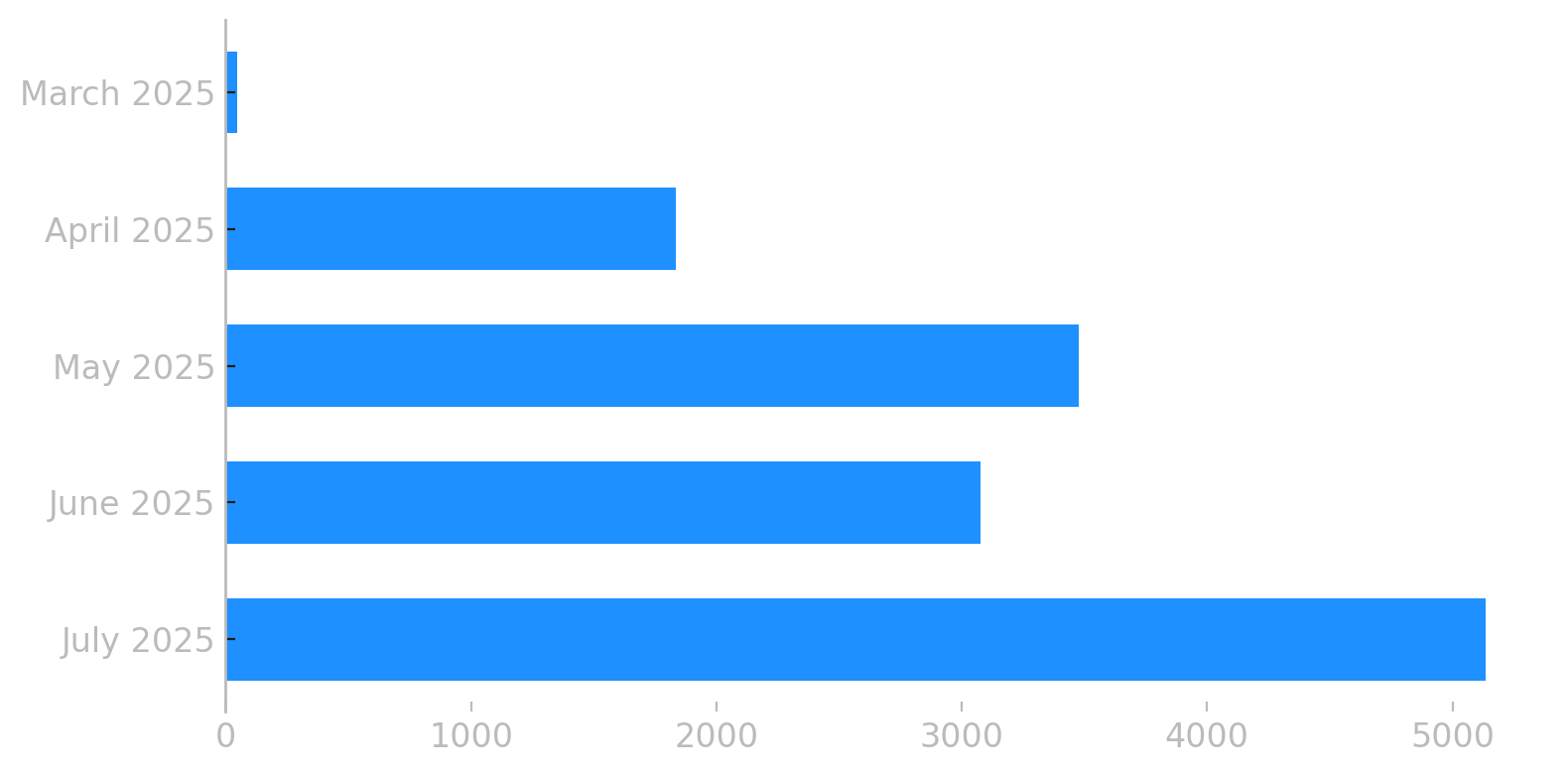
immerhin geht es seit april wieder leicht, aber stetig, aufwärts.
der beitrag („wut gegen die maschine“) ist klassisches blog-material und wäre wunderbar auf spreeblick.de aufgehoben gewesen. statt ins eigene blog, schreibt johnny in das silo eines amerikanischen konzerns, der auch kein problem damit hat nazi-inhalte zu dulden und gelegentlich zu promoten (in ←diesem fall angeblich ausversehen; mehr zu substack und deren nazi-problem bei ingrid broding).
johnny ist sich dessen natürlich bewusst und schreibt in seinem oben verlinkten beitrag:
[…] noch bevor ich mit diesem Newsletter endlich wie seit langer Zeit geplant von Substack zu Ghost / Magic Pages wechsle […]
über ghost bin ich in den letzten wochen gelegentlich gestolpert und bin positiv angetan. gerade wurde wohl version 6 veröffentlicht, die tolle, neidisch machende features beinhaltet.
im blog — oder ghost? — des gründers john o’nolan habe ich mich in den letzten tagen ein bisschen festgelesen und lust bekommen ghost auch mal auszuprobieren. so kann eine ghost instanz auch gleichzeitig eine mastodon-instanz sein, so wie john.onolan.org es ist. ghost selbst kann man sich selbst installieren oder eine gehostete instanz mieten. das finanzierungsmodel hinter ghost ist vernünftig und vertrauensbildend, ghost instanzen benötigen nicht unbedingt ein cookie banner und können tracker-frei betrieben werden. alles was an substack scheisse ist, ist bei ghost toll.
je länger ich ins internet schreibe, desto deutlicher ist mir geworden wie wichtig es ist entweder auf selbst kontrolleirten plattformen zu schreiben oder mindestens einen fluchtweg vorzubereiten, wenn drittanbieter plattformen der enshittification erliegen (verkacken). das gilt selbst für das fediverse; seitdem ich meine eigene gotosocial-instanz betreibe fühle ich mich noch einen tacken mehr in kontrolle. dabei geht es natürlich nicht in erster linie um kontrolle, die ja bekanntermassen meist eine illusion ist, sondern eben um abwesenheit oder reduzierung von abhängigkeiten.
ich werde mich jedenfalls hüten johnny ghost oder andere vermeintliche, halbgare weisheiten aufs auge zu drücken, er wird da schon selbst seine abwägungen gemacht haben. aber auf den ersten und zweiten blick hat mich das teil so neugierig gemacht, dass ich mir das sicher mal anschauen werde. vielleicht lässt sich da ja was integrieren, zwischen kirby und ghost. oder einfach das eine oder andere lernen.
so richtig überzeugt davon wirres.net auch per push (newsletter) zu verteilen bin ich nach wie vor nicht. aber die wurzeln dieses blogs sind eigentlich ein newsletter. damals (2001 / 2002) gab es bei yahoogroups die möglichkeit sowas einfach einzurichten: abonnenten eintragen, email schreiben, an wirres@yahoogroups.com schicken, fertig. so habe ich damals familie und freunde über meine aktivitäten informiert, bis in mir die erkenntnis reifte, dass pull besser als push ist, dass ich mich also lieber auf eine webseite mit neuigkeiten konzentrieren sollte, statt neuigkeiten in briefkästen zu werfen. ich bin mir heute nicht mehr sicher, ob ich solche botschaften, wie hier im märz 2002 auch an meine eltern geschickt habe. obwohl diese rundmail vom august 2002 eltern-safe gewesen wäre. komischerweise habe ich mir damals nie die mühe gemacht die vöslauer mail in einen richtigen artikel umzuwandeln, nur das follow-up hat einen artikel bekommen.
ich ziehe es nicht ernsthaft in erwägung, aber fragen ob irgendwer interesse am vertrieb von wirres.net als newsletter habe kann ich ja mal.
heute gabs ne butterbrezel zum frühstück, die brezel hab ich gestern schon gekauft und die butter hab ich extra ausgefroren. dazu ne scheibe käse und gekochten schinken. nach dem frühstück gab nur nen kurzen „mittags“-schlaf weil ich am flughafen meinen alten freund jeff abholen musste, den ich seit 38 jahren nicht mehr gesehen hatte. jeff und ich waren damals im wrestling team der highschool. wir haben uns vor der abholung gegenseitig fotos von uns geschickt, was im ersten moment hilfreich war, in 38 jahren altert man ja erheblich und sammelt fett, aber im laufe des tages haben wir gegenseitig die 18 jährigen in unseren gealterten gesichtern wiedererkannt.
auf der rückfahrt sind wir von der autobahn abgefahren und haben irgendwo in kreuzberg angehalten um eine gelegenheit zu suchen jeff mit döner bekannt zu machen. dieser laden schien uns gut genug, und auch wenn die zwei döner mit zwei ayran 17 € kosteten waren wir nicht entäuscht. das ayran schmeckte jeff ein bisschen zu „special“, aber ich bin zuversichtlich, dass er sich noch an ein paar acquired german tastes rantasten wird.
das döner befügelte jeff nach dem essen offensichtlich
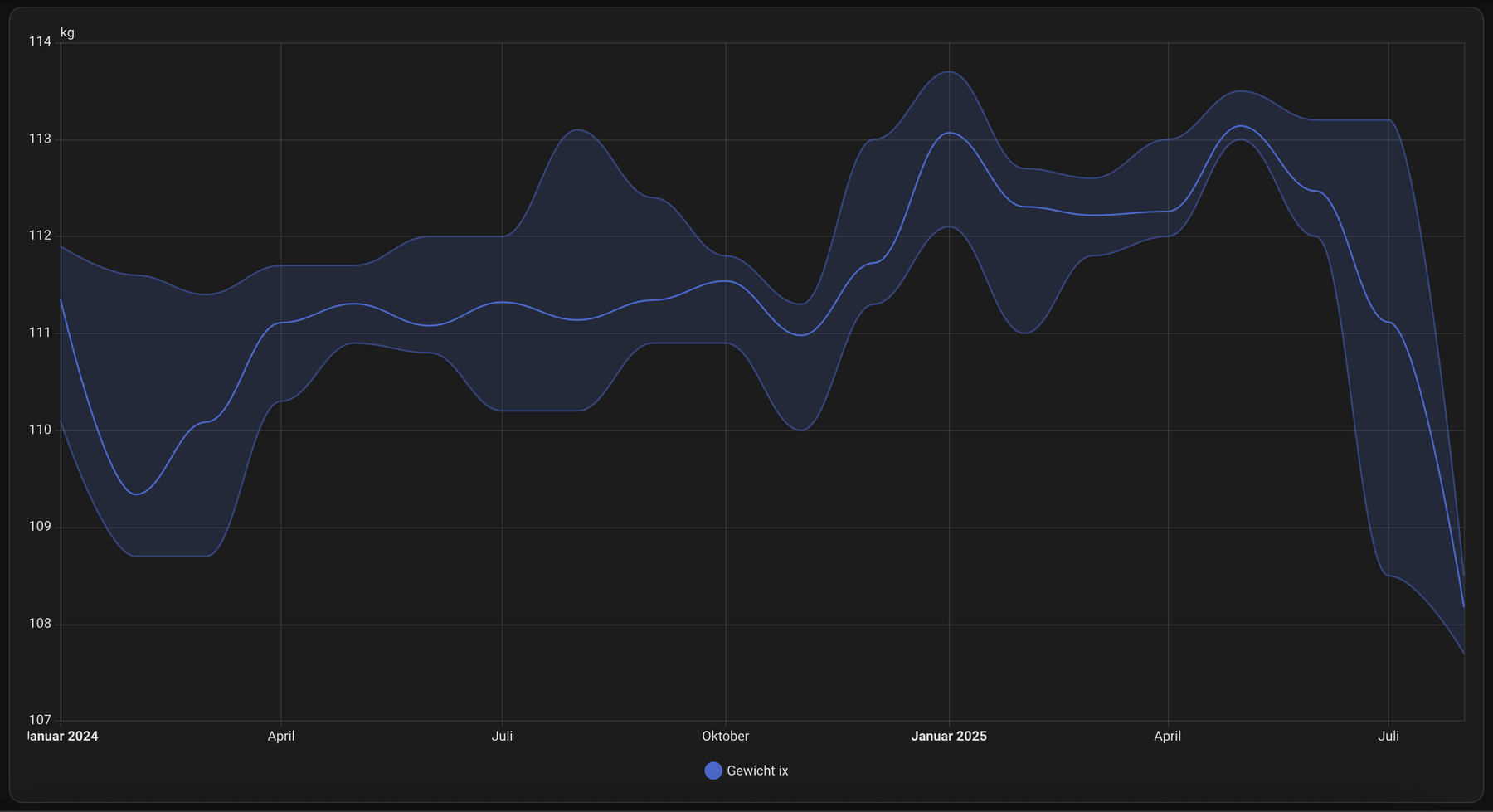
ich hatte mir im vorfeld ohnehin überlegt heute mal ein bisschen mehr zu essen als mir der appetit das semaglutid diktierte, weil die pfunde laut waage gerade etwas zu flott fallen (heute bereits unter 108). am abend gabs dann eine proper german brotzeit, für mich reichte eine scheibe vollkornbrot mit käse und schinken, zwei bier und sehr viele frische rettichscheiben mit salz und pfeffer. morgen gibt’s kuchen von thoben, jeff und die beifahrerin haben von jeder thoben sorte kuchen je ein stück gekauft. ich konnte den beiden ausreden den kuchen nach dem abendessen anzubrechen, aber ich freu mich sehr auf die kuchenaussicht morgen.
ausserdem kurz aus dem maschinenraum: gestern und heute früh habe ich an einer gitter-darstellung der bilder auf wirres.net gearbeitet, mit photoswipe, infinite scroll und so wie ich mir ein fotoarchiv schon länger vorgestellt habe. das zielpublikum dieses neuen features (ich) ist sehr zufrieden, auch wenn das ding noch einiges an feinschliff benötigt.

















{kind=link}
{kind=link}